Congestion Control 原理¶
Congestion 是有害的¶
回忆一下,如果很多 packet 同时到达一个 router(例如突发流量),而 router 需要把这些 packet 都发送到同一条 link 上,那么 router 会先发送一个 packet,并把其他 packet 放进队列(稍后再发送)。
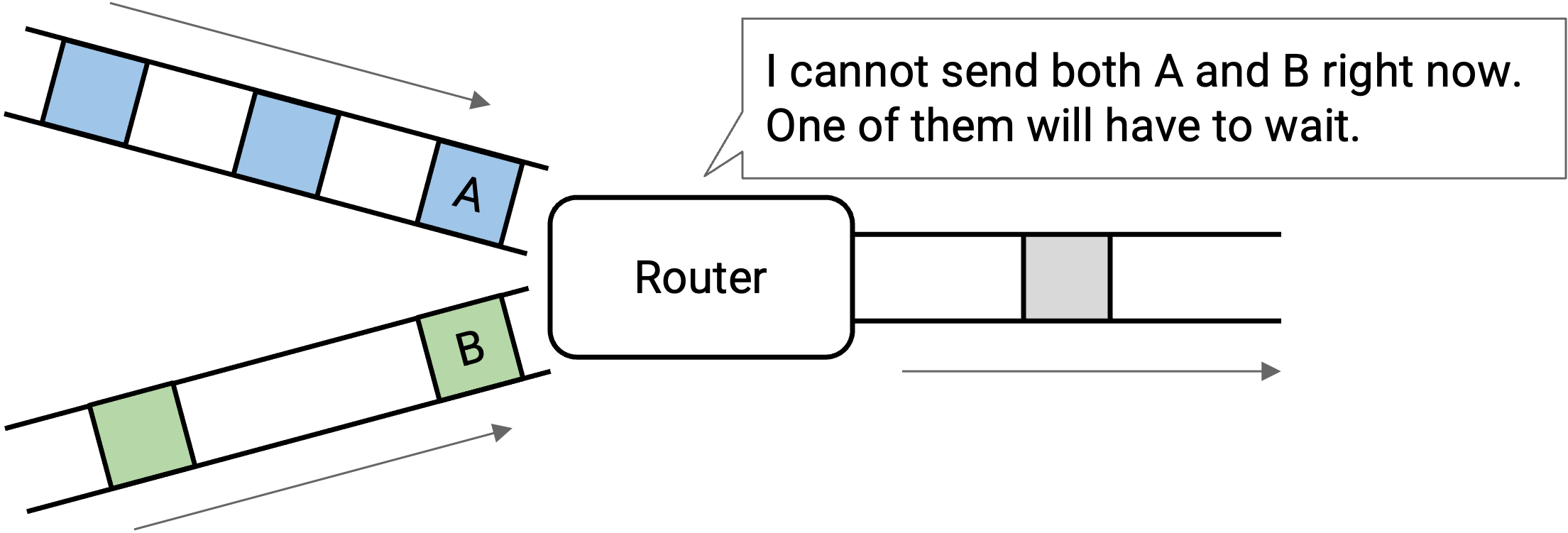
更一般地说,如果 packet 的输入速率超过了 link 能够维持的输出速率,router 就跟不上 incoming packet 的速度。这个 router 处于 congested 状态,需要把 packet 保存在队列中,等待轮到它们发送。队列会导致 packet 延迟。如果队列本身变得太满,而 packet 仍在持续到达,那么 packet 就可能被丢弃。
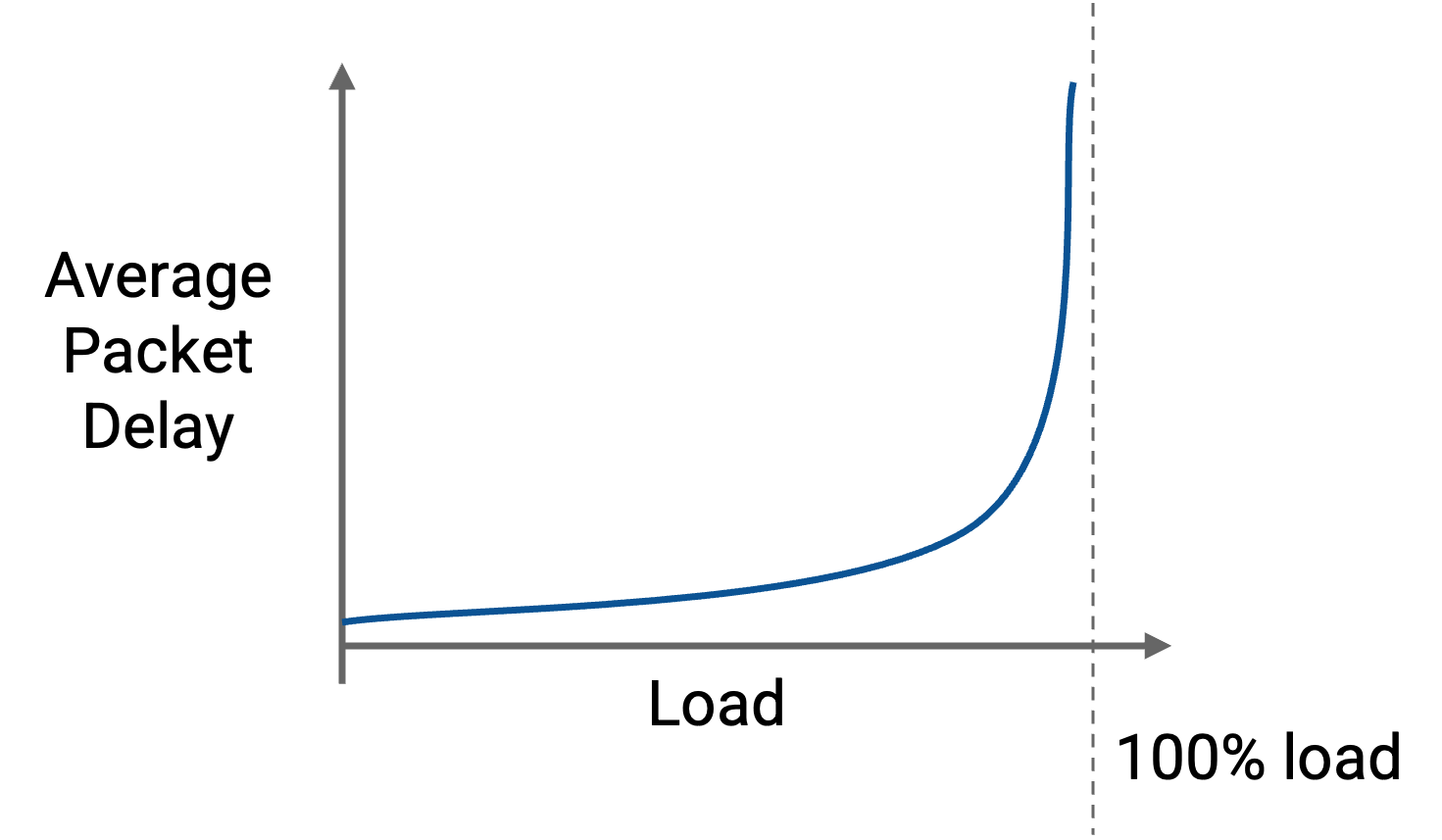
这张图展示了一个具有突发到达的排队系统的性能。虚线表示 link 的容量(最大负载)。随着负载增加,packet 的延迟也会增加。
当到达是突发式的,我们实际上不能使用 link 的最大容量。我们必须在负载和 packet 延迟之间找到合适的性能 trade-off。
注意,即使还没有到达虚线,图中的曲线已经开始向上倾斜。这意味着即使没有任何 packet 被丢弃,排队也已经在延迟 packet。等到我们达到最大利用率并开始丢失 packet 时,队列已经给我们带来了非常大的 packet 延迟。
Congestion 简史¶
在 1980 年代,TCP 并没有实现任何 congestion control。发送速率只受 flow control(recipient buffer 容量)限制。
如果 packet 被丢弃,sender 会以同样快的速率反复重发这个 packet 的副本,直到 packet 到达。更聪明的做法是放慢速度,避免 packet 被丢弃,并减少堵塞网络的重复副本,但早期 TCP 实现并没有这样做。
