TCP 设计¶
可靠递送单个 Packet¶
packet 从 sender 到接收方所花的时间称为 one-way delay。packet 从 sender 到接收方,再加上一个回复 packet 从接收方返回 sender 所花的时间,称为 round-trip time (RTT)。
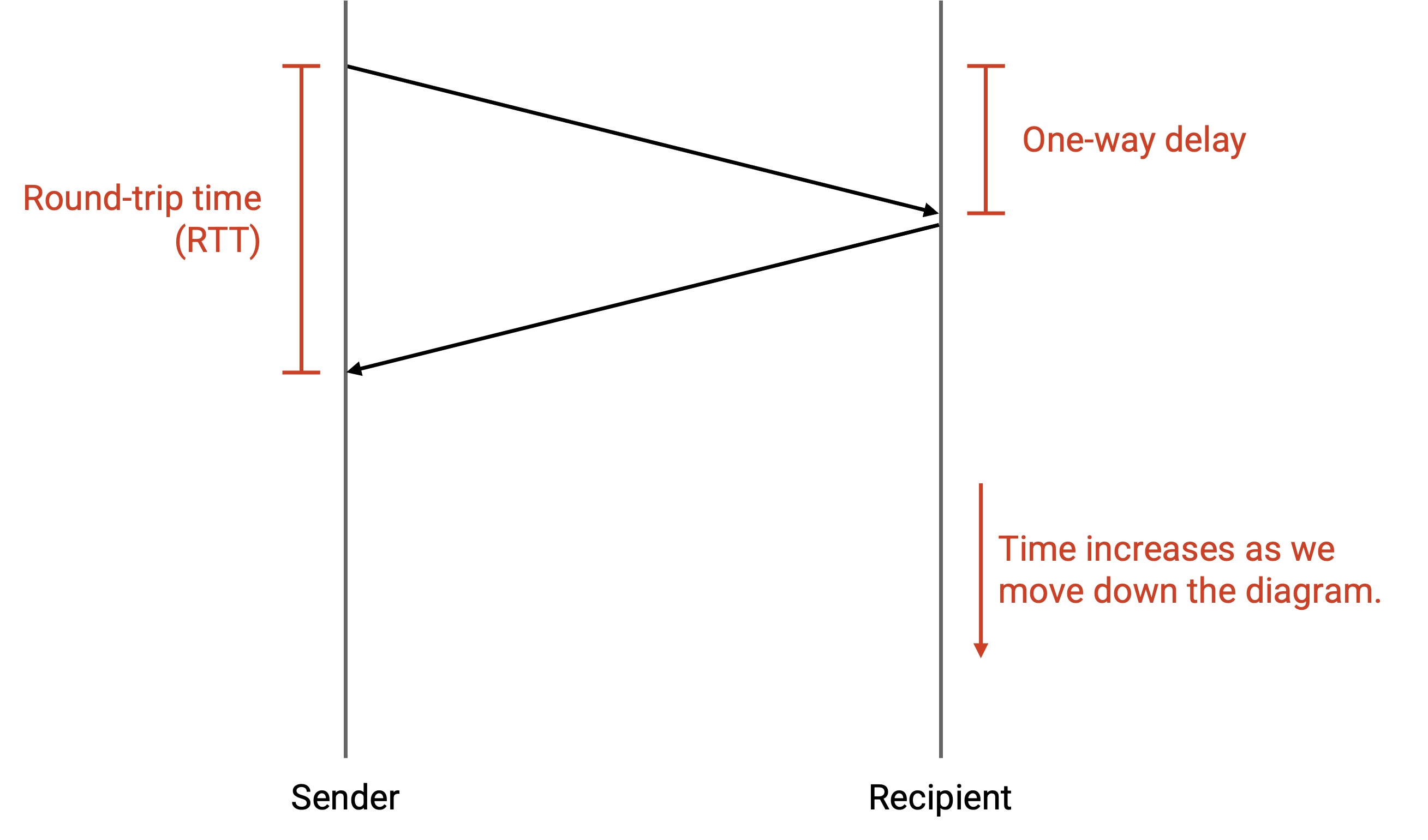
我们先设计一个用于可靠发送单个 packet 的简化 protocol,以此建立直觉。
sender 尝试发送一个 packet。sender 怎么知道这个 packet 是否已经被成功接收?
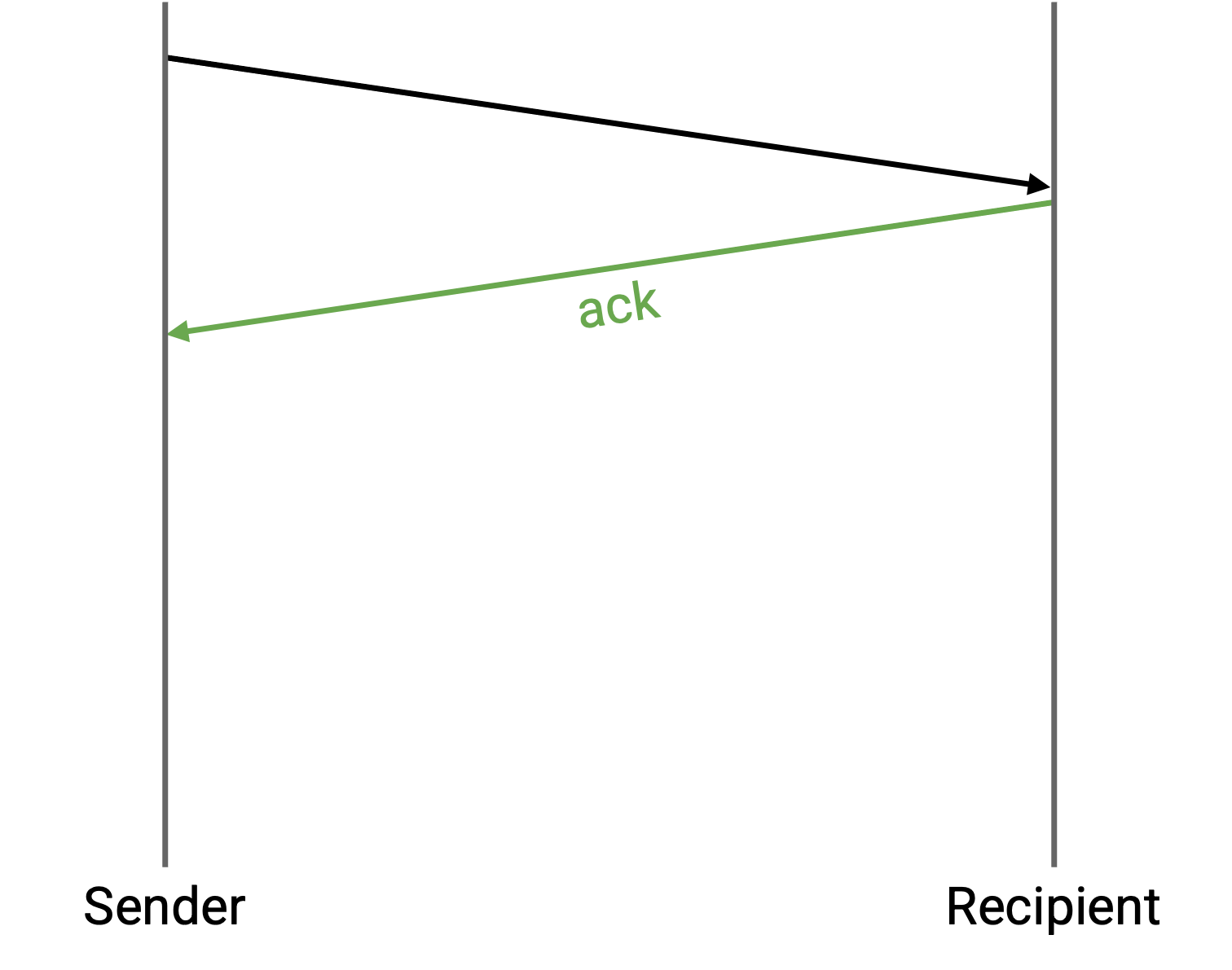
接收方可以发送一个 acknowledgement (ack) 消息,确认已经收到这个 packet。
如果 packet 被丢弃,会发生什么?
如果 packet 被丢弃,我们可以重发它。那我们怎么知道什么时候应该重发?
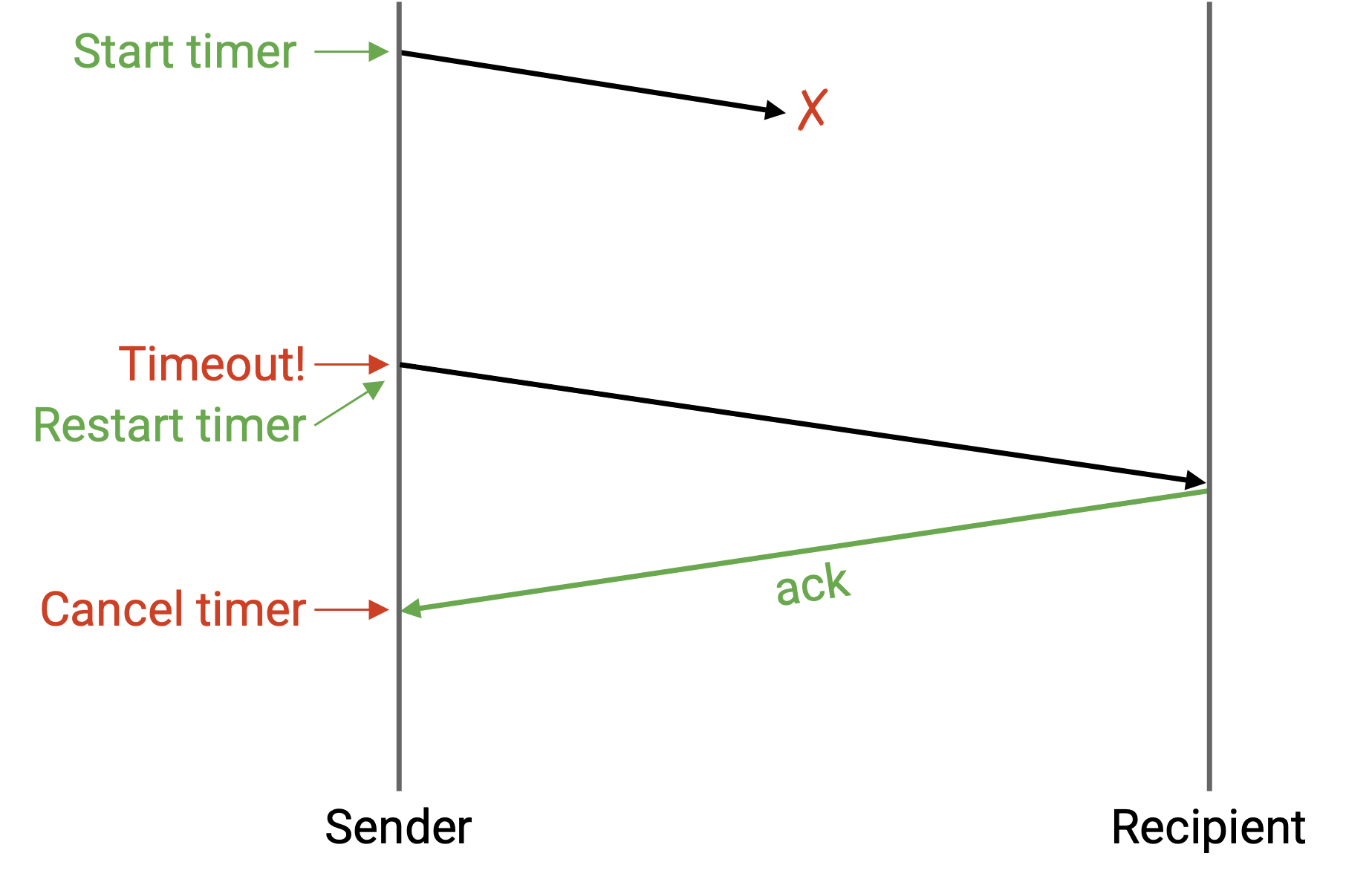
sender 可以维护一个 timer。当 timer 过期时,我们就可以重发这个 packet。
当 sender 收到 ack 时,sender 可以取消 timer,并且不需要重发 packet。
如果 ack 被丢弃,会发生什么?
