Congestion Control 设计¶
Host-Based 算法草图¶
大多数 host-based 算法都遵循同一个总体思路,差异主要出现在三个关键选择点上。
每个 sender 都独立地反复运行下面这段逻辑:尝试以速率 R 发送一段时间。然后问:我在这段时间内是否经历了 congestion?如果是,就降低 R。如果不是,就增加 R。
这里缺少的一部分是:我们最开始应该以什么速率发送?我们需要某种方式来选择初始速率 R。
三个关键选择点是:如何选择初始速率?如何检测 congestion?每次应该增加或减少多少?
检测 Congestion¶
sender 如何检测网络是否 congested?有两种常见方法。
sender 可以检查 packet loss。这是 TCP 常用的方法。这个方法的好处是信号明确。每个 packet 要么被标记为丢失(timeout 或 duplicate ack),要么没有丢失。另外,TCP 为了重发 packet,本来就会检测丢失的 packet,所以我们不需要从头重新实现。
这个方法的问题是,有时 packet loss 是由损坏(checksum 错误)导致的,而不是 congestion。事实上,当某条 link 并不 congested、但经常损坏 packet 时,TCP 会被误导并表现很差。另外,packet reordering 也可能误导 TCP。一个迟到的 packet 可能被错误地认为已经丢失。
这个方法的另一个关键缺点是,我们检测 congestion 的时机太晚。等到 packet 被丢弃时,router queue 已经满了,packet 也已经在被延迟。