1986 年 10 月,Internet 开始遭受一系列 congestion collapse,Internet 的容量显著下降。UC Berkeley 和 Lawrence Berkeley Lab 之间的一条 link(两个地点相距约 400 码)的 throughput 从 32 Kbps = 32,000 bps 下降到 40 bps。
Michael Karels(UC Berkeley 本科生)和 Van Jacobson(Lawrence Berkeley Lab 研究员)当时正在 Berkeley Unix 系统(一个有影响力的早期操作系统)中开发网络栈,他们意识到网络中有成千上万个同一 packet 的副本,因为所有人都在尝试重发正在被丢弃的 packet。
Karels 和 Jacobson 开发了一种修复这个问题的算法,后来演化成现代 TCP congestion control 算法。他们的修复是对 TCP 本身的修改:根据 packet loss 动态调整 window size(它决定发送 packet 的速率)。
因为他们的解决方案修改的是 TCP 的逻辑(回忆一下,TCP 实现在操作系统中),所以不需要升级 router 或应用。
TCP congestion control 是 Internet 设计具有临时拼接式特征的许多例子之一。Karels 和 Jacobson 的补丁只是在 BSD 操作系统的 TCP 实现中增加了几行代码。这个补丁有效,所以很快被采用。从那以后,congestion control 这个主题得到了广泛研究,也出现了若干改进;但最终,原始补丁中的核心思想一直延续至今。从那以后,Internet 没有再发生 congestion collapse,所以最初的修复经受住了时间考验。
为什么 Congestion Control 很难?¶
为了理解 congestion control 为什么是一个困难问题,考虑下面这张网络图。host A 应该以什么速率发送流量?