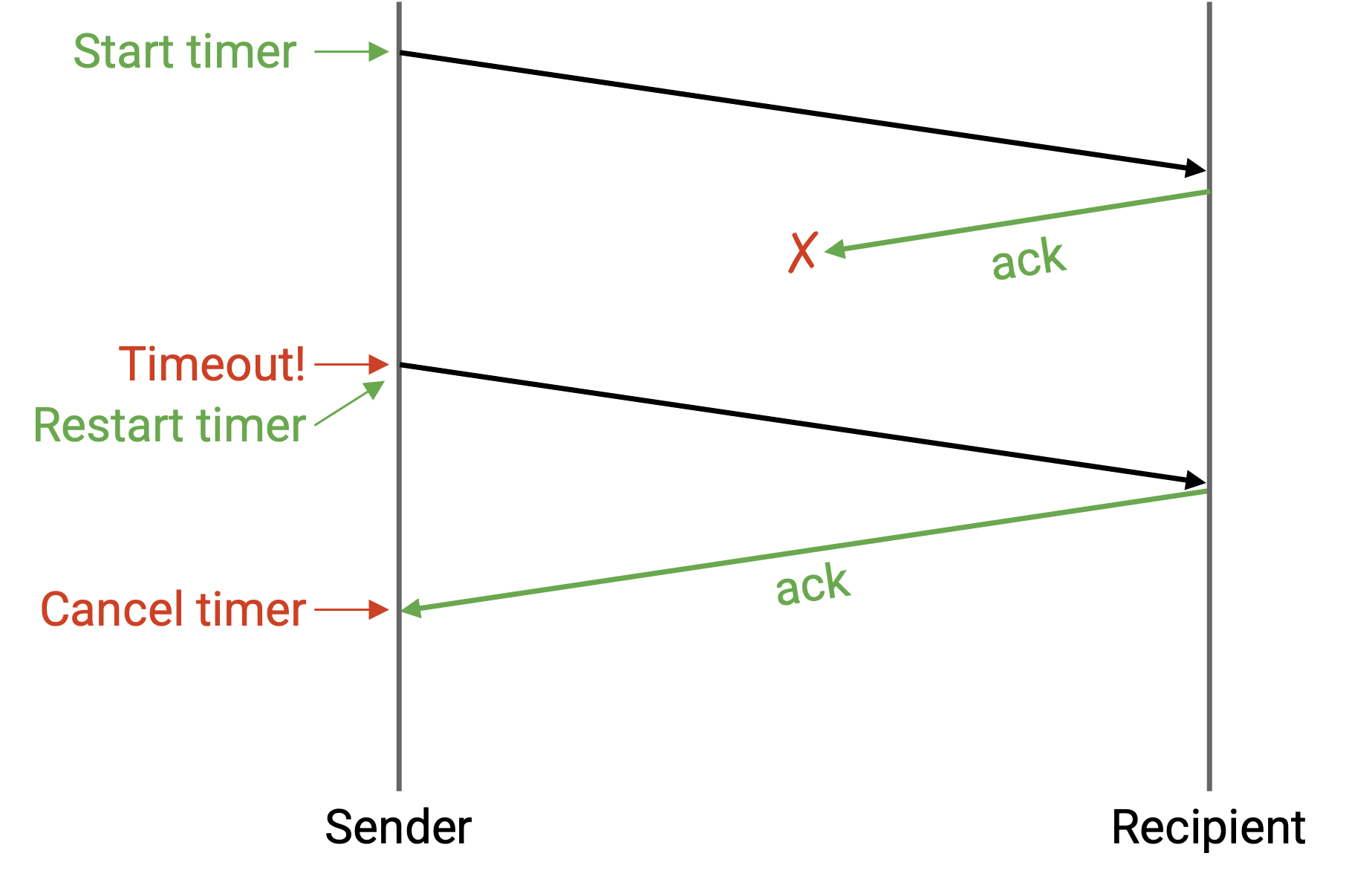
这个 protocol 不需要修改也仍然可用。sender 会超时(没有收到 ack),并持续重发 packet,直到 ack 成功发回。在这种情况下,目的地收到了同一个 packet 的两个副本,但这没关系。目的地可以发现重复副本并丢弃它。
timer 应该怎么设置?如果 timer 太长,packet 的发送可能花费超过必要的时间。如果 timer 太短,packet 可能在不需要重发时被重发。timer 设置不当会影响我们的效率目标。
合适的 timer 长度是 round-trip time。这是 sender 预期收到 ack 的时间,所以如果到那时 ack 还没有到达,sender 就应该重发 packet。
在实践中,估计 RTT 可能很困难。RTT 会随 packet 在网络中选择的路径而变化;即使在某条具体路径上,RTT 也会受到该路径负载和 congestion 的影响。
估计 RTT 的一种方法,是测量发送某个 packet 到收到该 packet 的 ack 之间的时间。每发送一个 packet,我们都可以得到一次估计 RTT 的测量值,然后用某种算法(例如 exponential moving average)把这些测量值合并成一个 RTT 估计值。我们的算法还必须处理消息被重发带来的影响(测量值中的方差)。
在实践中,运营者通常倾向于把 timer 设得更长一些。如果 timer 太短,导致不断发生 timeout,那么你的 connection 很可能表现很差(一直在重发 packet)。
如果 bit 损坏,会发生什么?
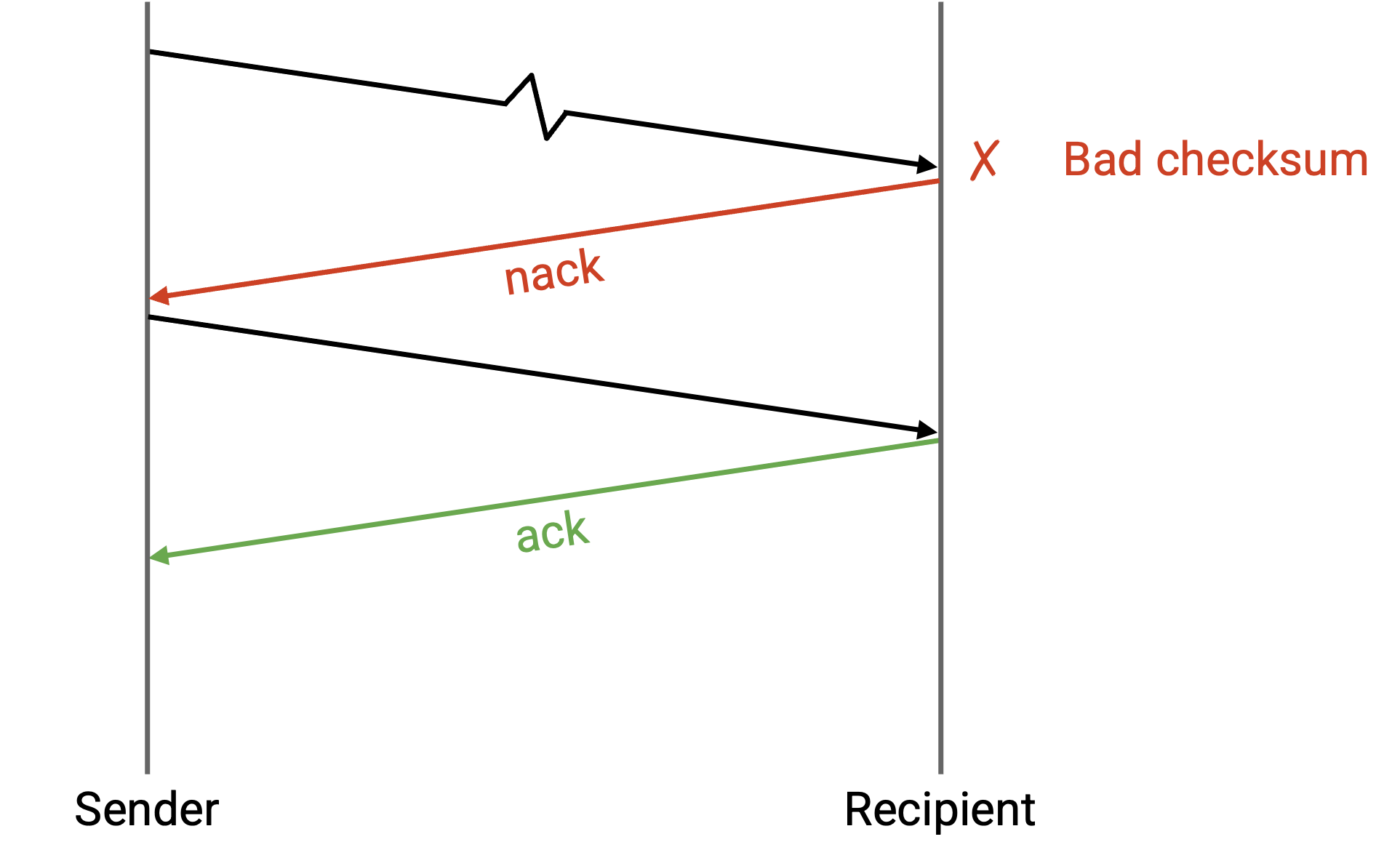
我们可以在 transport layer header 中加入 checksum(不同于 IP layer checksum)。当接收方看到损坏的 packet 时,它可以做两件事之一:接收方可以显式重发一个 negative acknowledgement (nack),告诉 sender 重发这个 packet。
或者,接收方可以丢弃损坏的 packet,并且什么也不做(不发送 ack 或 nack)。然后,sender 会超时并重发 packet。
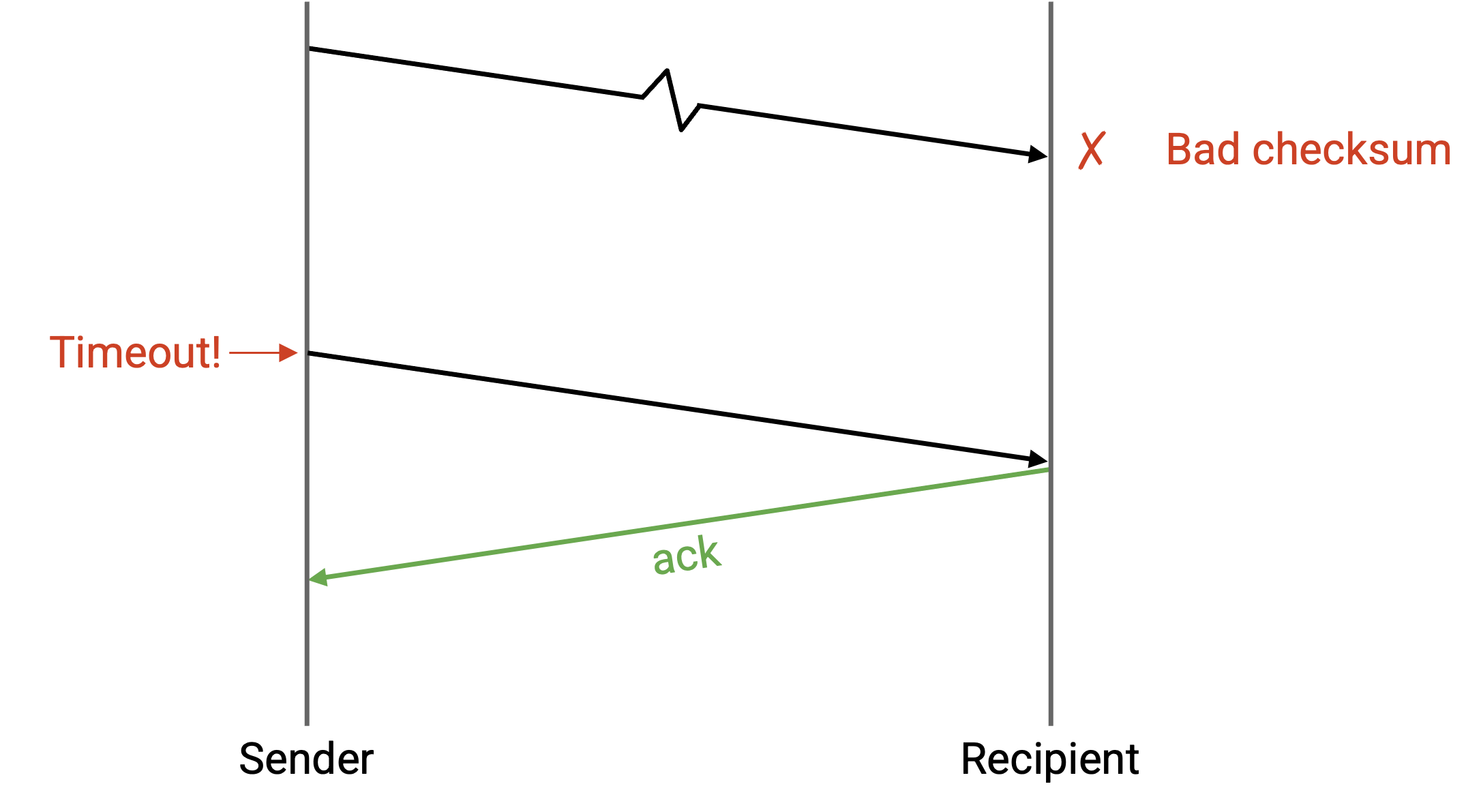
两种方法(nack 或等待 timeout)都可行,不过 TCP 使用后一种方法(等待 timeout),并不实现 nack。
如果 packet 被延迟,会发生什么?