sender 也可以不检查 packet loss,而是通过检查 packet delay 来检测 congestion。sender 可以测量发送一个 packet 到收到该 packet 的 ack 之间的时间。如果 sender 注意到 delay 正在增加,这可能就是 congestion 的信号。
从历史上看,准确测量 delay 一直被认为很困难。packet delay 可能会随 queue size 和其他流量而变化。很多年来,基于 packet delay 的方法没有被广泛部署;不过近年来,Google 的 BBR protocol(2016)表明 delay-based 算法是可行的,一些服务(例如 Google 服务)已经采用了 delay-based 算法。
发现初始速率¶
当一个 connection 刚开始时,我们必须确定发送 packet 的初始速率。我们可以通过一个发现过程来学习初始速率:尝试几个不同的速率,从而估计可用带宽。
我们希望这个发现过程是安全的,所以应该从较慢的速率开始。我们不希望一开始就用 packet 淹没网络。
同时,为了效率,我们希望发现过程能快速发现可用带宽。为此,我们会在每次后续尝试中快速提高速率。如果发现过程花费很长时间,我们就浪费了本可以用最优速率发送 packet 的时间。举个例子,假设我们每 100 ms 把速率增加 0.5 Mbps,直到检测到 congestion(loss)。如果可用带宽是 1 Mbps,发现阶段需要 2 次迭代 = 200 ms。然而,如果可用带宽是 1 Gbps = 1000 Mbps,那么发现阶段需要 2000 次迭代 = 200 秒,才能提升到一个合适速率,这太久了。Internet 中有各种各样的 link speed,所以这两种可能在现实中都会出现。
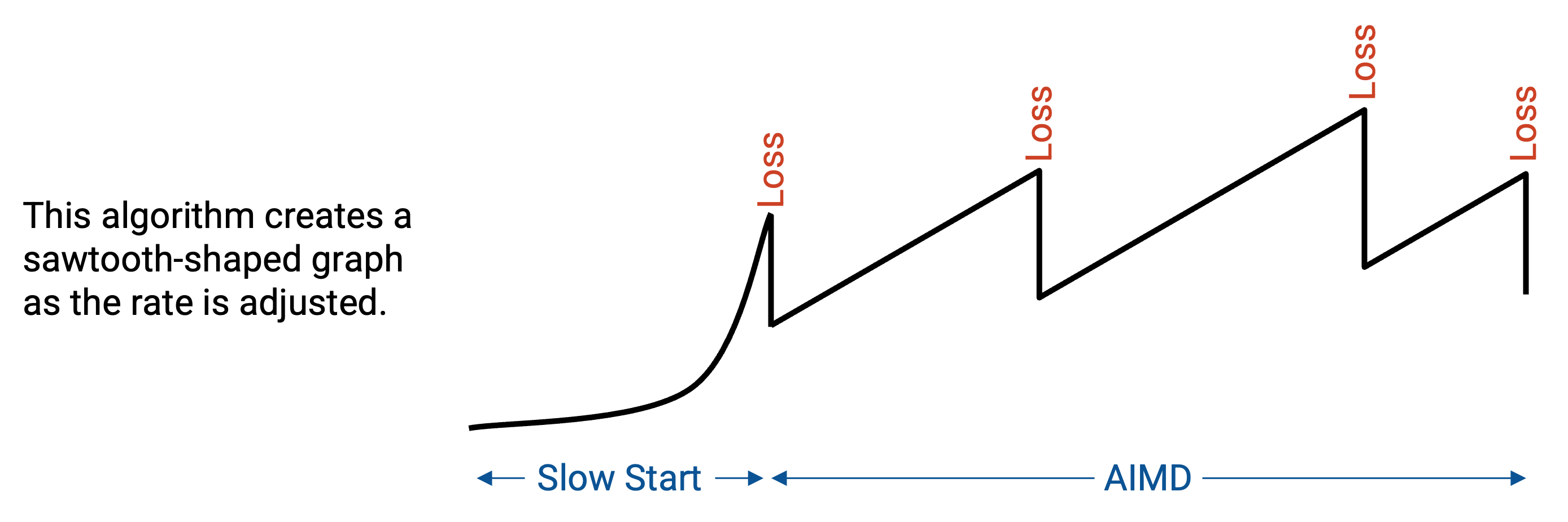