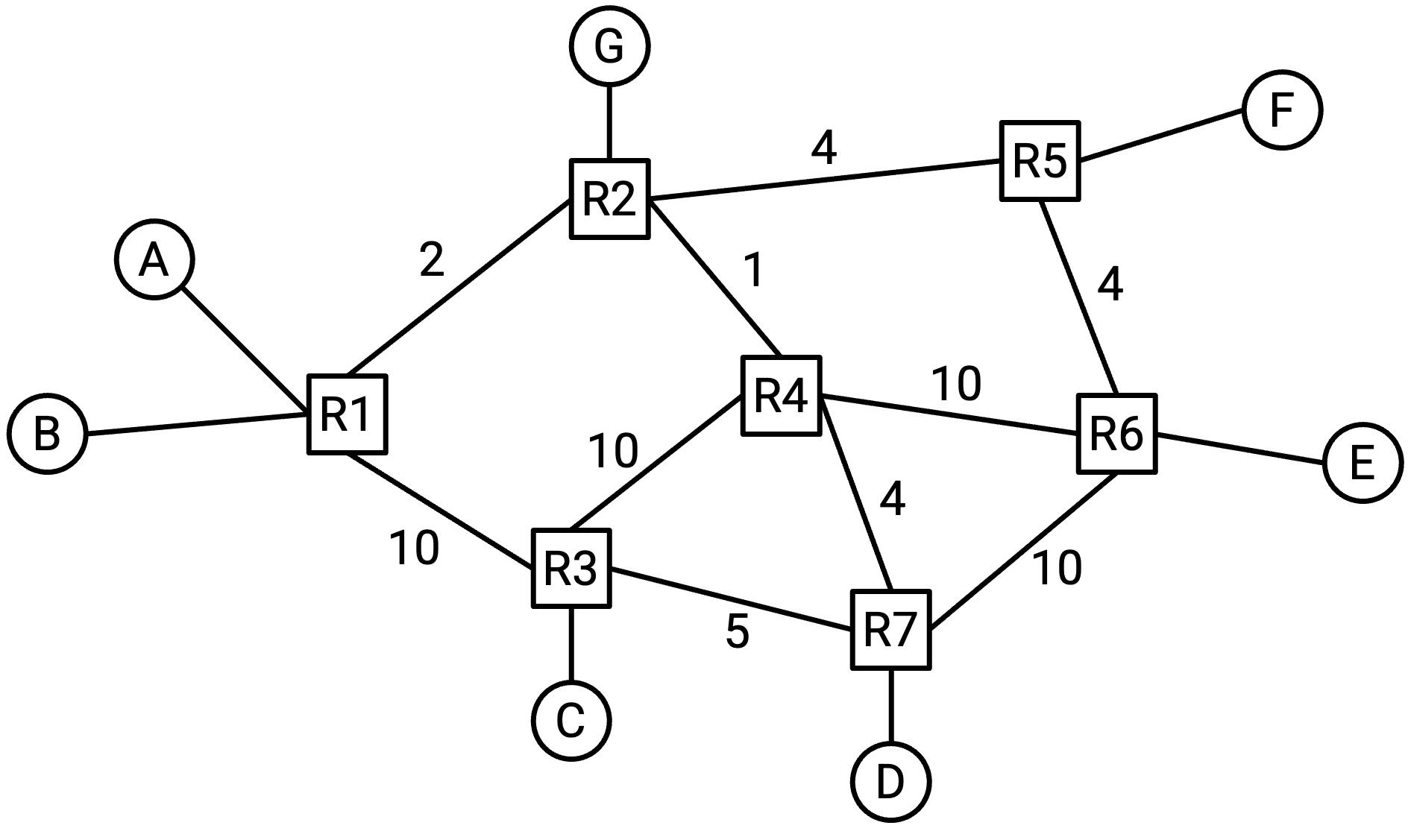
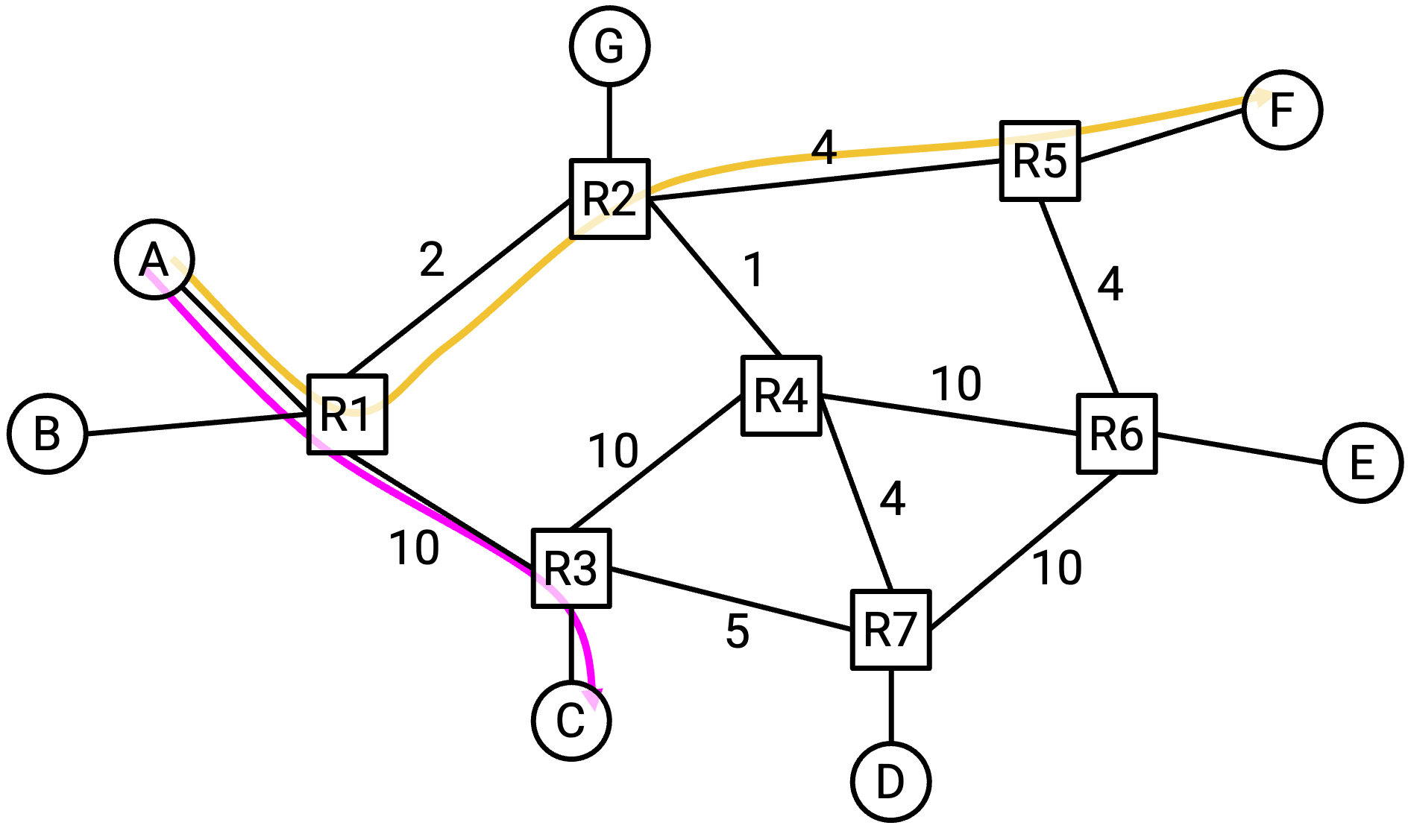
这取决于目的地,所以 A 不能简单地为所有目的地想出一个固定速率。例如,如果 A 正在和 C 通信,那么 A 可以用 10 Gbps 发送 packet。
如果 A 改为和 F 通信,会怎样?这条路径上的 bottleneck link(容量最小的 link)是 2 Gbps,所以 A 大概应该以 2 Gbps 发送 packet。
如果 A 正在和 E 通信,又会怎样?
这取决于流量在 A 和 E 之间走哪条 path。如果流量走下面经过 R3 的 path,那么 A 可以以 10 Gbps 发送 packet。但如果流量走上面经过 R2 的 path,那么 A 现在只能以 1 Gbps 发送 packet。
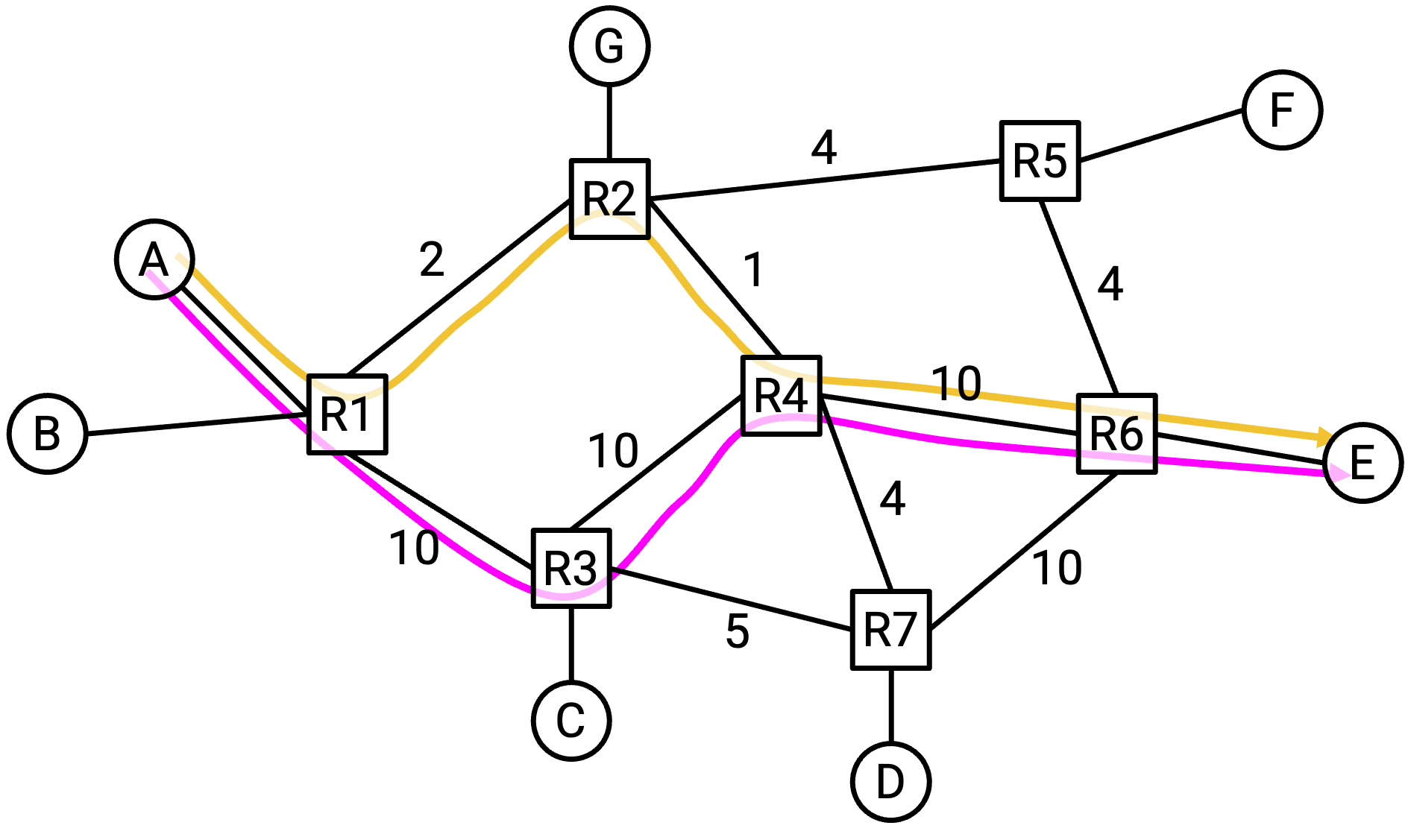
到目前为止,一个结论是:我们的 congestion control 算法需要以某种方式了解 packet 所走 path 上的带宽和瓶颈。