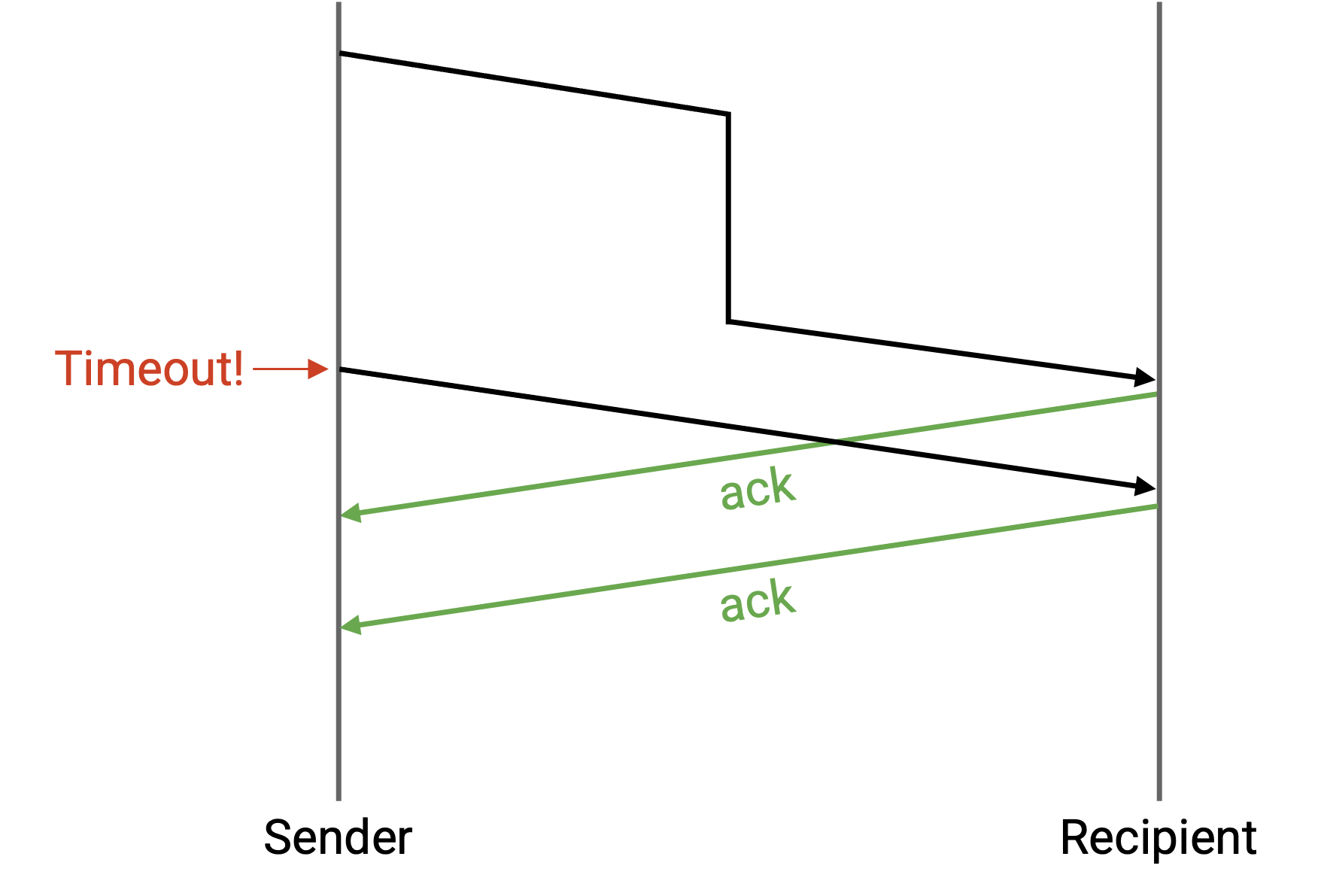
不需要修改。如果延迟非常长,sender 可能在 ack 到达之前超时。sender 会重发 packet(所以 recipient 可能收到两个重复副本),sender 也可能收到两个 ack,但这没关系。
如果 sender 发送一个 packet,但它在网络中被复制,recipient 收到两个副本,会发生什么?
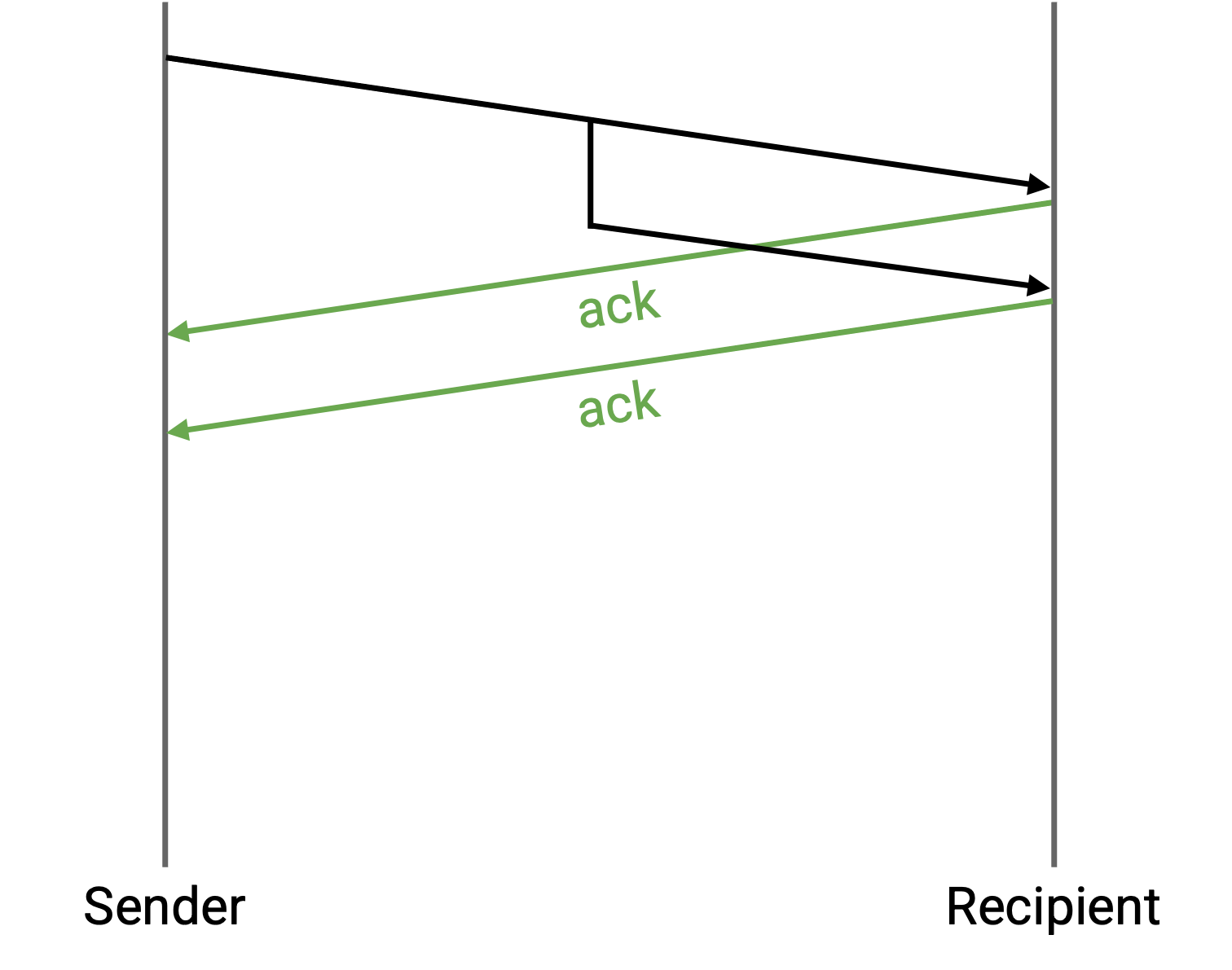
不需要修改。recipient 会发送两个 ack,但 sender 和 recipient 都可以安全地处理重复副本。
注意:从这个简化 protocol 中我们可以看到,recipient 有时会收到同一个 packet 的两个副本。如果某条具体 link 正在实现可靠性 protocol,那么这条 link 的接收端可能收到两个副本。通常,重复副本会被丢弃,只有一个 packet 会被转发到目的地。但是,如果 router 在两个副本到达之间崩溃并重启,router 可能会把两个副本都转发到目的地。
总结一下,单个 packet 的可靠性 protocol 是:
如果你是 sender:发送 packet,并设置 timer。如果 timer 触发之前没有 ack 到达,就重发 packet 并重置 timer。当 ack 到达时停止并取消 timer。
如果你是 recipient:如果收到未损坏的 packet,就发送 ack。(如果多次收到这个 packet,你可能会发送多个 ack。)
这个例子中的核心思想也会用于后续 protocol:checksum(用于检测损坏)、acknowledgement、重发 packet 和 timeout。
注意,这个 protocol 保证 at-least-once delivery,因为可能存在重复副本。
可靠递送多个 Packet¶
如何把这个 protocol 扩展到多个 packet?
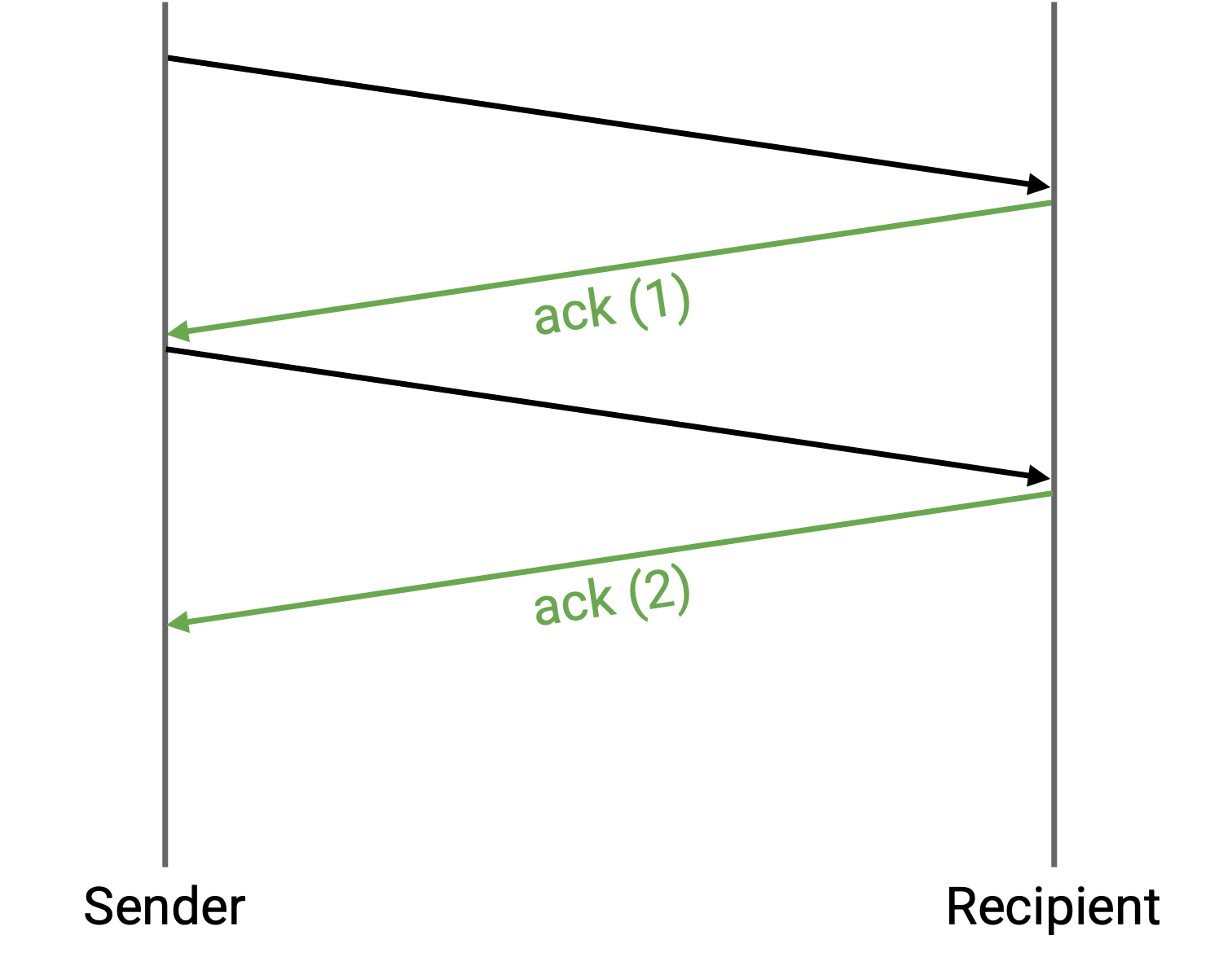
我们可以对每一个 packet 遵循相同的传输规则(timer 过期时重发)。为了区分 packet,我们可以给每个 packet 附加唯一的 sequence number。每个 ack 都会关联到某个具体 packet。如果 packet 乱序到达,sequence number 也能帮助我们重新排序。
sender 什么时候发送每个 packet?最简单的方法是 stop and wait protocol:sender 等待 packet i 被确认之后,再发送 packet i+1。这可以正确提供可靠性,但非常慢。每个 packet 至少需要一个 RTT 才能发送完成(如果 packet 被丢弃或损坏,还会更久)。
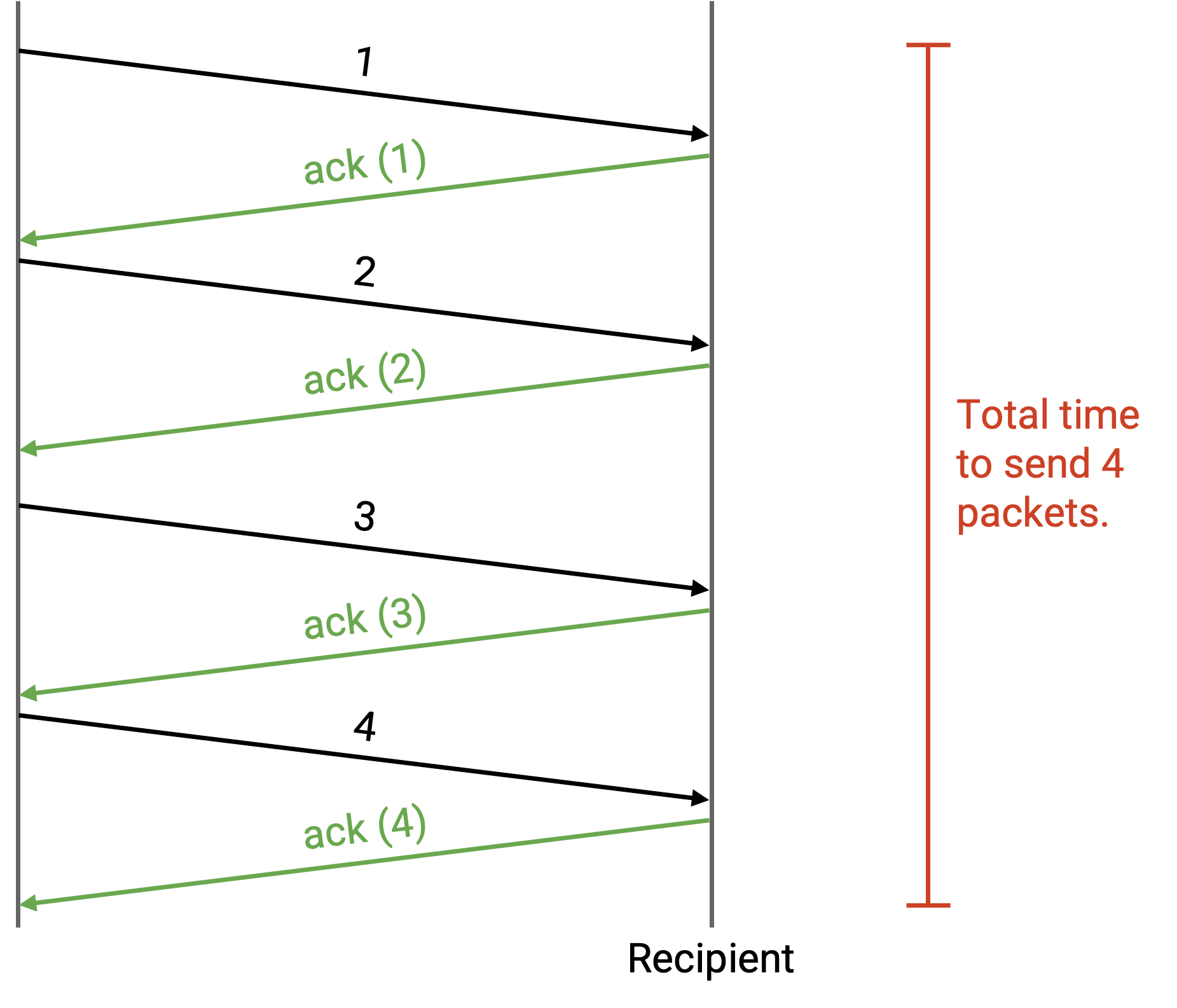
在效率不那么重要的小规模场景中,这个 protocol 也许能用,但对 Internet 来说太慢了。我们怎样才能让它更快?