为了同时支持较慢的起步和快速提升,我们会每次按乘性因子增加带宽(而不是按加性因子增加)。这个方案称为 slow start,不过这个名字可以说并不直观。在 slow start 中,我们从一个很小的速率开始,这个速率几乎总是远小于实际带宽。然后,我们指数级提高速率(例如每次翻倍),直到遇到 loss。安全的速率是遇到 loss 前的那个速率(我们不希望使用已经经历 loss 的速率)。形式化地说,如果在速率 R 发生 loss,那么安全速率是 R/2。
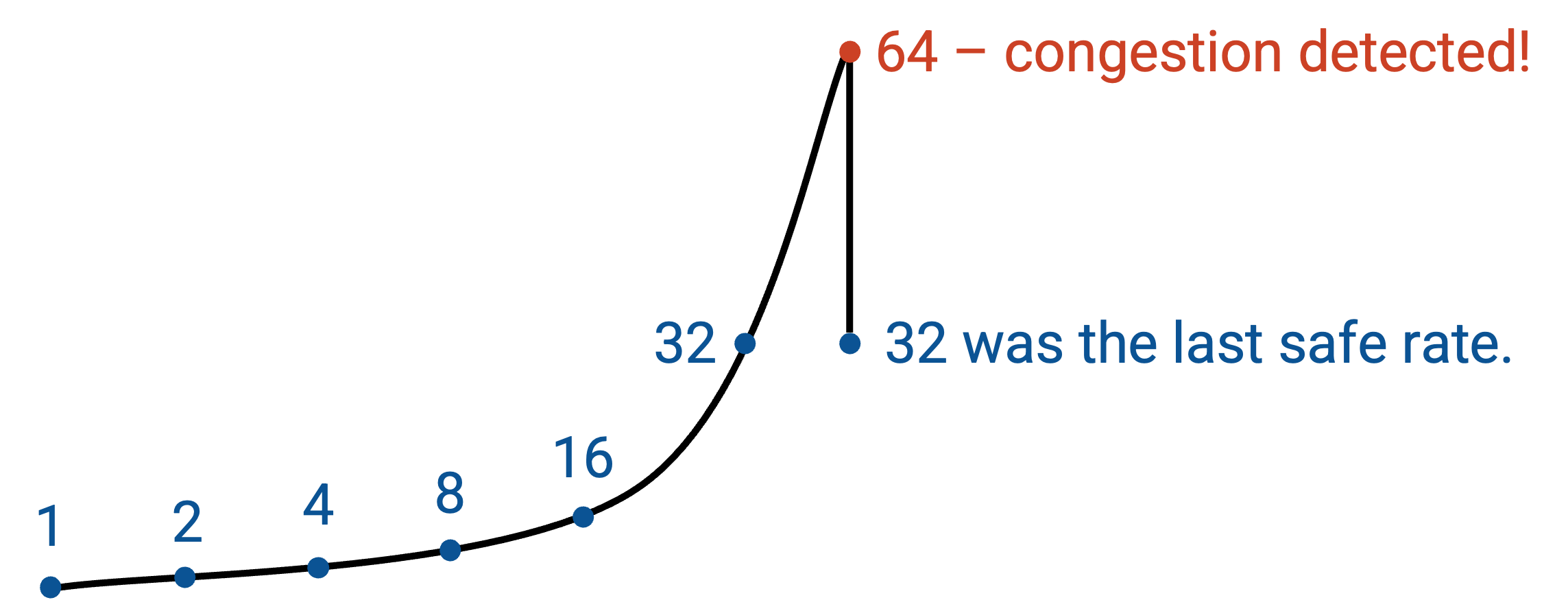
调整:响应 Congestion¶
回忆一下,在发现阶段之后,我们会不断调整带宽,因为网络本身在变化,可用带宽不是常数。
最后一个选择点是:如果检测到 congestion,我们应该把带宽降低多少;如果没有检测到 congestion,我们应该把带宽增加多少。
我们的决定会影响 host 适应可用带宽变化的速度,而这又决定了带宽被消耗得有多有效。如果我们花很久才适应变化并找到合适速率,就会有很多时间运行在次优带宽上,这是低效的。适应过慢也可能导致公平性问题。例如,如果我正在使用一条 link 的全部带宽,而另一个 connection 被打开,我就需要快速适应并降低自己的带宽,以便共享这条 link。
回忆一下,congestion control 算法的主要目标是效率(使用所有可用带宽)和公平性(connection 平等共享带宽)。我们需要选择同时实现这两个目标的增加和减少规则。
我们可以选择哪些规则?从高层看,我们可以快速或缓慢地响应。更具体地说,快速变化是乘性的,例如每次迭代把速率翻倍或减半。缓慢变化是加性的,例如每次迭代把速率加 1 或减 1。这些选项形成四种可能:
AIAD:additive increase,additive decrease
AIMD:additive increase,multiplicative decrease
MIAD:multiplicative increase,additive decrease
MIMD:multiplicative increase,multiplicative decrease
在这四种选择中,事实证明 AIMD(缓慢增加,快速减少)最适合实现效率和公平性。
直觉上,AIMD 是一个合理选择,因为发送过多比发送过少更糟。当速率过高时,我们会造成 congestion,packet 会被丢弃。当速率过低时,我们没有用完所有带宽,但至少没有造成 congestion。
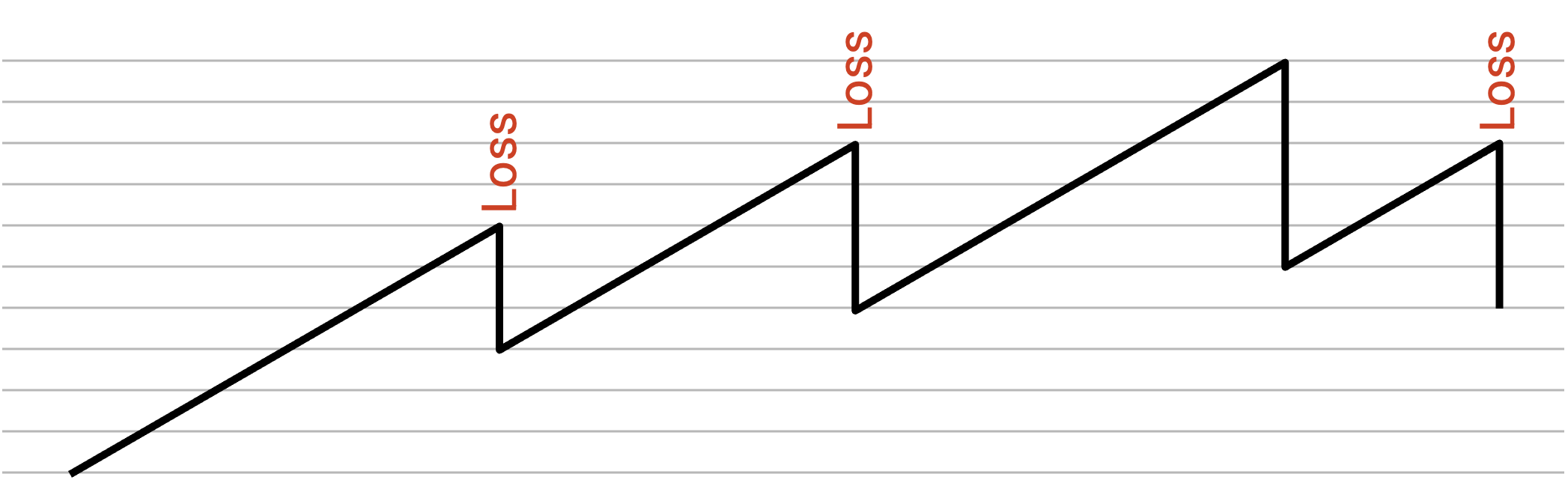
AIMD 会产生这样的行为:没有 congestion 时,我们缓慢增加速率,逐步逼近最大带宽。然后,一旦超过最大带宽并检测到 congestion,就快速降低。这样,我们大部分时间都处于速率偏低的状态(更可取);而当速率偏高时(不可取),我们会快速降低,以避免 congestion。
调整:模型¶
为什么 AIMD 是实现效率和公平性的最佳选择?我们做一个更详细的分析。
首先注意,四种选择在实现效率方面都做得不错。低于最优速率(未 congested)时增加,高于最优速率(congested)时减少,从长期来看,我们的速率应该始终在最优速率附近徘徊。
然而,事实证明,在这四种选择中,只有 AIMD 会带来公平性。为了说明原因,考虑一个简单模型:两个 connection 经过一条容量为 C 的 link。这两个 connection 分别以速率 X1 和 X2 发送。我们知道,如果 X1+X2 大于 C,网络就 congested;如果 X1+X2 小于 C,网络就处于低负载状态。