另外,回忆一下,随着新 link 被添加或 link 故障,网络图会随时间变化。这意味着只学习一次 path 信息是不够的。我们的算法需要能适应网络拓扑的变化。
到目前为止,我们一直假设 A 是网络中唯一发送流量的 host,并且 A 可以使用每条 link 的全部容量。但如果其他 connection 也在使用带宽,会怎样?
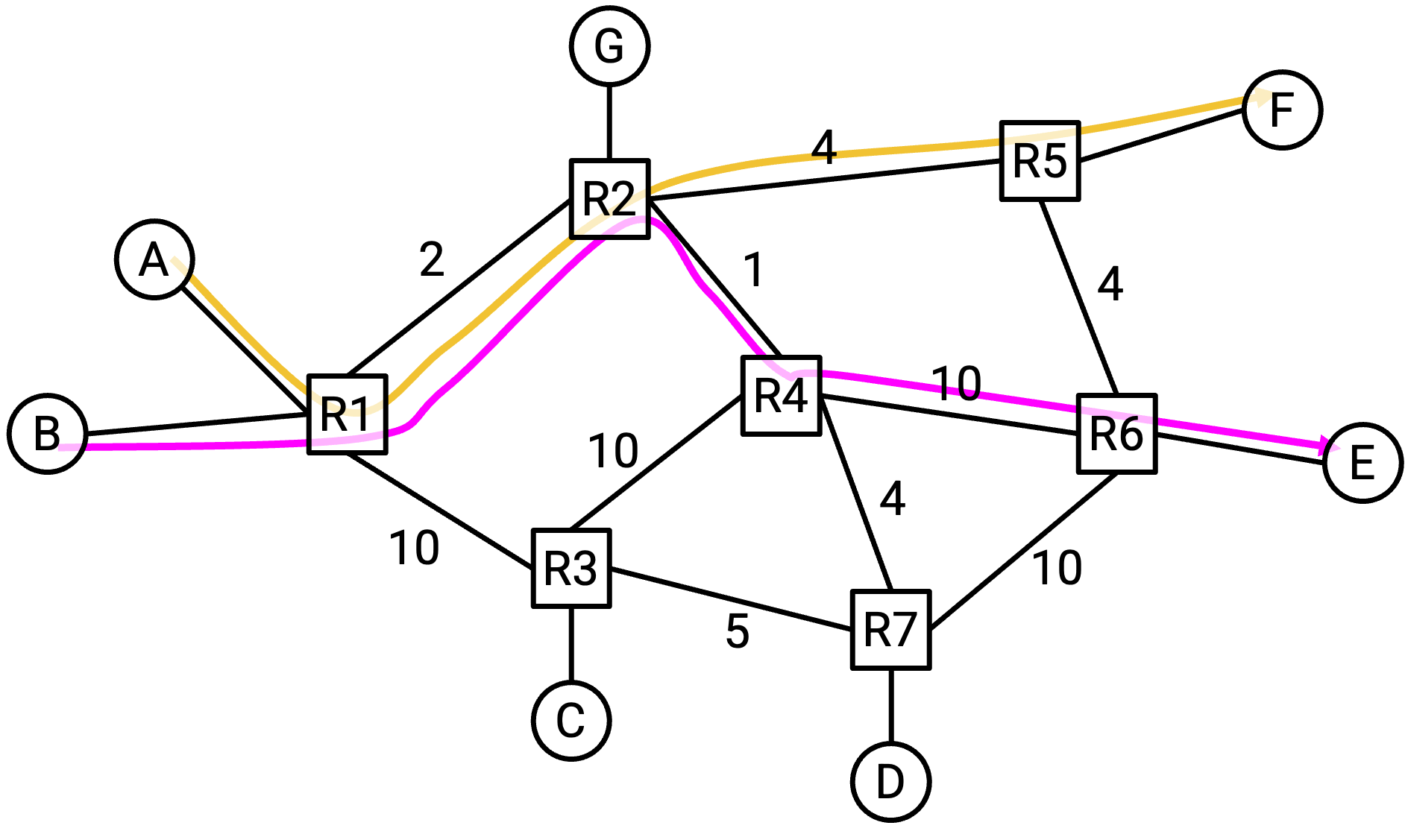
在这个例子中,A 和 F 有一个 connection,B 和 E 有一个 connection。这两个 connection 看起来应该完全独立(不同的 sender,不同的 recipient),但事实上,它们的 path 在网络中共享了一条 link。
如果我们希望这两个 connection 公平共享这条 link 上的容量,也许 A 和 B 应该各自以 1 Gbps 发送。
如果 G 和 D 之间启动了一个新的 connection,会怎样?A 是否应该改变它 1 Gbps 的速率?(这里还没有形式化算法,只是思考怎样使用带宽才显得合理。)
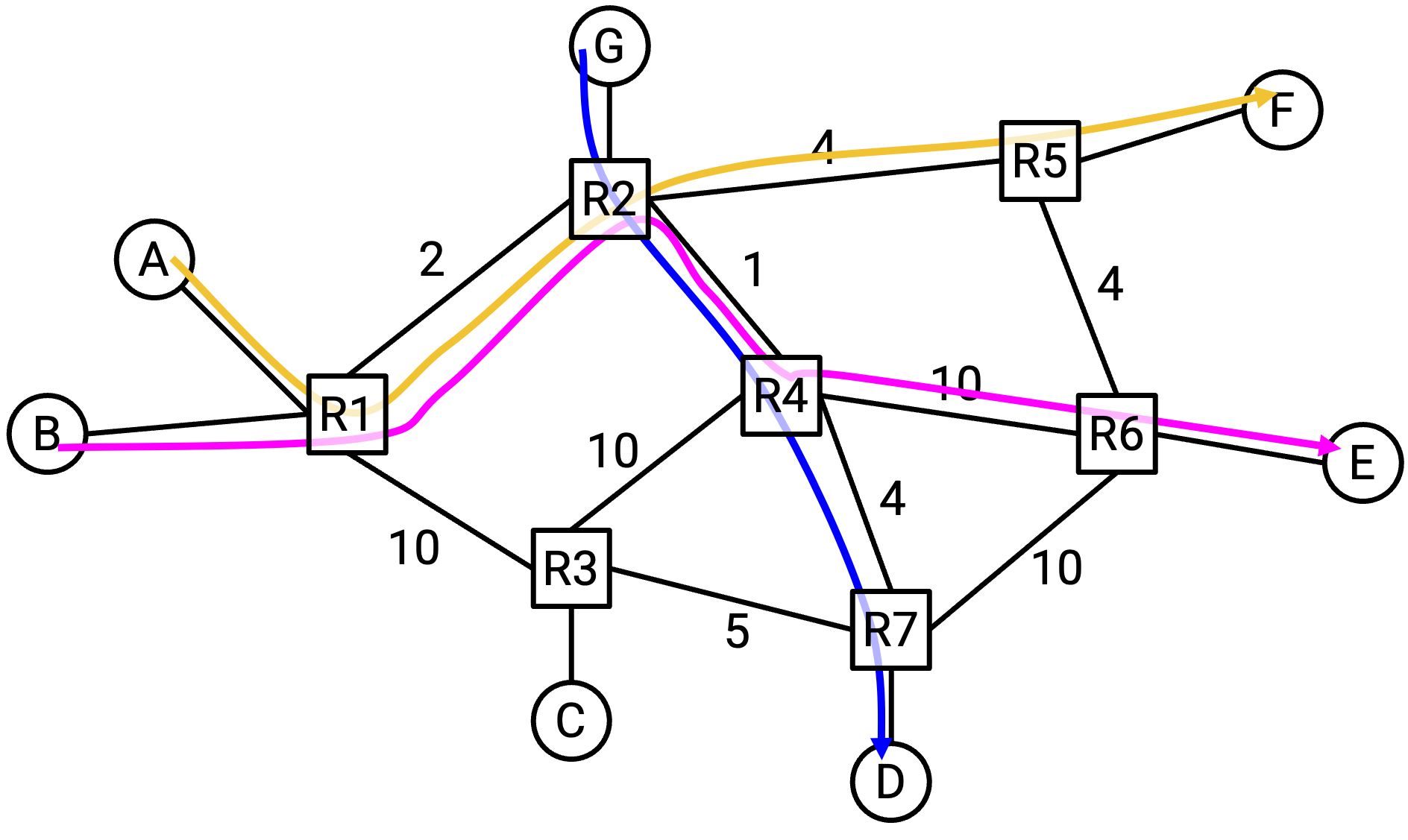