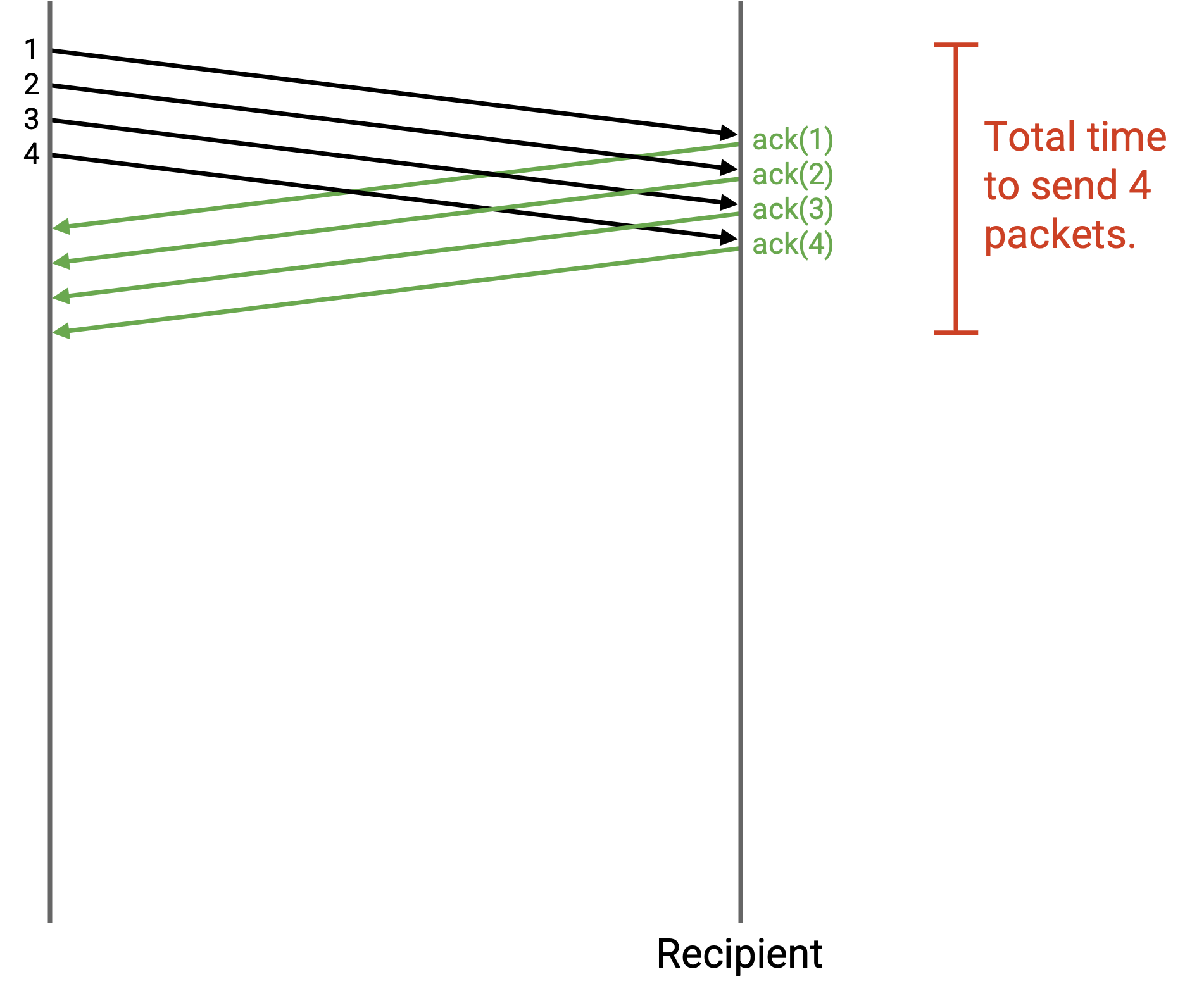
我们可以并行发送 packet。更具体地说,我们可以在等待 ack 到达时继续发送更多 packet。当某个 packet 已经被发送,但对应 ack 尚未收到时,我们称这个 packet in flight。
最简单的方法是立即发送所有 packet,但这可能会压垮网络,例如连接到你计算机的 link 可能带宽有限。
基于 Window 的算法¶
一次只发送一个 packet 太慢,但一次发送所有 packet 又会压垮网络。为了解决这个问题,我们设置一个限制 W,并规定任意时刻最多只能有 W 个 packet 处于 in flight 状态。这就是 window-based protocol 的关键思想,其中 W 是 window size。
如果 W 是 in-flight packet 的最大数量,那么 sender 可以一开始发送 W 个 packet。每当一个 ack 到达,我们就发送队列中的下一个 packet。
W 应该怎么选择?
我们希望充分使用可用的网络容量(「fill the pipe」)。如果 W 太低,我们就没有用完可用带宽。
不过,我们也不希望让 link 过载,因为其他人也可能正在使用这条 link(congestion control)。我们也不希望让接收方过载,因为接收方需要接收并处理 sender 发来的所有 packet(flow control)。
Window Size:填满管道¶
我们先只关注第一个 RTT,也就是从第一个 packet 发出,到第一个 ack 到达之间的时间。假设这段时间是 5 秒(这个数字不现实,只是举例)。再假设 outgoing link 允许 sender 每秒发送 10 个 packet(同样只是举例)。那么在第一个 RTT 期间,sender 总共应该能发送 50 个 packet。因此,50 是一个合理的 window size,这样 sender 就会一直发送 packet,而不会空闲等待。
如果我们把 W 设得低于 50,那么 sender 会在第一个 ack 到达之前就发完所有初始 packet。之后,sender 被迫空闲等待 ack 到达,一部分网络带宽就会被浪费。更一般地说,我们希望 sender 在整个 RTT 期间都在发送 packet。
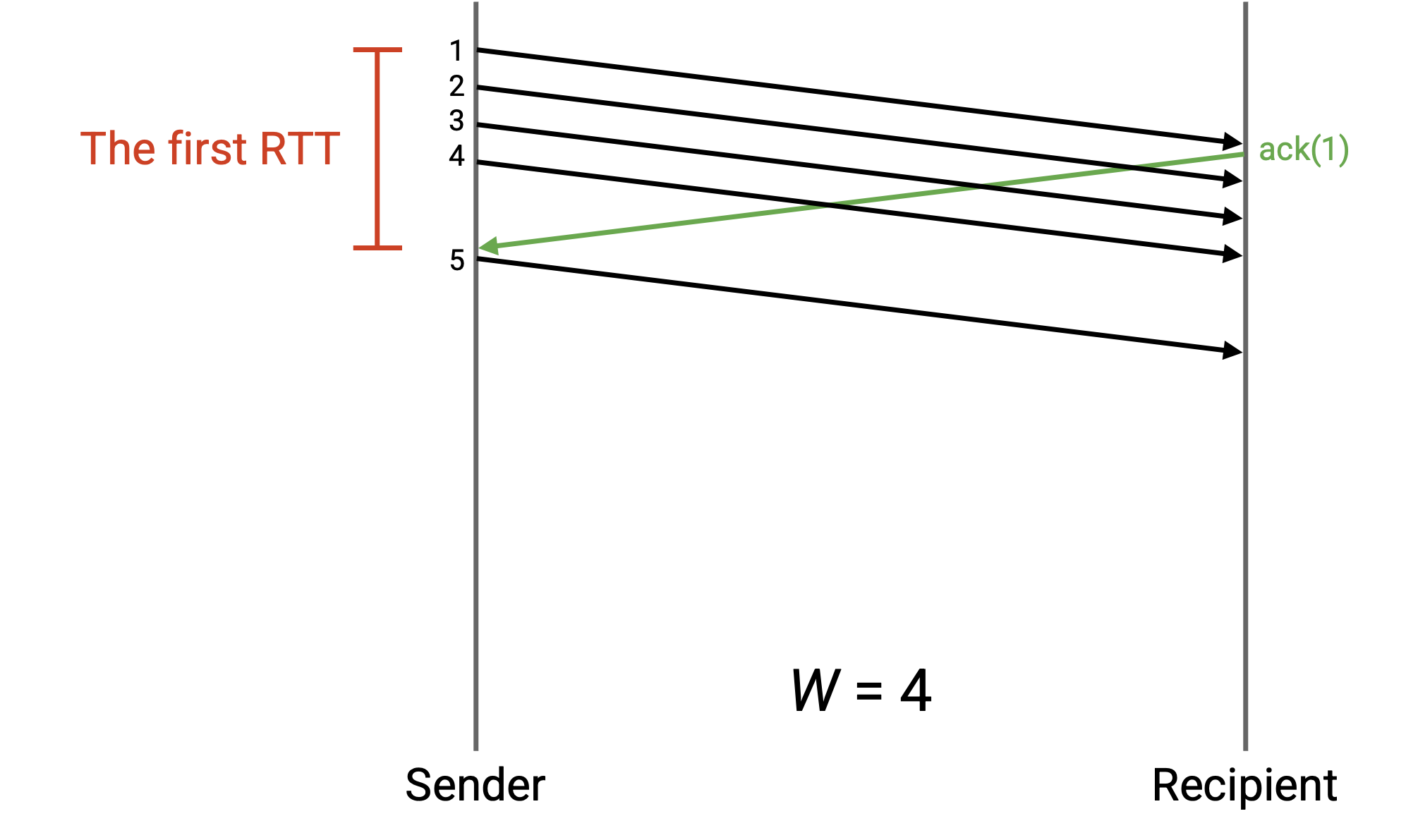
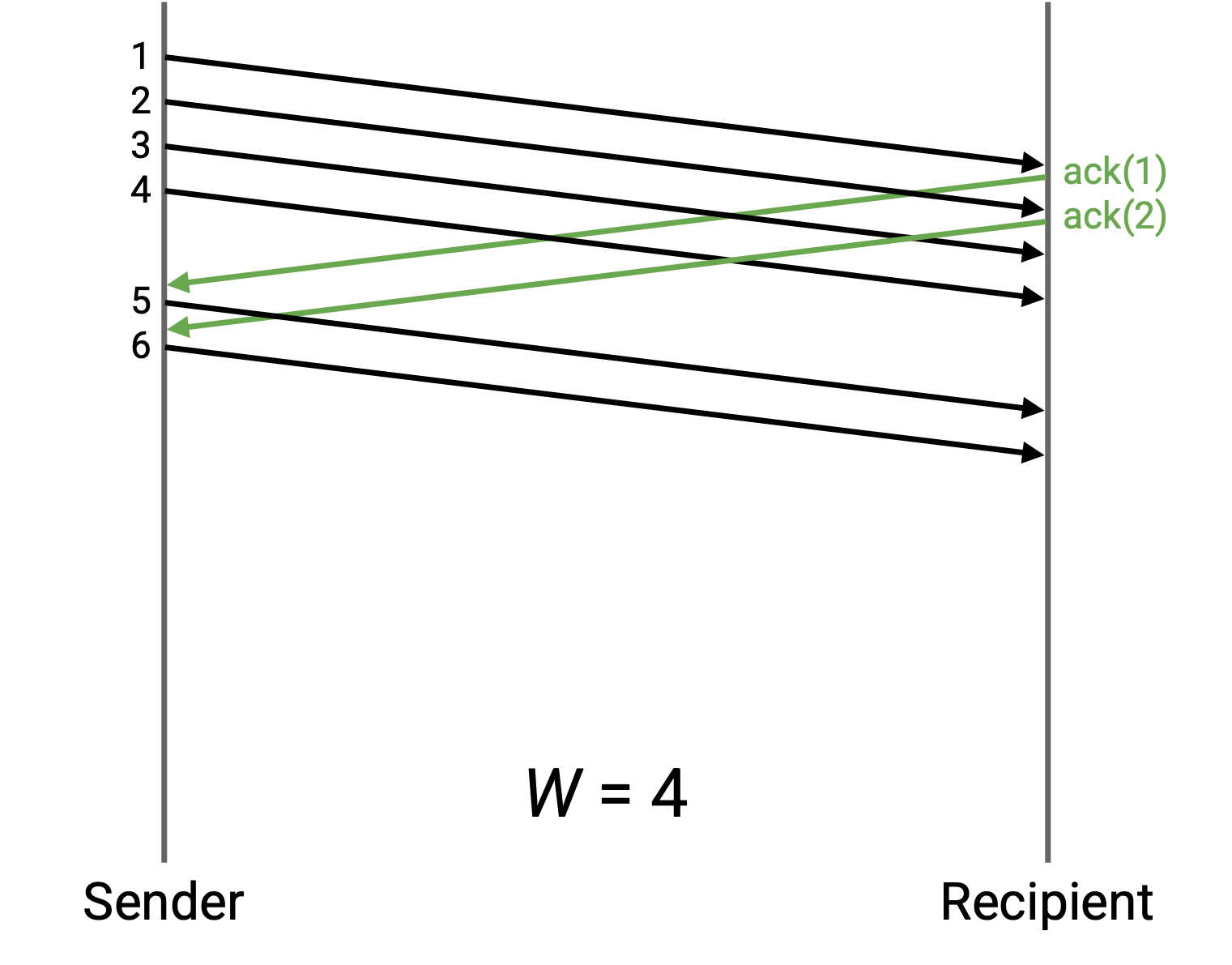
在这个例子中,W 是 4。但是,sender 发送 4 个 packet 后就开始空闲,一边等待第一个 ack 到达,一边浪费带宽。
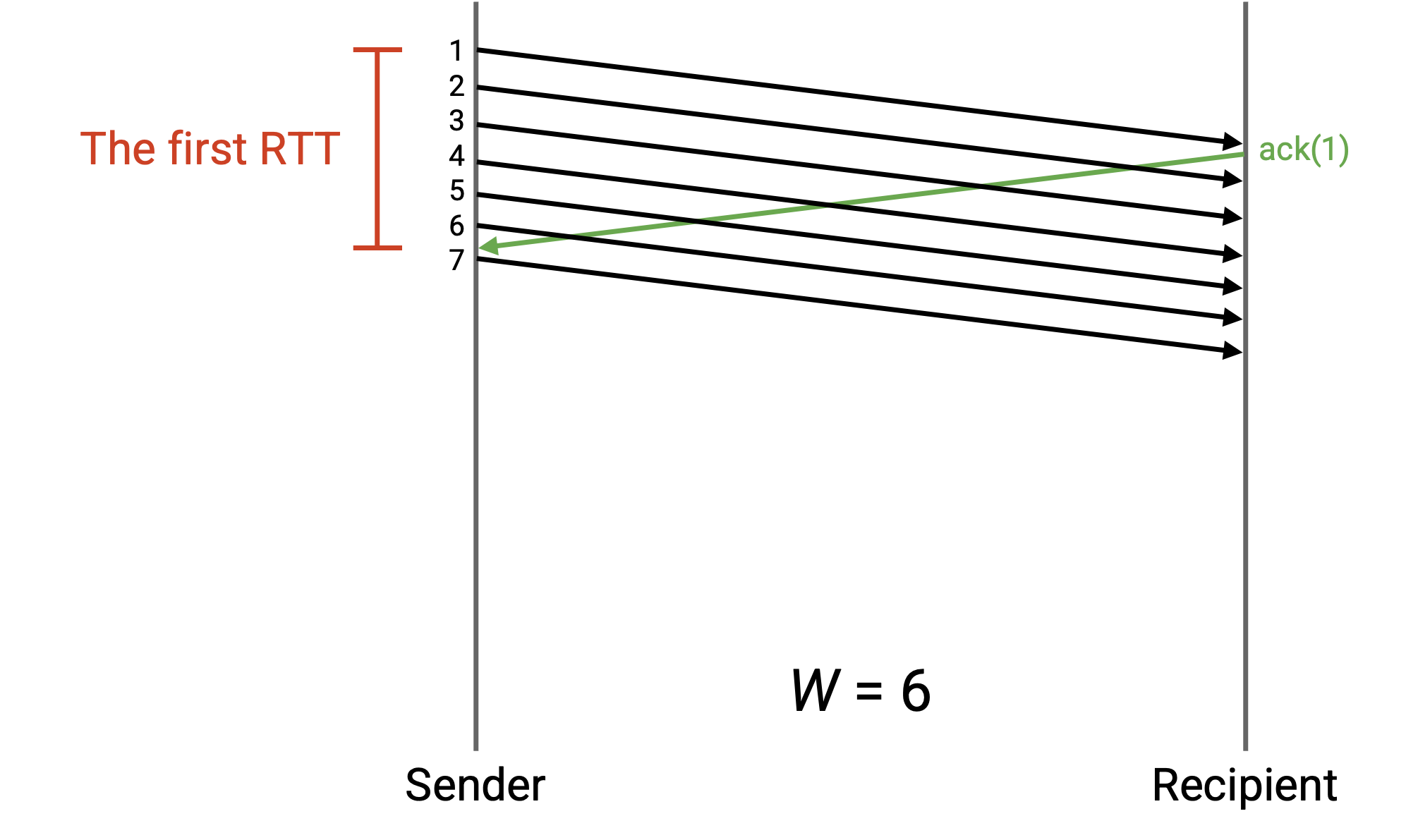
在这个例子中,W 被增大,使 sender 可以持续发送 packet。当第一个 ack 到达时,sender 正好快要达到 W 个 in-flight packet 的限制,并且可以在更多 ack 到达时立即继续发送 packet。