为了实现效率,我们希望 link 被充分利用,也就是 X1+X2 = C。为了实现公平性,我们希望 X1 = X2,也就是两个 connection 平等共享容量。
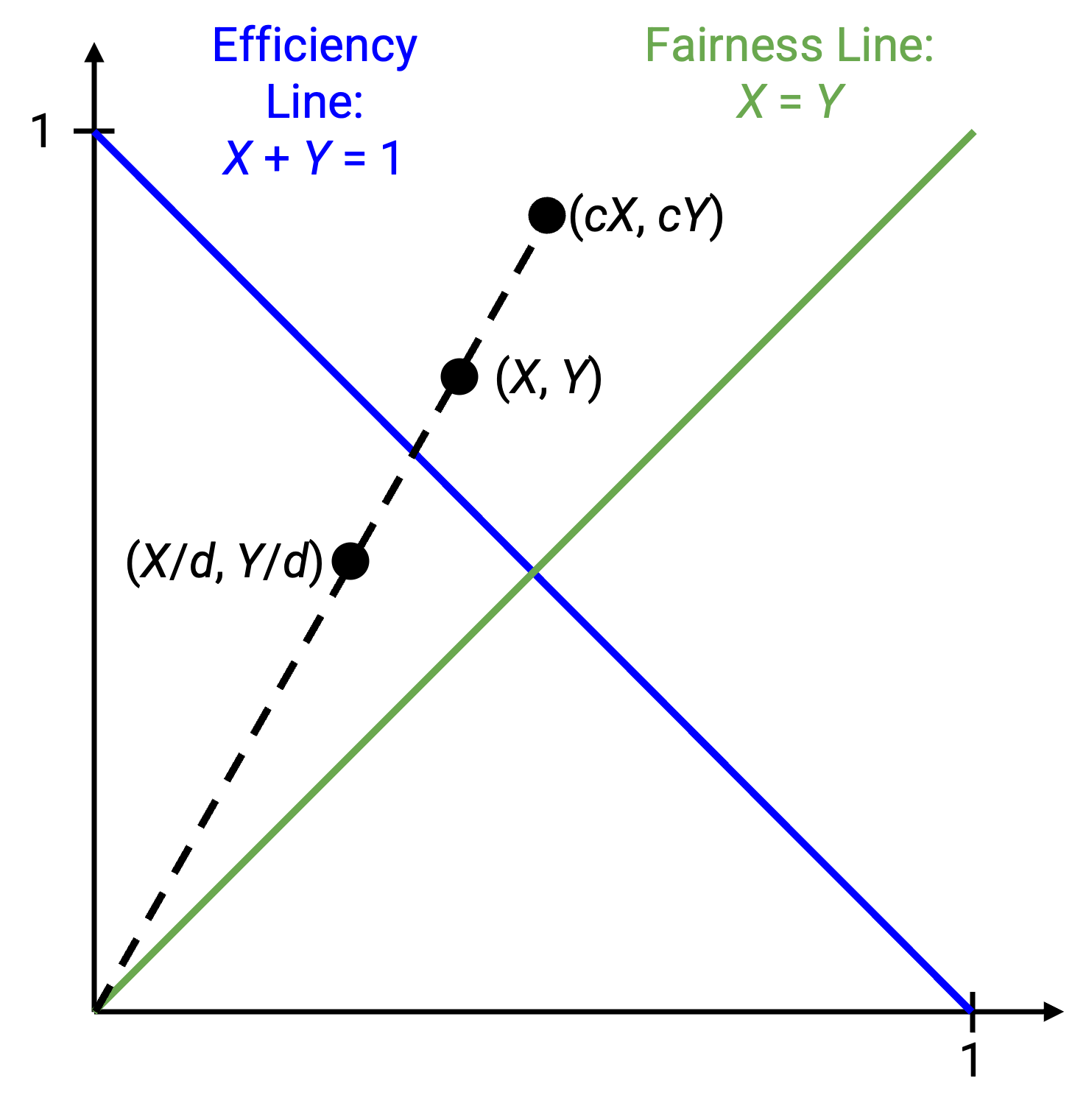
为了可视化可能状态的空间,考虑一个 2D 图,x 轴是 X1(用户 1 的速率),y 轴是 X2(用户 2 的速率)。图上的每个点都表示一种可能场景:每个用户以某个具体速率发送。
假设 C=1。为了实现最大效率,我们希望 X1+X2 = 1。我们可以把这条线画在图上。这条线上的每个点都使用了全部可用带宽。
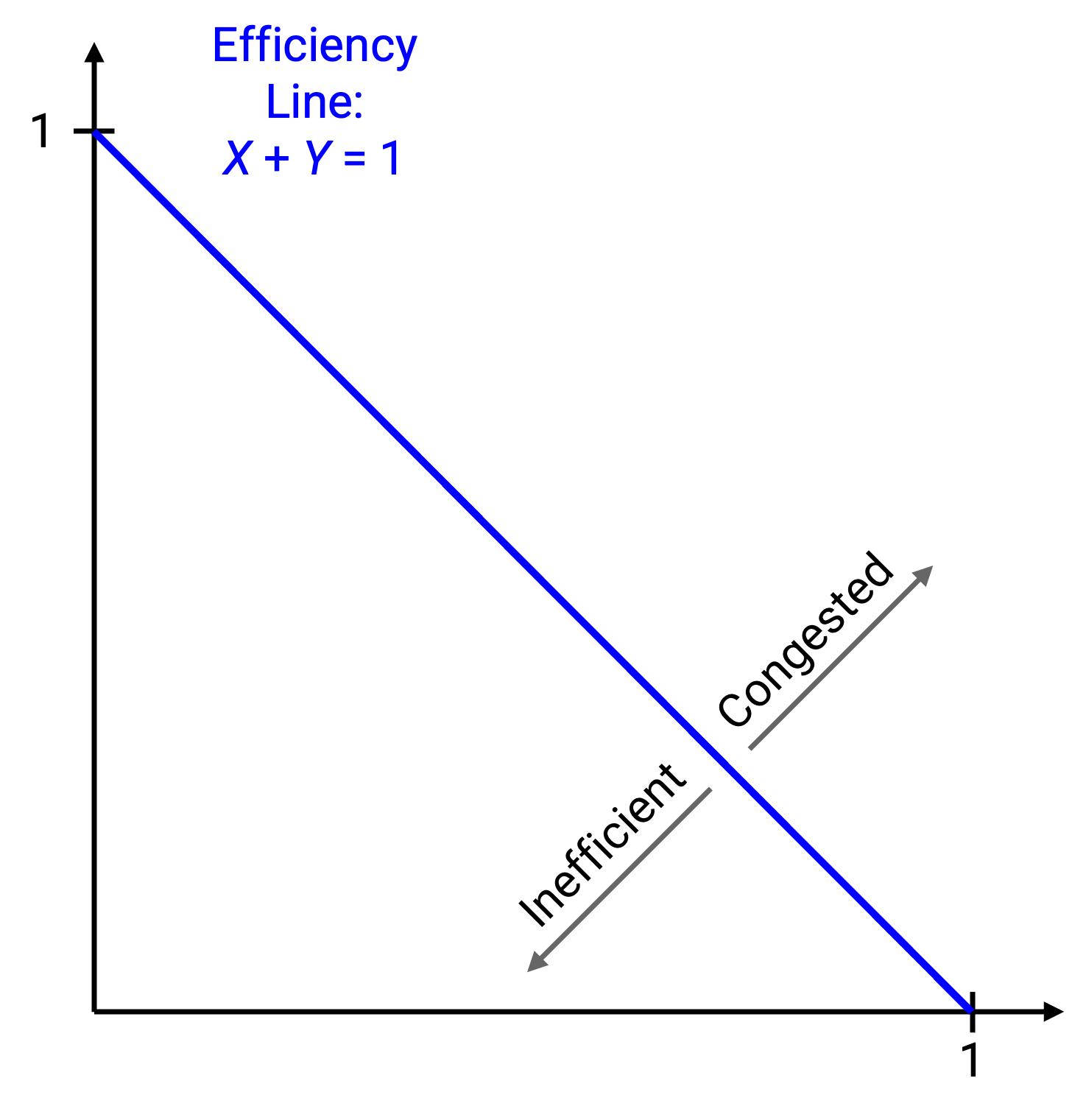
我们知道,当 X1+X2 大于 1 时,网络 congested。在图上,这个不等式对应直线上方的半平面。我们也知道,当 X1+X2 小于 1 时,网络没有被充分使用,对应直线下方的半平面。这意味着直线上方的所有点都表示 congested 状态,直线下方的所有点都表示未充分使用的状态。
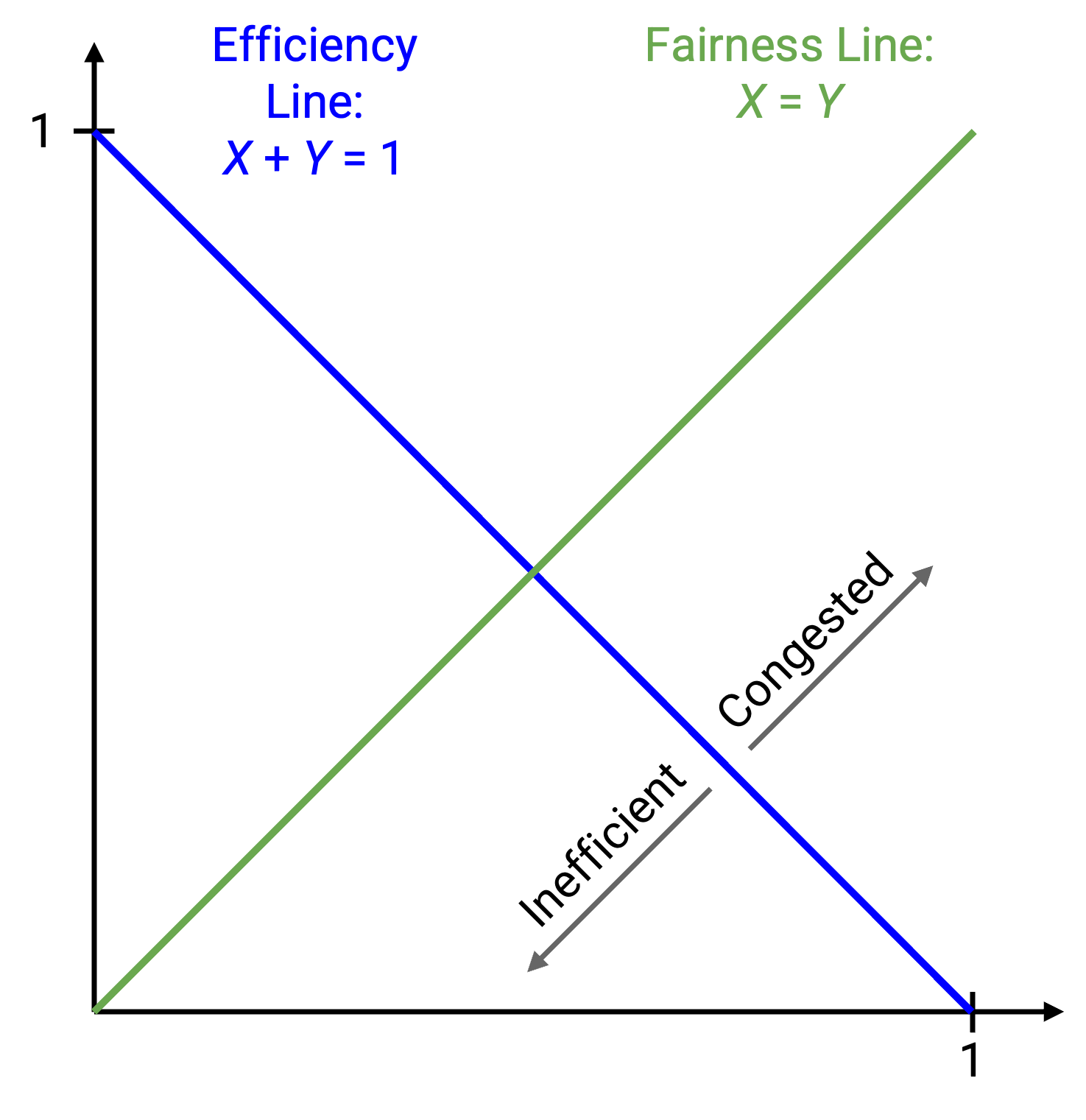
为了实现公平性,我们希望 X1 = X2。我们也可以把这条线画出来。这条线上的每个点都表示一种公平状态,其中两个用户使用相同数量的带宽。不在这条线上的点都是不公平的。
理想状态出现在两条线的交点,也就是 X1 = X2 = 0.5。这个点同时落在两条线上,所以它既公平又高效。
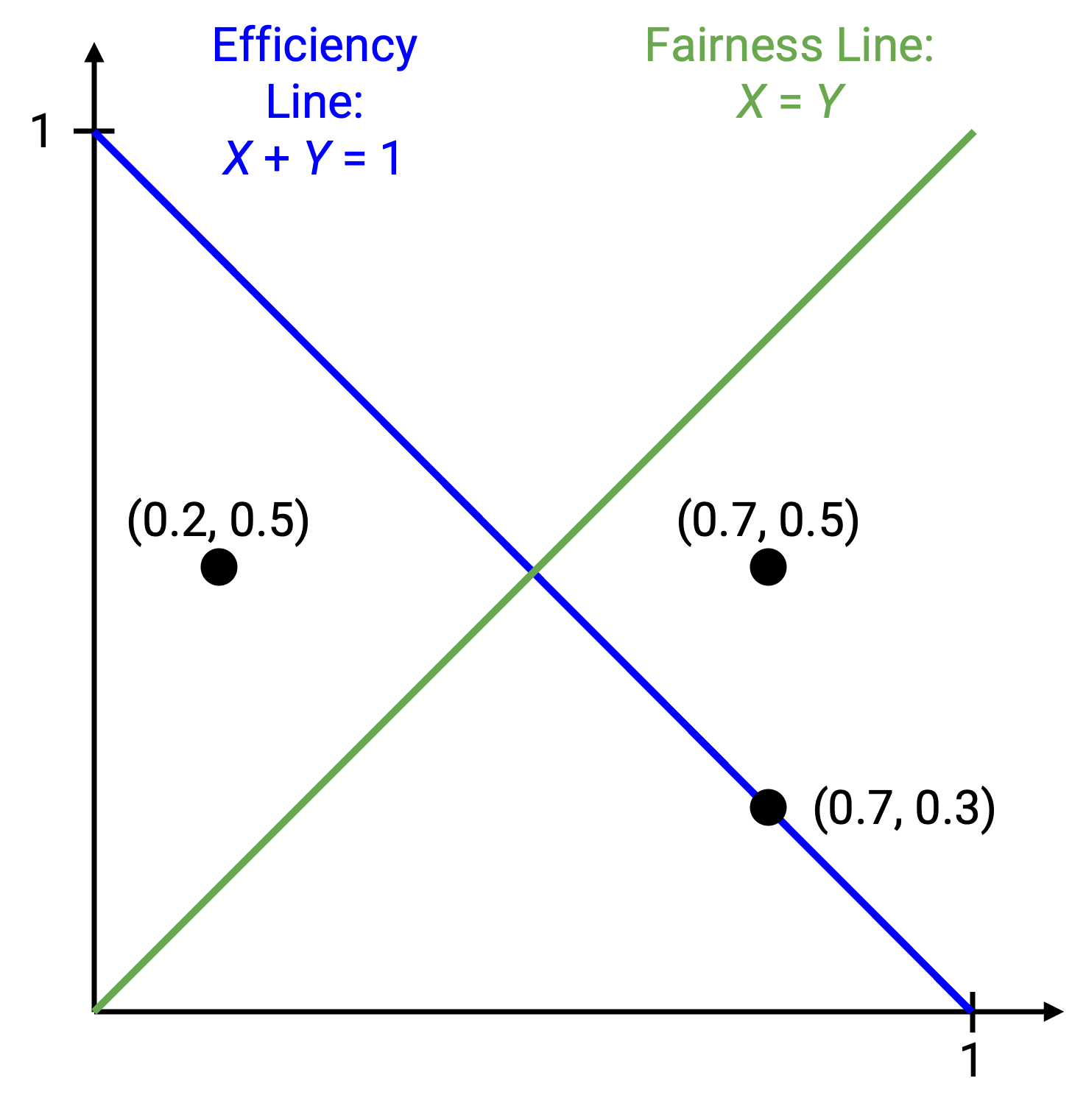