首先注意,G-D 和 B-E 这两个 connection 共享了一条 link。这意味着这两个 connection 必须把速率降低到 0.5 Gbps。
现在,如果回头看 A-F 和 B-E 共同使用的那条 2 Gbps link,B-E 在这条 link 上只使用了 0.5 Gbps。这意味着 A 可以把速率增加到 1.5 Gbps。
这里发生了什么?G-D connection 被创建了,而且它的 path 和 A-F connection 没有任何共同 link。然而,这个看起来不相关的 connection 却导致 A-F connection 的速率增加。connection 可以间接影响其他 connection,即使这两个 connection 没有共享任何 link!
总结一下:当 sender 试图确定发送 packet 的速率时,它必须考虑:目的地、到该目的地的 path、沿着这条 path 共享 link 的 connection、与这些 connection 共享 link 的 connection(间接竞争),依此类推。congestion control 是一个困难问题,因为网络中的所有 connection 都相互依赖,共同决定各自的最优发送速率。
更根本地说,congestion control 是一个资源分配问题。带宽是一种有限资源,每个 connection 都想获得一定数量的资源,而我们需要决定给每个 connection 分配多少带宽。
资源分配是计算机科学中的经典问题。(例子包括 CPU 调度和内存分配算法。)不过,与某些资源分配问题不同,一个 connection 的分配变化可能对所有其他 connection 产生全局影响。另外,每当 connection 被创建或销毁时,分配都必须改变。因此,congestion control 比传统资源分配问题更复杂;事实上,我们甚至没有一个形式化模型来定义这个问题。
在传统资源分配问题中,算法通常提前知道资源(例如 CPU 时间)和任务(例如进程)。与之不同,在 Internet 中没有一个能看见整个网络、并负责分配资源的全局控制者。我们的解决方案必须是 decentralized:每个 sender 决定自己的分配(尽管所有人的决定都高度相互依赖)。
好的 Congestion Control 算法目标¶
从资源分配的角度看,一个好的 congestion control 算法应该满足三个目标。
我们希望资源分配是高效的。link 不应该过载,packet 延迟和 loss 应该尽量少。同时,link 应该尽可能被充分利用。
我们也希望 connection 之间的资源分配是公平的。我们稍后会形式化公平的定义,但粗略地说,每个 connection 应该共享可用容量中的相等部分。
我们希望解决方案能在这些目标之间取得合适的 trade-off。优化某一个目标而牺牲其他目标是可能的,但这样会得到糟糕的方案。例如,我们可以让所有人极快地发送 packet,以确保 link 利用率最大(糟糕方案,会造成 congestion)。或者,我们可以让所有人极慢地发送 packet,以确保 packet loss 最小(糟糕方案,没有利用容量)。
从更实际的系统角度看,我们提出的解决方案需要 scalable,并且 decentralized。我们的解决方案还应该能够适应网络变化,例如拓扑变化、connection 被创建和销毁。
解决方案的设计空间¶
如前所述,Karels 和 Jacobson 通过修补操作系统中的 TCP 实现,修复了 TCP congestion control。但是,如果我们能回到过去,从零开始重新设计 Internet,还可能有哪些 congestion control 设计?