到目的地的 route 可能包含多条 link,它们的容量不同。令 B 为路径上的最小(瓶颈)link 带宽。为了避免让 link 过载,我们不应该以快于 B 的速度发送 packet。同时,我们也不希望发送速度低于 B,也就是说,我们希望始终使用速率 B。
另外,假设 R 是 sender 和 recipient 之间的 round-trip time。我们可以用 R 乘以 B,得到 RTT 期间可以发送的 packet 总数。(我们可以每秒发送 B 个 packet,持续 R 秒。)这会告诉我们以 packet 为单位的 window size。
现实中,B 的单位是 bit/second,而不是 packet/second。当我们用 R 乘以 B 时,得到的是 RTT 期间可以发送的 bit 数。(每秒 B bit,持续 R 秒。)这会告诉我们以 byte 为单位的 window size。总之,我们可以写成:
W times packet size = R times B
左边表示 window 期间发送的 byte 数(W 个 packet 乘以每个 packet 的 byte 数),右边表示 RTT 期间可以发送的 byte 数。
举一个具体例子,设 RTT = 1 秒,B = 8 Mbits/second。那么 R times B 是 8 Mbits,也就是 1 megabyte,或者 1,000,000 bytes。
如果 packet size 是 100 bytes,那么我们希望 W = 10,000 packets,这样就能充分使用带宽,并在 RTT 期间发送 1,000,000 bytes。
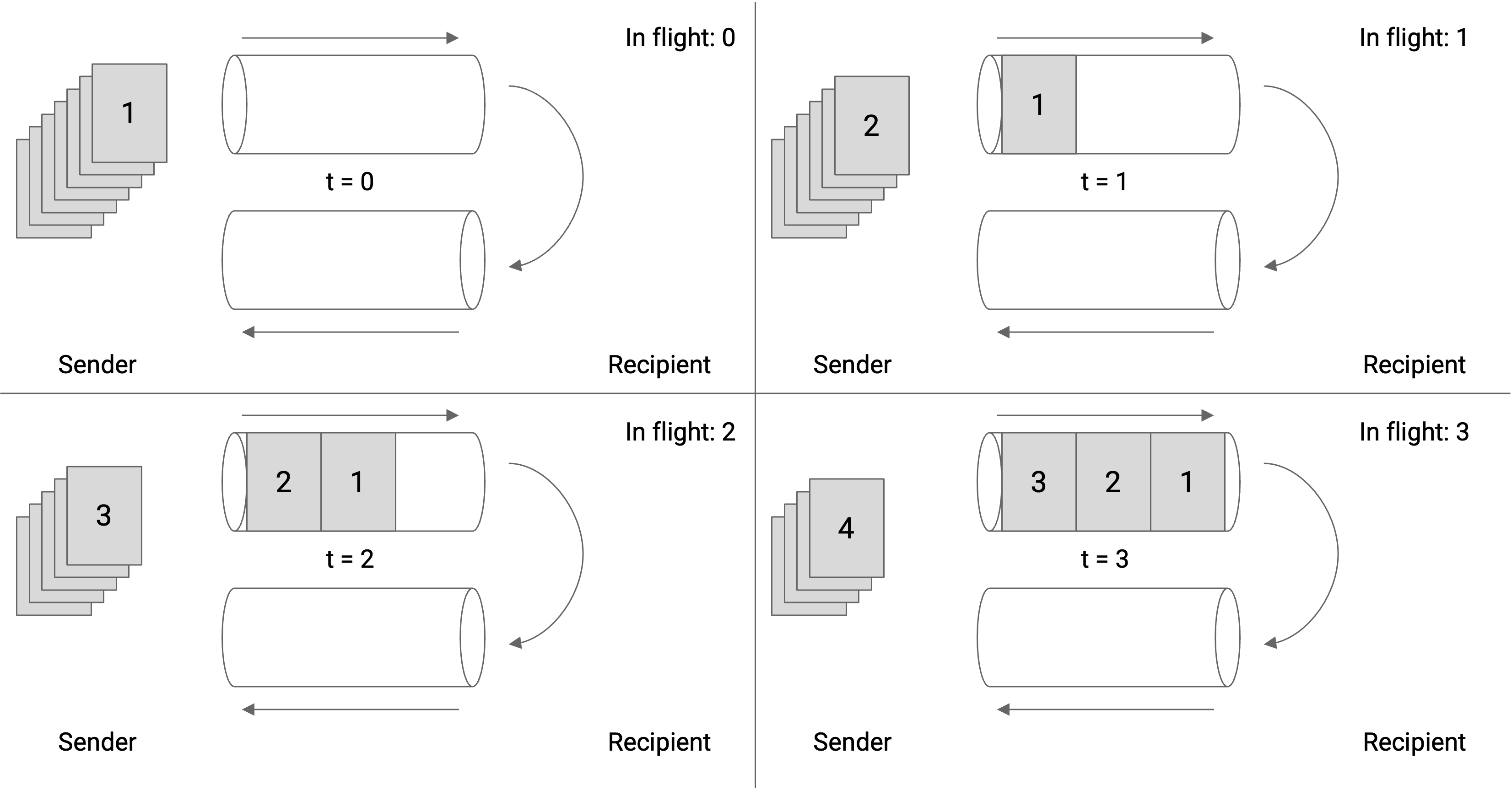
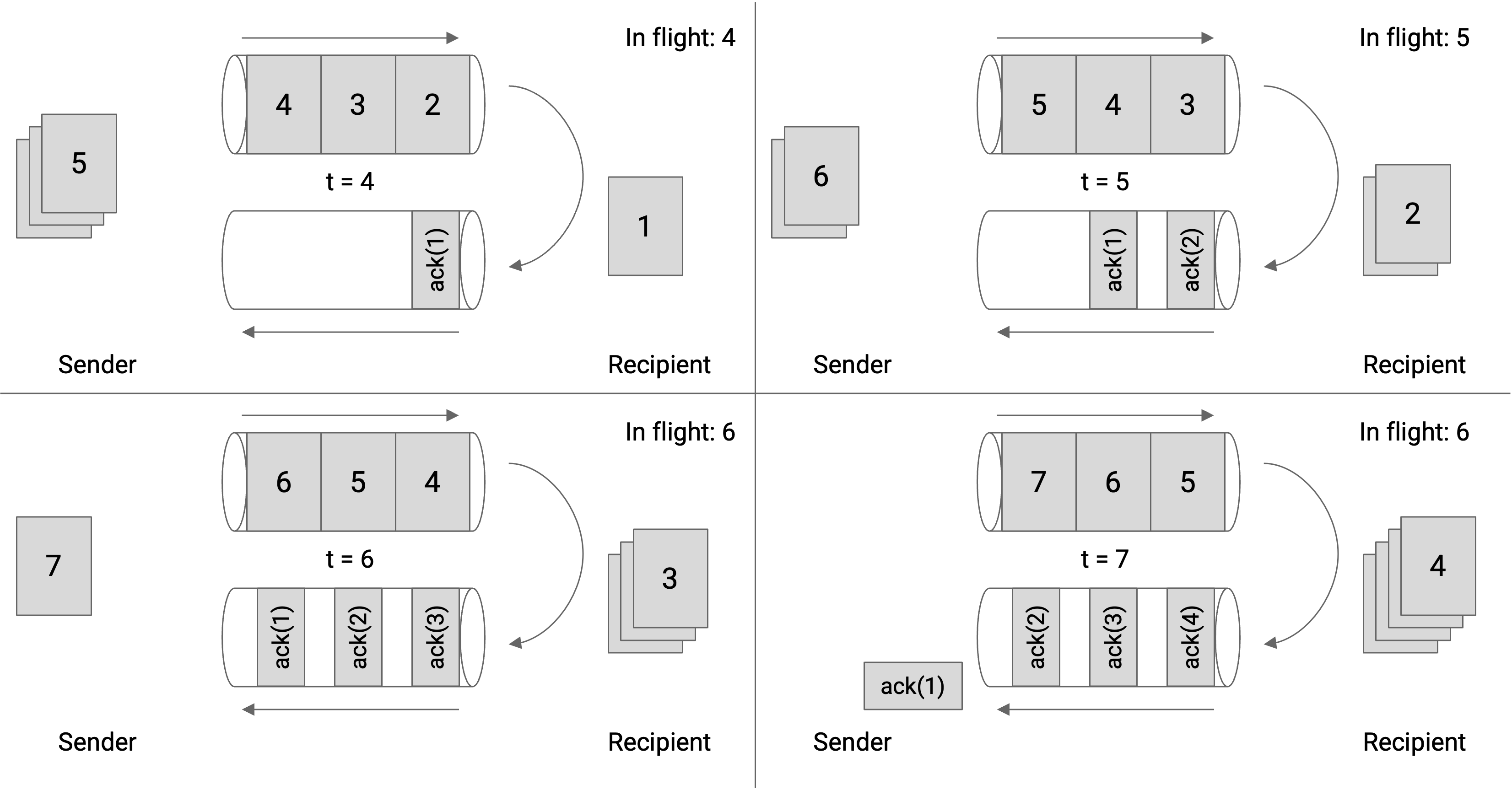
我们也可以从 link 本身的角度画出 window size。在这张图中,我们展示的是某条具体 link 的 outgoing 和 incoming 方向。当 sender 以最大容量把 packet 推过 link 时,第 6 个 packet 发出后,第一个 ack 会立刻到达。因此,我们的 window size 应该是 6。
注意,window size 不是 3。当 packet 6 被发送时,有 3 个 packet 正在发送,但还有另外 3 个 packet 的 ack 尚未到达,所以总共有 6 个 packet in flight。
如果把 window size 设为 3,那么当 1、2、3 的 ack 还在返回途中时,outgoing pipe 就会处于未使用状态。
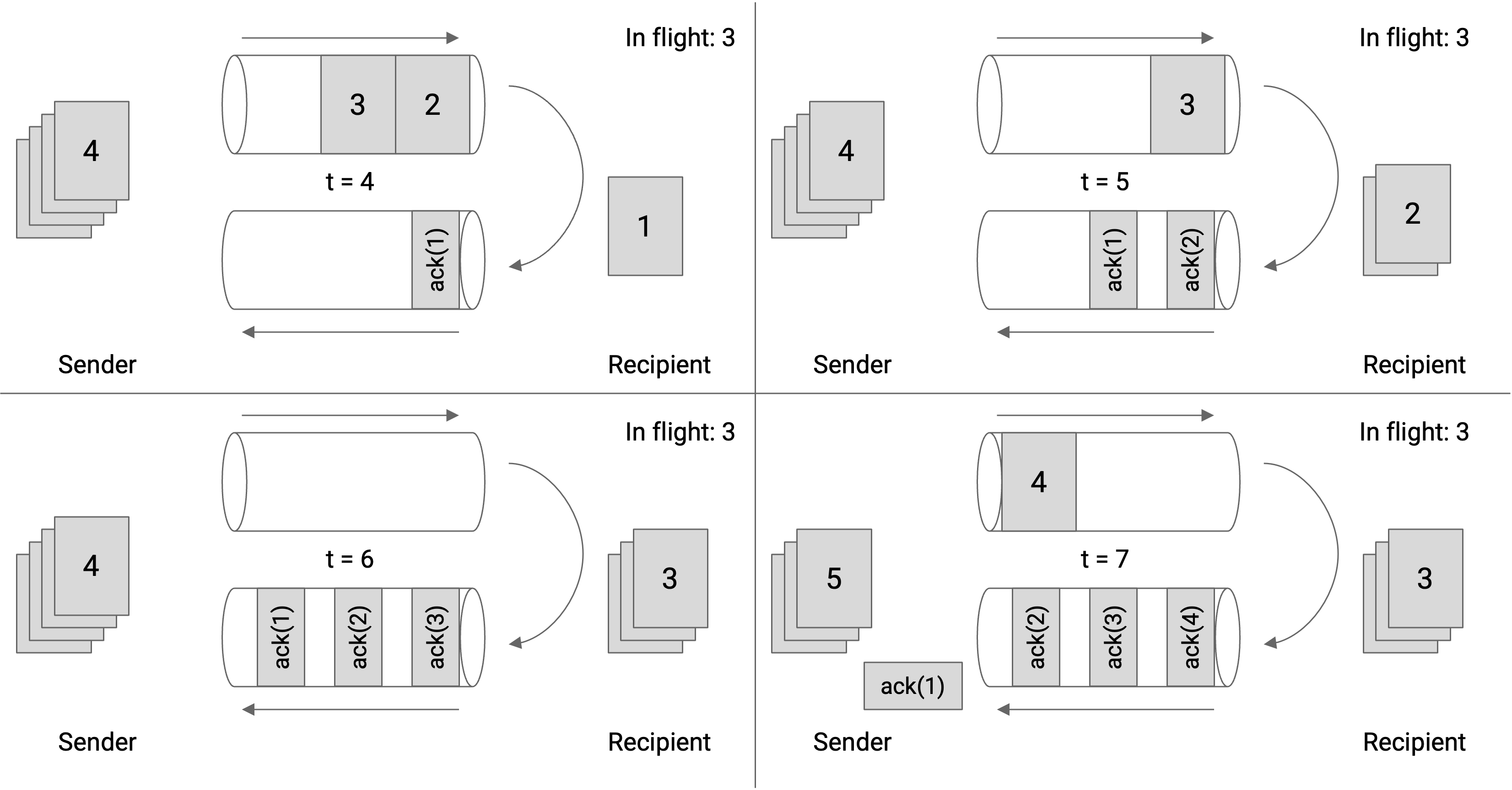
注意,ack 不会填满整个 incoming pipe,因为这些 packet 除了确认收到某个 packet 外,不包含任何实际数据。
Window Size:Flow Control¶