点 (0.2, 0.5) 是低效的,因为我们只使用了 0.7 带宽。从图上看,我们在效率线下方。点 (0.7, 0.5) 是 congested,因此位于效率线上方。点 (0.7, 0.3) 是高效的(在效率线上),但不公平(不在公平线上)。
回忆一下,在我们的动态调整算法中,每个 sender 都独立运行同一个算法来决定自己的速率。这意味着如果两个用户检测到未充分使用,二者都会以相同方式增加速率(加性或乘性,取决于我们选择的规则)。类似地,如果两个用户检测到 congestion,二者都会以相同方式降低速率。
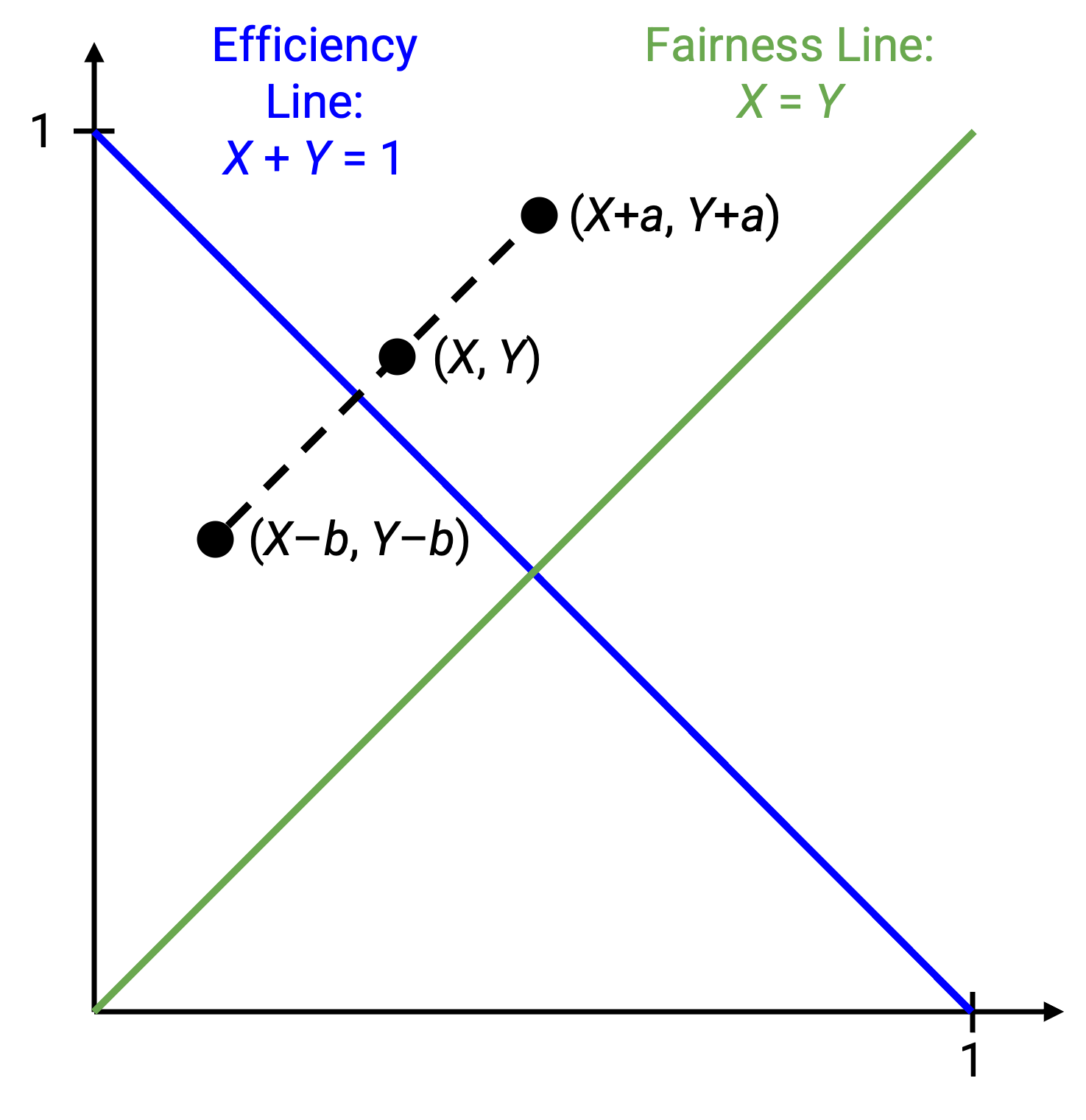
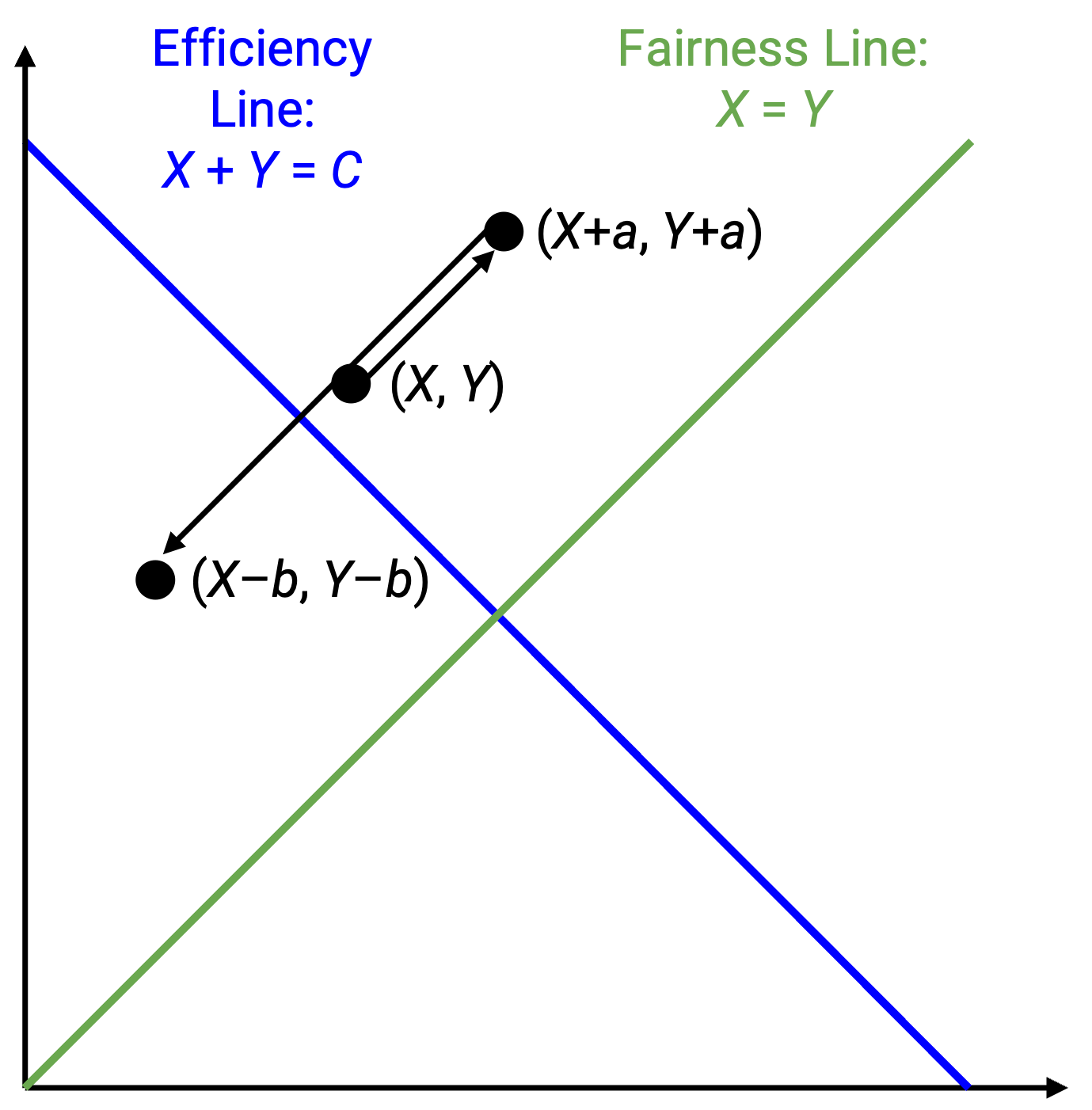
如果两个用户都按加性增加或降低速率,会发生什么?如果两个用户都把速率增加 b,状态 (x1, x2) 会变成 (x1+b, x2+b)。如果两个用户都把速率减少 a,状态 (x1, x2) 会变成 (x1-a, x2-a)。
在图上,如果我们做加性变化,表示当前状态的点会沿着一条斜率为 1 的直线移动。
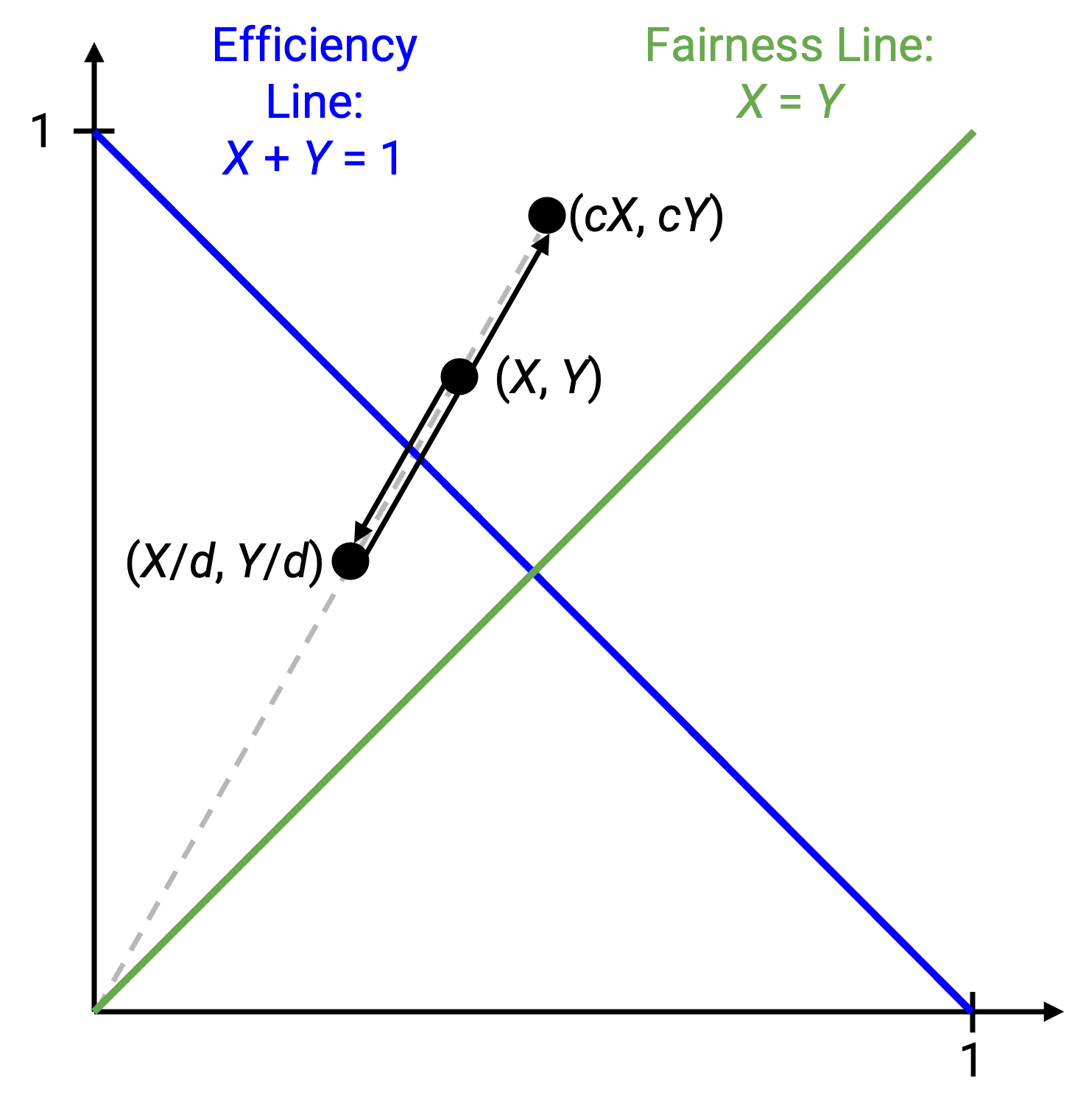
如果两个用户都按乘性增加或降低速率,会发生什么?乘以 c 会把 (x1, x2) 变成 (cx1, cx2),除以 d 会把 (x1, x2) 变成 (x1/d, x2/d)。
在图上,如果我们做乘性变化,表示当前状态的点会沿着一条斜率为 x2/x1 的直线移动。等价地说,这就是连接 (x1, x2) 和原点 (0, 0) 的直线。
现在,我们可以把这个模型应用到四种增加/减少选项上,观察它们会让点接近公平线,还是远离公平线。我们的目标是:随着速率调整,点应该接近公平线。
调整:AIAD 动态¶
考虑每次增加时加 1,每次减少时减 2。假设容量 C = 5。那么从某个起点开始,我们的点会这样移动:
X1 = 1, X2 = 3(起点,4 小于 5,增加)
X1 = 2, X2 = 4(6 大于 5,减少)
X1 = 0, X2 = 2(2 小于 5,增加)
X1 = 1, X2 = 3
我们回到了起点!初始分配并不公平,而几次迭代后,我们又回到了同样不公平的分配。
事实上,如果观察 X1 和 X2 的差距(公平差距为 0),这个差距在每次迭代中都相同(2)。这些迭代不会让分配变得更公平,也不会更不公平。
我们也可以从图上看到这种行为。从某个起点开始,如果按加性方式增加和减少,我们始终沿着斜率为 1 的直线移动,永远不会更接近公平线。
不过也要注意,我们的点确实如预期一样围绕效率线振荡。四种选择都会有这种行为。
我们也可以用代数看到这种行为。假设 X1 和 X2 相差 5(不公平分配)。如果给 X1 和 X2 加上相同数字,得到的 X1' 和 X2' 仍然相差 5(同样不公平)。如果从 X1 和 X2 中减去相同数字,也会发生同样的事。
总结一下,这种方法无法缩小公平差距。如果分配一开始不公平,它就会一直不公平。
你可能会问:如果我们让 X1 增加更多(例如 +2),让 X2 增加更少(例如 +1),会怎样?记住,我们的去中心化方法意味着所有人都在运行同一个算法。在实践中,host 也没有办法知道自己相对于其他 host 应该增加多少。
调整:MIMD 动态¶
考虑每次增加时翻倍,每次减少时除以 4。同样,容量 C = 5。从某个起点开始,前几次迭代是:
X1 = 0.5, X2 = 1(1.5 小于 5,增加)
X1 = 1, X2 = 2(3 小于 5,增加)
X1 = 2, X2 = 4(6 大于 5,减少)
X1 = 0.5, X2 = 1
我们又回到了起点,公平性没有任何改善!