一种可能的替代设计基于预留。sender 可以提前请求带宽,并在 connection 结束后释放这些带宽。如前面讨论过的,在整个网络中维护预留会带来许多技术困难。这个方法还有问题,因为它假设 sender 事先知道自己需要多少带宽,而这不一定是真的。
另一种替代设计基于定价。类比一下高速公路上的快速收费车道(只有付费司机才能使用的专用车道)。使用快速收费车道的价格取决于高速公路有多拥堵。当高速公路上车很少时,使用收费车道很便宜;当交通繁忙时,使用收费车道更贵。飞机票中也存在另一种 congestion pricing:更繁忙的时段(例如节假日)票价更高。
如果把 congestion pricing 应用于 Internet,你的 ISP 可以在浏览器中添加一个按钮,让你支付额外费用以启用更高的 Internet 速度,而且费用可以根据 Internet 的拥堵程度变化。然后,router 可以优先发送付费更多用户的 packet,并丢弃未付费用户的 packet。Internet 上的 congestion pricing 已有相关研究,经济学家有时会说,如果带宽是一种稀缺商品,那么市场结构会导向最优解。congestion pricing 没有被广泛部署,因为它需要某种把支付和 congestion 连接起来的商业模式。
所有现代 congestion control 算法(包括我们将要学习的算法)都基于动态调整。host 会动态学习当前 congestion 水平,并相应调整自己的发送速率。在实践中,动态调整是一个实用方案,因为它很容易泛化。这个方法不假设任何商业模式(定价需要),也不假设用户事先知道自己需要多少带宽(预留需要)。
动态调整确实需要良好协作。TCP 需要网络上的所有人共同合作,公平共享资源。例如,当一个新的 connection 开始使用某些 link 时,其他 connection 需要放慢速度并共享带宽。
在动态调整方法中,解决方案大致分为两类。在 host-based congestion control 算法中,sender 监测性能,并相应调整自己的速率。这些算法完全实现在 sender 端,不需要 router 的特殊支持。对 TCP 的修改就是 host-based 算法,并且今天被广泛部署。
在 router-assisted congestion control 算法中,router 会显式把 congestion 信息发送回 sender,帮助 sender 调整速率。congestion 发生在 router 上,所以 router 很适合提供 congestion 信息。router-assisted 算法近年来已经被部署,尤其是在数据中心中。
有些 router-assisted 算法发送很少的信息,例如一个表示 congestion 的 bit;另一些算法会发送更详细的信息,例如 sender 应该使用的精确速率。
注意,在两种情况下,router 都在把 congestion 信号反馈给 sender。在 router-assisted 算法中,router 显式发送一条关于自身 congestion 程度的消息。相反,在 host-based 算法中,sender 不会从 router 收到显式反馈。sender 会使用来自 router 的隐式线索(例如 packet 被丢弃或延迟)来推断 router 处于 congested 状态。
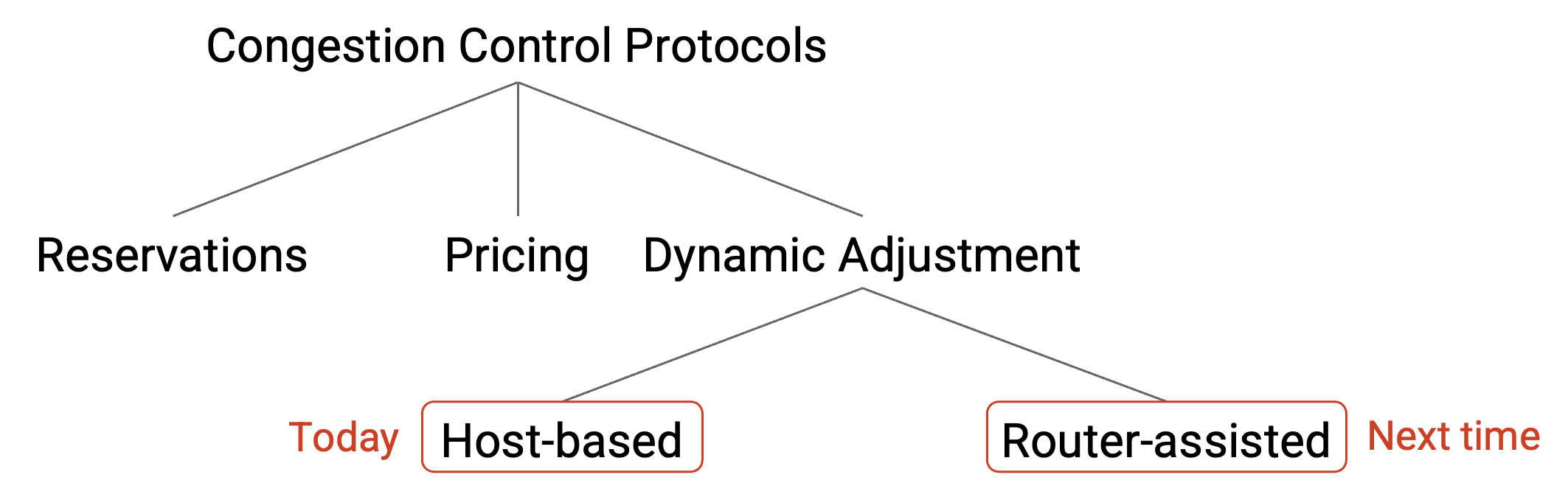
在这张 congestion control 方法分类图中,我们会关注动态调整方法;在动态调整解决方案的空间中,我们会关注 host-based 解决方案。