考虑 recipient 操作系统中的 transport layer protocol。recipient 可能乱序收到 packet,但 bytestream 抽象要求 packet 必须按顺序递交。这意味着传输层实现必须通过 buffering 把乱序 packet 暂存起来(保存在内存中),直到轮到它们被递交。
例如,假设 recipient 已经收到并处理了 packet 1 和 2。然后,recipient 看到 packet 4 和 5。传输层实现还不能把 4 和 5 递交给应用。相反,我们必须等待 packet 3 到达,在此期间还必须把 packet 4 和 5 保存在传输层实现的内存中。
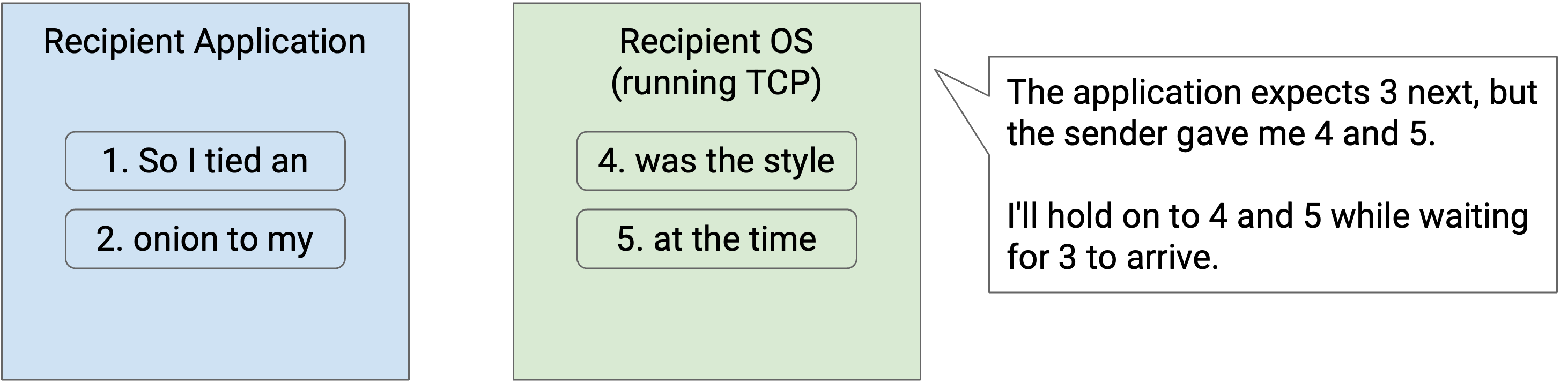
然而,内存不是无限的,recipient 用来存储乱序 packet 的 buffer size 是有限的。recipient 必须把每个乱序 packet 存在内存中,直到中间缺失的 packet 到达。如果 connection 中有大量 packet loss 和 reordering,recipient 可能耗尽内存。
Flow control 确保 recipient 的 buffer 不会耗尽内存。为此,我们让 recipient 告诉 sender buffer 里还剩多少空间。recipient buffer 中剩余空间的大小称为 advertised window。在 acknowledgement 中,recipient 会说:「我已经收到了这些 packet,并且还有 X bytes 空间可以保存 packet。」
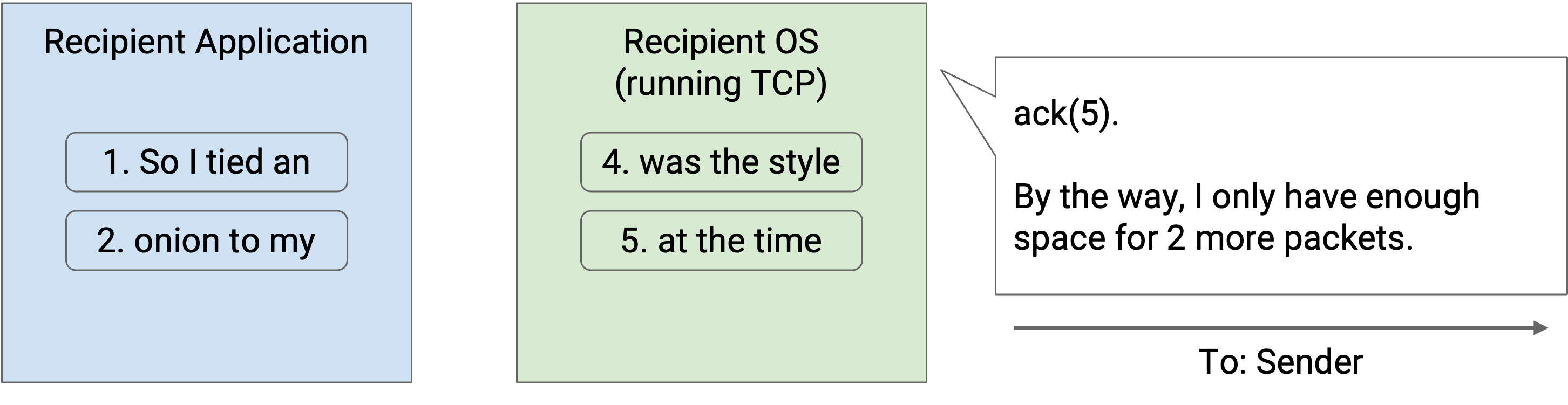
当 sender 得知 advertised window 后,会相应调整自己的 window。具体来说,in-flight packet 的数量不能超过 recipient 的 advertised window。如果 recipient 说「我的 buffer 有足够空间容纳 5 个 packet」,那么 sender 必须把 window 设为最多 5 个 packet(即使带宽可能允许更多 packet in flight)。
Window Size:Congestion Control¶
回忆一下,为了最大化使用带宽,sender 会把 window size 设置到能够充分消耗瓶颈 link 带宽。例如,如果瓶颈 link 的带宽是 1 Gbps,我们会设置 window size,使 sender 在整个 RTT 期间都持续以 1 Gbps 发送数据(没有空闲)。
在实践中,这条 1 Gbps 的 link 不太可能只被一个 connection 使用。其他 connection 也可能正在使用这条 link 上的容量。sender 不应该消耗这条 link 的全部带宽,而应该只消耗属于自己的那一份带宽容量。
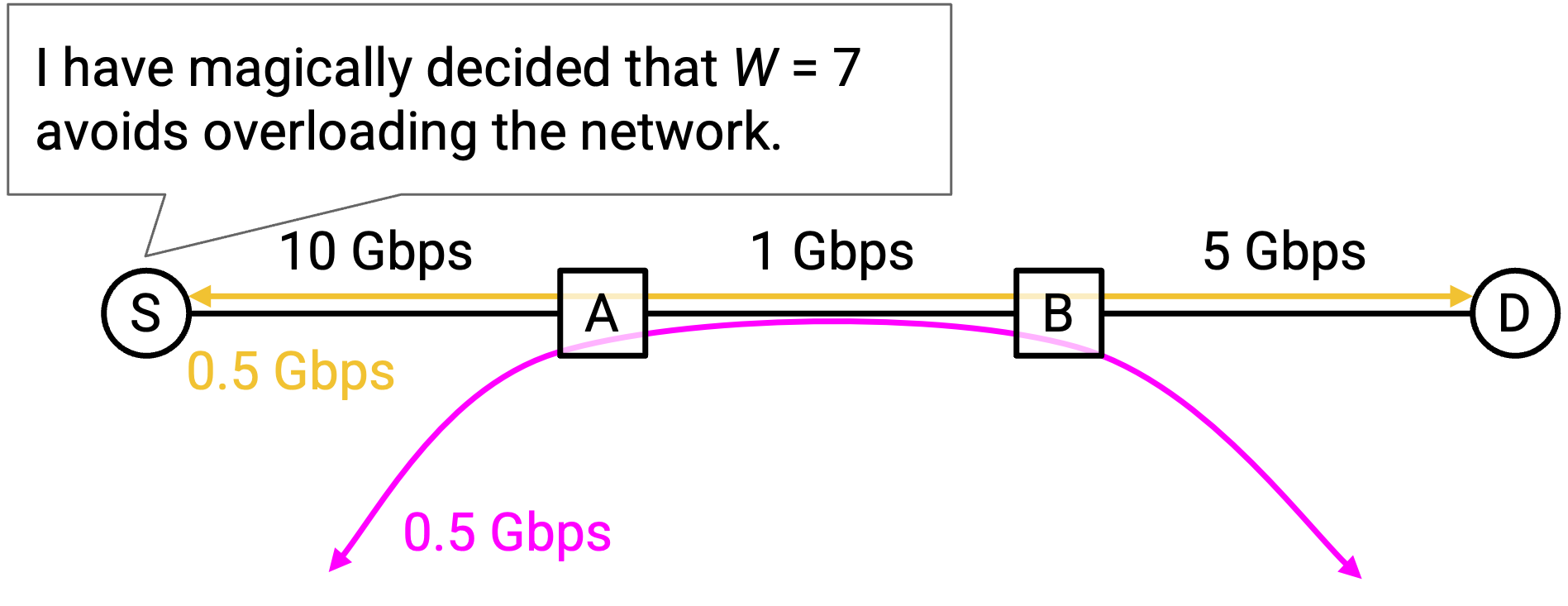
但是,每个 connection 应该分到多少带宽?