我们可以在图上看到这种行为。当我们按乘性方式增加或降低速率时,我们沿着当前点和原点之间的直线移动,永远不会更接近公平线。
从代数角度看,考虑 X2 和 X1 之间的比值,也就是 X2/X1(公平比值应该是 1)。在上面的例子中,这个比值始终是 2,也就是 X2 的带宽始终是 X1 的两倍。即使把 X1 和 X2 同时乘以或除以常数因子,这个比值也保持不变。我们的调整不会让我们更接近公平比值 1。
调整:MIAD 动态¶
这一种稍微更棘手。考虑每次增加时翻倍,每次减少时减 1。当 C = 5 时,前几次迭代是:
X1 = 1, X2 = 3(4 小于 5,增加)
X1 = 2, X2 = 6(8 大于 5,减少)
X1 = 1, X2 = 5(6 大于 5,减少)
X1 = 0, X2 = 4(4 小于 5,增加)
X1 = 0, X2 = 8
此时,X1 的带宽为零。之后每次翻倍增加,X1 的带宽仍然为零。我们实际上创造了最不公平的情况:X2 拥有所有带宽,而 X1 没有任何带宽。
更一般地说,如果你从不公平分配开始,MIAD 会让分配变得更不公平,最终达到一个人拥有所有带宽、另一个人带宽为零的状态。
为了从代数上看到这一点,考虑 X1 和 X2 之间的差距。当我们翻倍增加时,差距大小也会翻倍,从 (X2 - X1) 变成 (2 X2 - 2 X1) = 2(X2 - X1)。但是,当我们从 X1 和 X2 中都减去 1 时,差距保持不变。差距要么增加,要么保持不变;经过足够多次增加和减少后,差距会达到最大不公平(一方永远拥有零带宽)。
调整:AIMD 动态¶
最后,考虑每次增加时加 1,每次减少时减半。当 C = 5 时,前几次迭代是:
X1 = 1, X2 = 2(3 小于 5,增加)
X1 = 2, X2 = 3(5 不大于 5,增加)
X1 = 3, X2 = 4(7 大于 5,减少)
X1 = 1.5, X2 = 2(3.5 小于 5,增加)
X1 = 2.5, X2 = 3(5.5 大于 5,减少)
X1 = 1.25, X2 = 1.5(2.75 小于 5,增加)
X1 = 2.25, X2 = 2.5(4.75 小于 5,增加)
X1 = 3.25, X2 = 3.5(6.75 大于 5,减少)
X1 = 1.625, X2 = 1.75(小于 5,增加)
X1 = 2.625, X2 = 2.75
我们可以看到 X1 和 X2 越来越接近;事实上,它们正在接近公平分配 X1 = X2 = 2.5。
从代数上也可以看到,X1 和 X2 之间的差距正在减小。具体来说,当我们给两个数字都加上一个常数时,差距保持不变。但是,当我们把两个数字都减半时,差距也减半,从 (X1 - X2) 变成 (X1 / 2 - X2 / 2) = (X1 - X2) / 2。随着我们交替增加和减少,差距会不断减半,并趋近于 0。
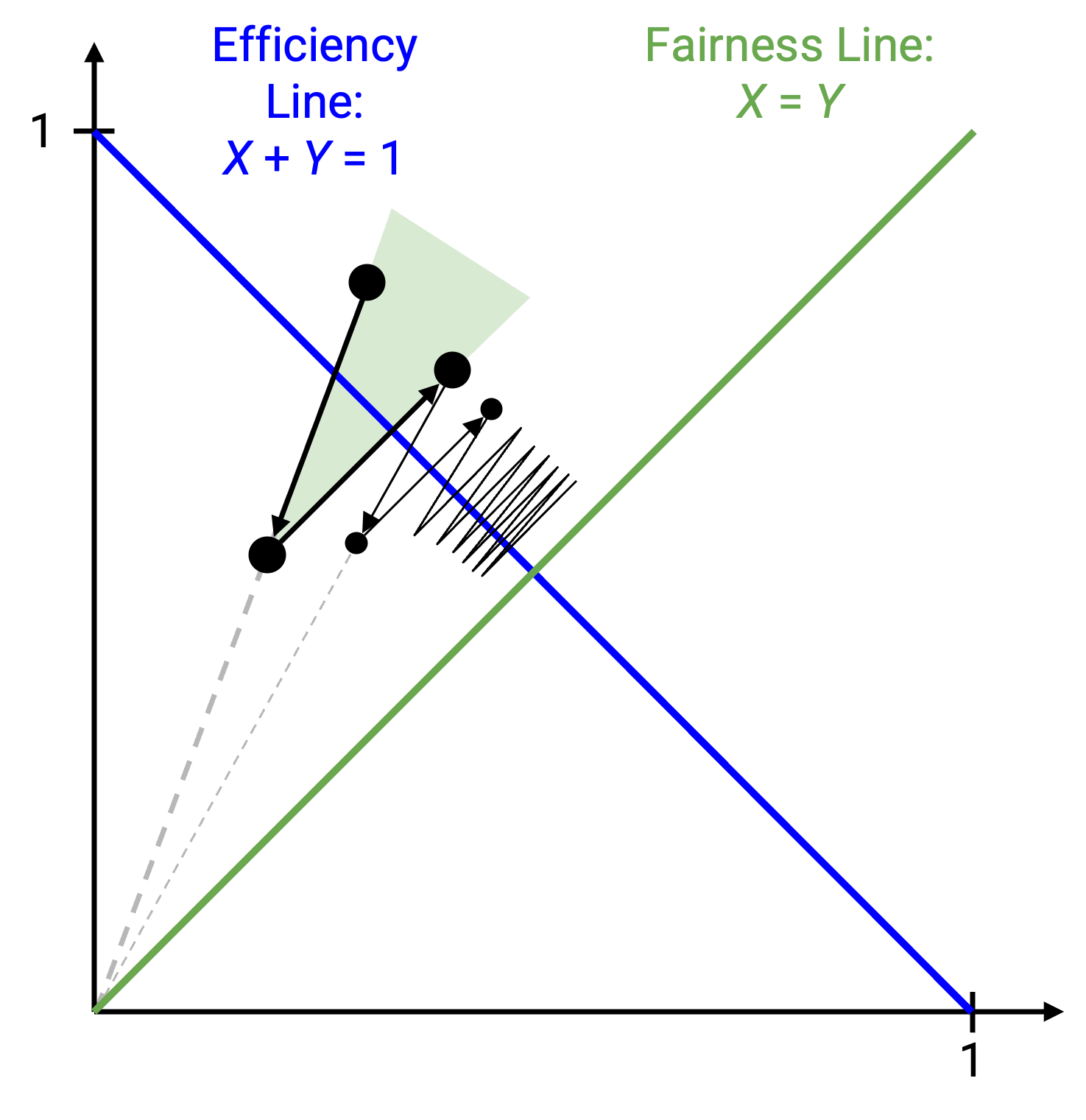
我们也可以从图上看到这一点。当我们按乘性方式减少时,会沿着经过原点的直线移动。这条线朝向公平线倾斜,沿着这条线向下移动意味着我们正在接近公平线。和前面一样,加性增加不会让我们更接近公平线,因为我们沿着一条斜率为 1 的直线移动(与公平线平行)。但关键认识是,加性增加也不会让我们离公平线更远。我们的两个操作只有:更接近,或者既不更近也不更远。经过许多次迭代后,我们的点会缓慢向公平线靠近。
总结一下:AIAD 和 MIMD 保留不公平性,不会改善公平性。MIAD 会增加不公平性,而 AIMD 会收敛到公平状态。