假设有两个 connection 分别使用 400 MBps 和 250 MBps。如果另一个 connection 也试图使用同一条 link,也许 sender 的份额就是剩下的 350 MBps。但另一种说法是,带宽并没有被公平共享,所以也许所有 connection 都应该调整到使用 333 MBps。
确定并计算每个 connection 能使用多少带宽,是 congestion control 的目标。congestion control 算法本身就是一个完整主题(下一节会讨论)。现在,我们先把 congestion control 抽象掉,并认为作为传输层的一部分,sender 正在实现一个 congestion control 算法,它的工作是动态计算 sender 在这个 connection 的瓶颈 link 上应占的份额。
运行这个算法得到的结果是 sender 的 congestion window(cwnd)。现在你只需要知道,这个算法会输出这个数字;它表示一个带宽值,在不让 link 过载、并且和其他 connection 公平共享带宽的前提下最大化性能。
现在我们知道如何设置 window 来实现前面提到的三个目标。为了充分利用网络容量,我们会根据 RTT 和瓶颈 link 带宽设置 window size。
为了避免接收方过载,我们会根据 recipient 的 advertised window 限制 window size。为了避免 link 过载,我们会根据 sender 的 congestion window 限制 window size(这是 sender 运行 congestion control 算法输出的某个数字)。
为了同时满足这三个目标,我们会把 window size 设为这三个值中的最小值。在实践中要注意,congestion window(第三个目标)总是小于或等于充分使用带宽所需的 window size(第一个目标)。如果没有 congestion,我们会充分使用全部瓶颈带宽,所以两个数字相等。在大多数情况下,congestion 会迫使我们使用少于全部瓶颈带宽的容量,所以第三个数字会小于第一个数字。不存在 congestion window 对应带宽大于瓶颈带宽的情况。
另外,在实践中发现瓶颈带宽很困难。sender 必须以某种方式遍历网络拓扑,并了解每条 link 的带宽。因为第一个数字很难获知,而且它总是大于或等于第三个数字,所以我们可以把 window size 设为后两个数字的最小值(忽略第一个数字)。window size 是 sender 的 congestion window 和接收方的 advertised window 中的最小值。
更聪明的 Acknowledgement¶
到目前为止,每个 ack packet 都对应单个 packet。我们能不能比一次确认一个 packet 做得更好?一次确认一个 packet 有什么问题?
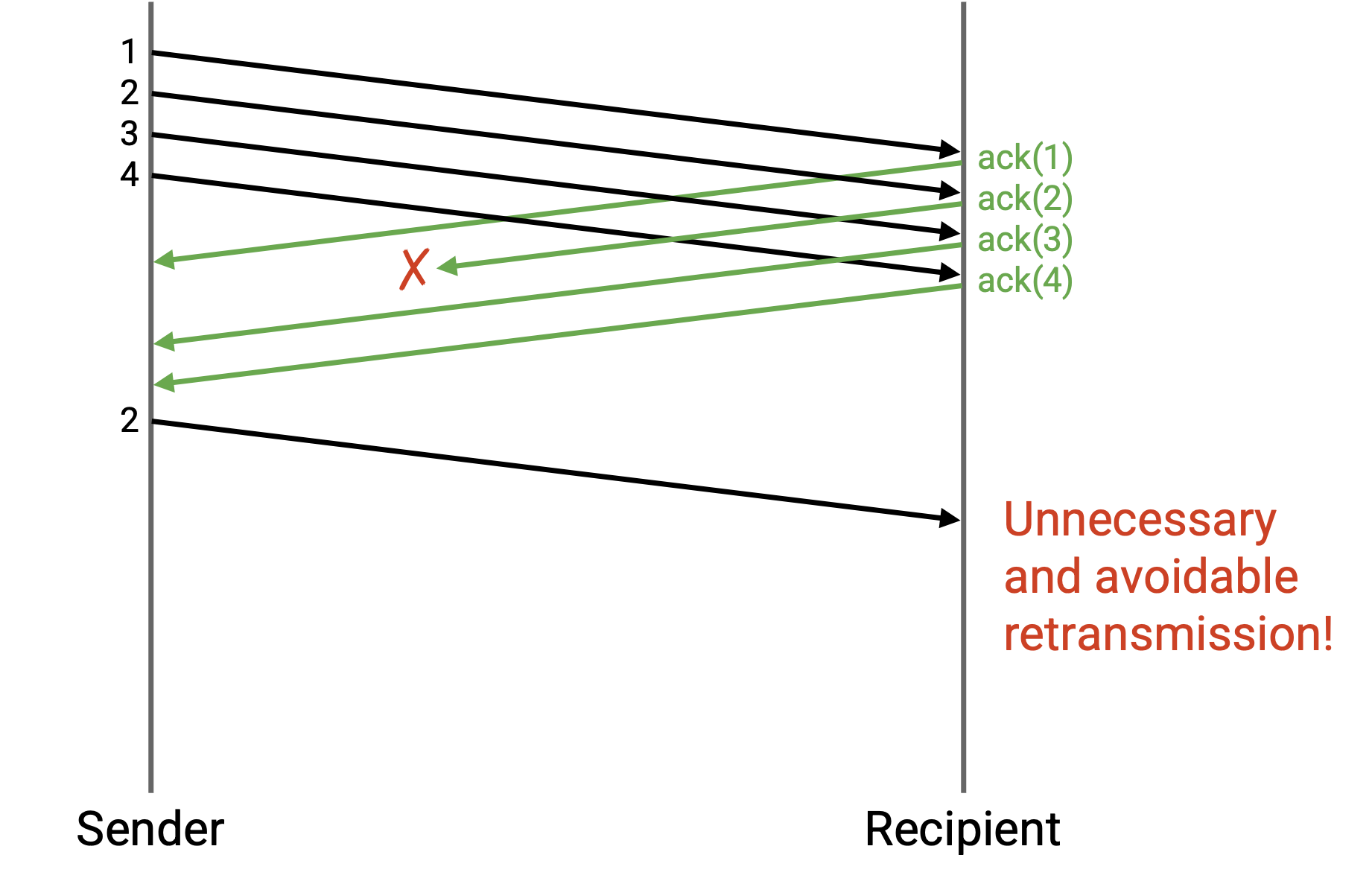
在这个例子中,某个 ack 被丢弃了,尽管 recipient 已经成功收到了全部 4 个 packet。这会迫使 sender 重发 packet 2,即使这次重发并没有必要。
每次发送 acknowledgement 时,我们不必只确认某个具体 packet,实际上可以列出我们已经收到的每个 packet。这称为 full information ack。
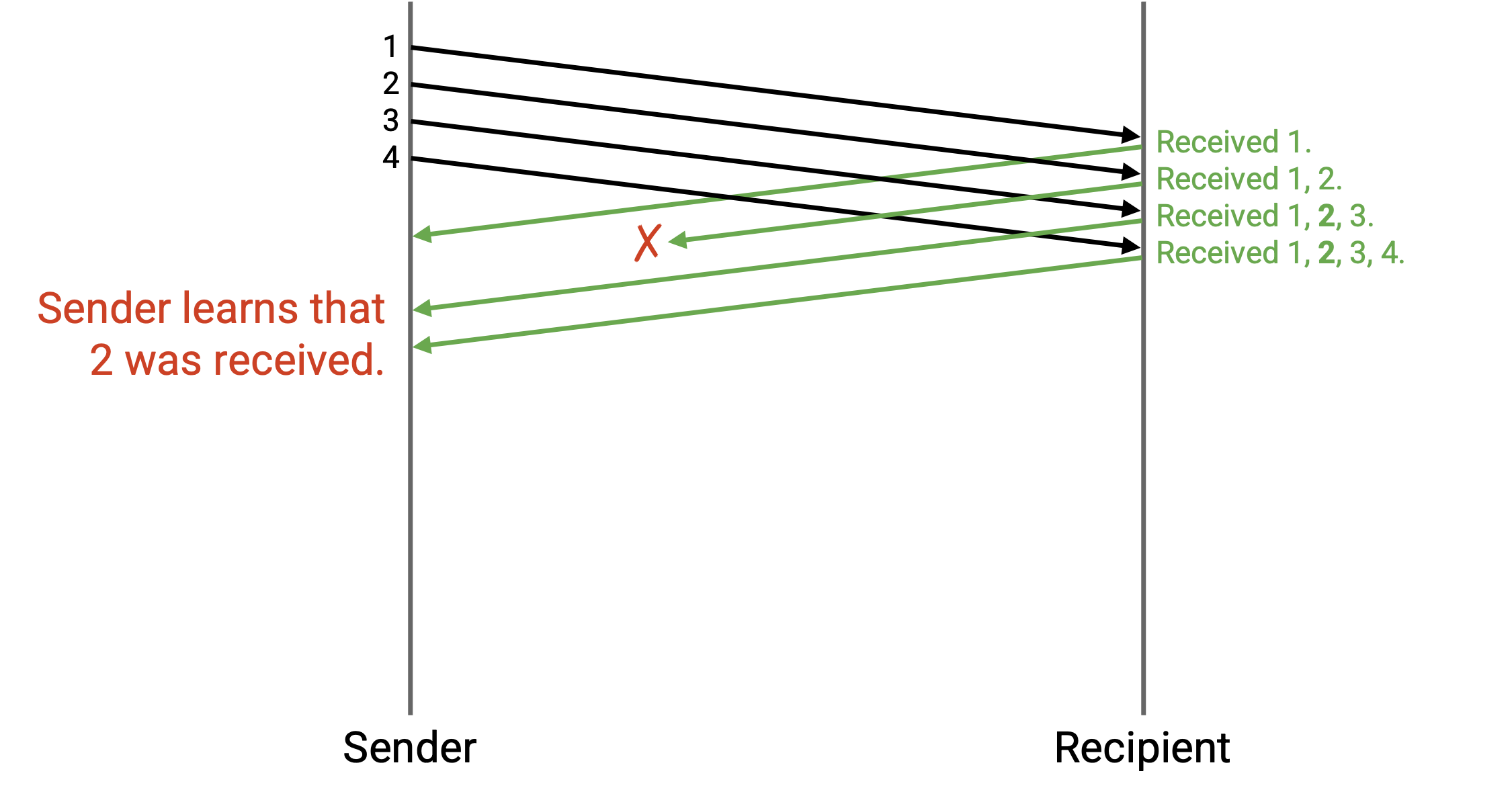
在这个例子中,ack 现在会说:「我收到了 1」,「我收到了 1 和 2」,「我收到了 1、2、3」,以及「我收到了 1、2、3、4」。
虽然第二个 ack 被丢弃了,但第三个和第四个 ack 可以帮助 sender 确认 packet 2 已经收到,因此 packet 2 不再需要重发。
随着发送的 packet 越来越多,所有已收到 packet 的列表会变得很长。full information ack 可以通过这种方式缩写信息:「我已经收到了直到 #12 为止的所有 packet。另外,我还收到了 #14 和 #15。」形式化地说,我们给出最高的 cumulative ack(所有小于等于这个数字的 packet 都已经收到),再加上任何额外收到的 packet 列表。
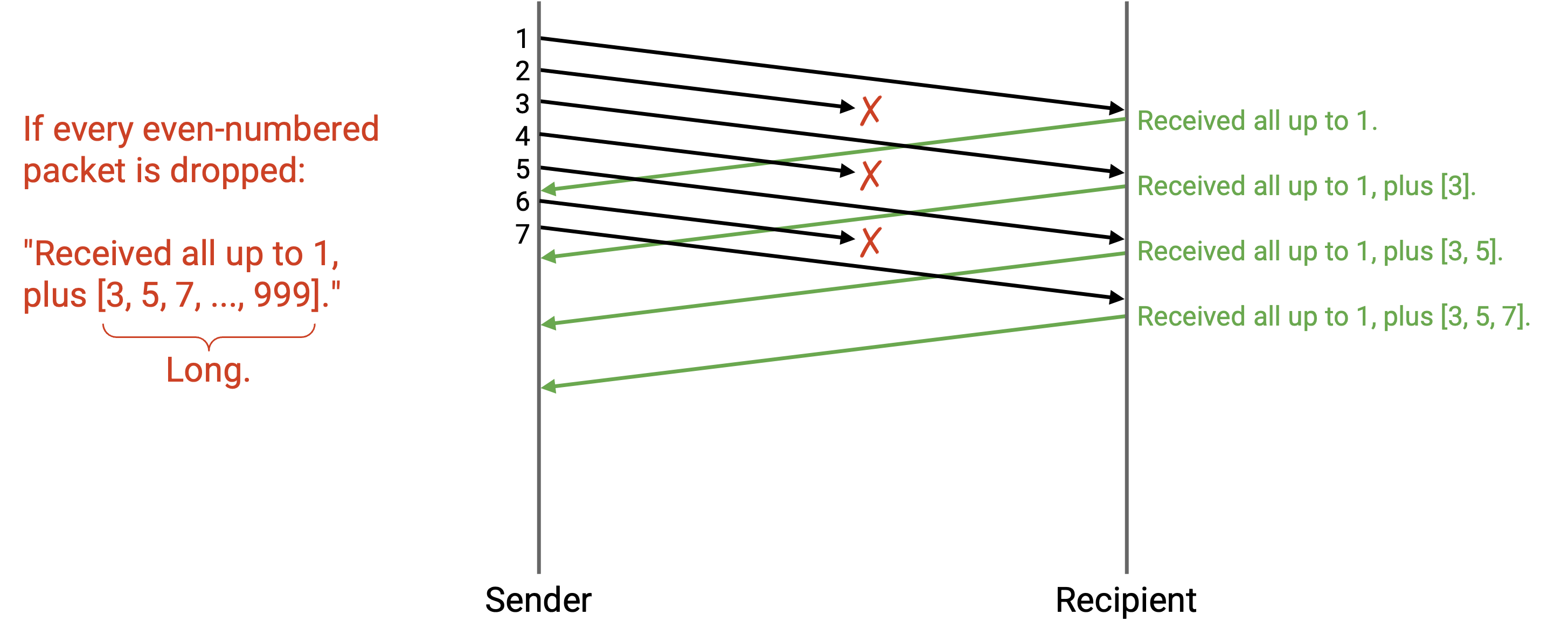
即使有这种缩写,full information ack 也可能变得很长。例如,如果所有偶数编号的 packet 都被丢弃,那么最高的 cumulative ack 将一直是 1(我们只能说直到 1 为止的所有 packet 都已收到,因为 2 被丢弃了)。其余收到的 packet 必须放在类似 [1, 3, 5, 7, 9, ...] 的列表中,这个列表可能会很长。
在 individual ack(每个 ack 丢失都会迫使重发)和 full information ack(ack 可能变长)之间的一种折中是 cumulative ack。我们只提供最高的 cumulative ack,并丢弃额外列表。形式化地说,ack 编码的是这样一个最高 sequence number:它之前的所有 packet 都已经收到。
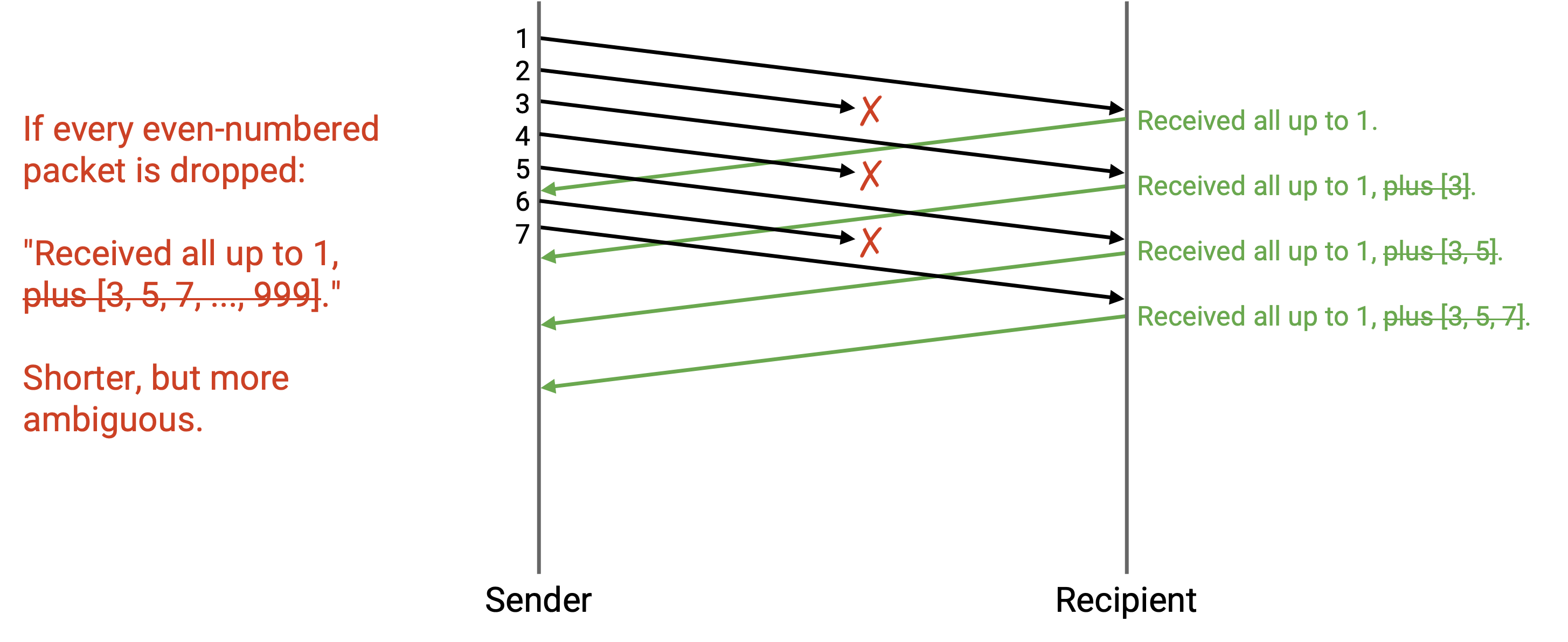
在这个偶数编号 packet 被丢弃的例子中,每个 cumulative ack 都会说:「我已经收到了直到 1 为止,包括 1 在内的所有 packet。」虽然 3 和 5 已经收到,但 cumulative ack 不会编码这些信息,因为它只确认从 1 开始的连续 packet。
cumulative ack 不再有扩展性问题(我们始终发送一个数字,而不是数字列表)。不过,如上面的例子所示,它们可能更模糊。sender 看到三个 acknowledgement 都在说「我已经收到了直到 1 为止,包括 1 在内的所有内容」,因此可以推断有 3 个 packet 已经被收到(packet 1 和另外两个 packet),但无法推断另外两个 packet 是什么。
提前检测丢失¶
我们能不能比等待 timeout 做得更好,利用收到的其他信息更早检测丢失,并更快重发 packet?例如,在 individual ack 模型中,如果我们收到了 packet 1、3、4、5、6 的 ack,我们可能会推断 packet 2 已经丢失,并在 packet 2 的 timer 过期之前就重发它。
更形式化地说,我们可以设置一个值 K(和 window 无关),并规定:如果缺失 packet 后面的 K 个后续 packet 都已经被 ack,那么我们就认为这个 packet 丢失了(即使 timer 还没有过期)。例如,如果 K=3,我们正在等待 packet 5 的 ack,并且收到了 6、7、8 的 ack,那么就可以认为 packet 5 丢失了。
![]()
在实践中,通过后续 ack 检测丢失比等待 timeout 快得多。如果 timeout 根据 RTT 计算,它可能是秒级的。另一方面,现代带宽可以让 ack 每隔几微秒就到达一次。
根据我们发送 ack 的策略,这种检测丢失的方法会有不同表现。上面的例子假设我们发送的是 individual ack,那么另外两种 ack 模型会怎样?
如果使用 full-information ack,策略非常相似,而且 ack 实际上会更清楚地显示缺失的 packet。
![]()
如果 packet 5 丢失,ack 可能会说「up to 4」,然后「up to 4, plus 6」,再然后「up to 4, plus 6, 7」,最后「up to 4, plus 6, 7, 8」。此时,如果 K=3,那么 5 后面的 K 个 packet 已经被 ack,所以我们可以宣布 packet 5 丢失。
如果使用 cumulative ack,这个策略可能更模糊。如果 packet 5 丢失,那么 ack 可能会说「up to 4」(确认 4),「up to 4」(确认 6),「up to 4」(确认 7),「up to 4」(确认 8)。由于连续 packet 中存在缺口,sender 会看到 duplicate ack。如果 K=3,那么在收到 3 个重复 packet 后(对应缺口之后又有 3 个 packet 被 ack),我们就可以宣布 packet 5 丢失,总共会看到 4 个重复项。
![]()
使用 individual ack 和 full-information ack 时,我们可以清楚看到哪个 packet 需要重发。有一个 packet 缺少 ack(并且后续 K 个 ack 到达)。然而,使用 cumulative ack 时,决定哪个 packet 需要重发会更模糊,尤其是在多个 packet 丢失时。
举个例子,考虑一个 window size 为 W=6、K=3 的 sender。到目前为止,packet 1 和 2 已经被 ack,packet 3-8 处于 in flight 状态。假设 packet 3 和 5 被丢弃。我们先用 individual ACK 走一遍这个例子。
4 到达,recipient 发送 4 的 ack。sender 现在可以发送 9。
6 到达,recipient 发送 6 的 ack。sender 现在可以发送 10。
7 到达,recipient 发送 7 的 ack。sender 现在可以发送 11。
此时,sender 注意到 packet 3 后面的 K=3 个 packet(也就是 4、6、7)已经被 ack。sender 可以宣布 3 丢失,并且也重发 3。
注意,虽然 sender 因为 7 的 ack 而重发了 3 并发送了 11,但这次重发后仍然总共只有 6 个 packet in flight,所以没有违反 window。这是因为当我们重发 3 时,3 本来已经是 in-flight packet 之一。
8 到达,recipient 发送 8 的 ack。sender 现在可以发送 12。
另外,sender 注意到 packet 5 后面的 K=3 个 packet(也就是 6、7、8)已经被 ack,所以 sender 也可以重发 5。
9 到达,recipient 发送 9 的 ack。sender 现在可以发送 13。
现在,我们用 cumulative ACK 重新做这个例子。
4 到达,recipient 发送 4 的 ack,其中说「ack everything up to 2」。此时,sender 知道一定有某个 packet 到达了,但不知道它是 4。尽管如此,sender 仍然可以接着发送 9。注意,这并没有违反 window,因为虽然 sender 看起来有 7 个未 ack 的 packet,但其中一个确实已经被这个重复的「ack everything up to 2」确认了,所以只有 6 个 packet in flight。
6 到达,recipient 发送 6 的 ack,其中仍然说「ack everything up to 2」。同样,sender 推断又有一个 packet 到达了,并且可以接着发送 10。
7 到达,recipient 发送 7 的 ack,其中仍然说「ack everything up to 2」。sender 推断又有一个 packet 到达了,并且可以发送 10。
此时,sender 注意到「ack everything up to 2」已经重复到达 3 次(除了最初针对 2 的 ack 之外)。下一个未 ack 的 packet 是 3,所以 sender 会重发 3。
这时事情开始变得模糊。当 8、9、10 到达 recipient 时,sender 会再收到三份「ack everything up to 2」。(我们假设 recipient 还没有收到 3,因为它是在 9 和 10 之后才被重发的。)
sender 现在可以发送 12、13 和 14,因为又有三个 ack 到达,但接下来应该重发哪个 packet?sender 应该重发 3、4、5,还是其他 packet?
这个例子说明,cumulative ack 并不总是精确表明哪些 packet 已经被收到。不过,ack 的数量(可能包括重复 ack)可以用来判断有多少 packet 已经被收到(即使不知道具体是哪些 packet),这让我们可以继续按照 window size 发送。然而,当我们收到太多 duplicate ack,无法判断应该重发哪个 packet 时,模糊性就会出现。