Datacenter 中的 Congestion Control¶
为什么 Datacenter 不同?¶
我们已经看到,相比通用网络,datacenter network 有额外的约束条件(例如物理上位于同一栋建筑中、由同一个 operator 拥有)。这可能产生一些特殊 protocol,用来利用这种网络的特殊性质。在本节中,我们会探索一些 TCP congestion control algorithm:它们可能不适合在通用 Internet 上运行,但在 datacenter 场景中很有效。这仍然是一个活跃的研究和开发领域。
首先,我们应该回答:datacenter 中的 congestion control 有什么不同?
回忆一下,packet delay 包括 transmission delay(把 bit 发送到链路上的时间,由 bandwidth 决定)、propagation delay(bit 在线路上传播的时间)和 queuing delay。
在 datacenter 中,transmission delay 通常相对较小(记住,我们有高容量的 10 Gbps link)。Datacenter 中的 propagation delay 也相对较小(记住,所有 server 都在同一栋建筑里)。因此,在 datacenter 中,queuing delay 往往是 delay 的主要来源。相比之下,在 wide-area Internet 中,propagation delay 可能大几个数量级(例如 packet 可能必须跨越整个国家),也更常成为 delay 的主要来源。
回忆一下,TCP congestion control 会有意填满 queue,直到 packet 丢失(我们通过检查 loss 来检测 congestion)。TCP 的设计者没有考虑 datacenter 场景,而在这里 queuing delay 对性能的影响可能要大得多。
大 queue 的问题在 datacenter 中会进一步加剧,因为与 wide-area Internet 不同,大多数 datacenter connection 属于两类之一。大多数 connection 是 mice,也就是短且对 latency 敏感的连接。例如,网页搜索查询和结果页只包含很少的数据,但我们希望非常快地把结果返回给用户。相比之下,一些 connection 是 elephants,也就是大且对 throughput 敏感的连接。例如,把数据从一台 server 备份到另一台 server,需要一个长时间运行的 connection,以高 throughput 发送大量数据。
如果对这两类 connection 运行 TCP congestion control,elephant 会不断提高自己的 rate,直到所有 queue 都被填满。此时,后续任何 mouse 都会卡在 queue 中,导致 mouse 被延迟。
为了针对这些特定类型的 connection 最大化性能,datacenter congestion control algorithm 必须避免填满 queue。近些年已经提出了很多 datacenter 专用的解决方案。
例如,Google 在 2016 年发布了 BBR。在这种方法中,我们不再通过检查 loss 来检测 congestion(这要求 queue 已经满了),而是通过检查 packet delay 来检测 congestion。
DCTCP:来自 Router 的反馈¶
DCTCP(Datacenter TCP)由 Microsoft 在 2010 年发布,现在已经被广泛使用(例如在 Linux kernel 中实现)。
回忆一下,IP header 有一个 ECN bit,router 可以启用这个 bit 来表示自己发生了 congestion。当 packet 到达 destination 时,ack 也会设置 ECN bit,这会告诉 sender 减速。
在 DCTCP 中,当 queue length 超过某个 threshold 时,router 会启用 ECN bit。这让 sender 能更早地检测并适应 congestion(也就是在 queue 正在变满、但还没有完全填满时)。
作为对 congestion 的响应,sender 会按照带有 ECN 标记的 packet 数量成比例地降低 rate。这让 sender 能更温和地适应 congestion。sender 不再只能做二元决策(有 congestion 或没有 congestion),而是可以检测到可能正在发生一些 congestion,并稍微降低 rate 来补偿。
ECN bit 在 wide-area Internet 中效果不太好,因为并不是所有 router 都支持它。不过,在 datacenter 中,operator 控制所有 switch,并且可以让它们以一致方式切换 ECN。在实践中,在 host 和 router 上实现 DCTCP 是一个相对较小的改动。
为了衡量 DCTCP 的性能,我们可以测量 flow completion time(FCT,flow 完成时间),它表示从第一个 byte 被发送到最后一个 byte 被接收之间的时间。作为 benchmark,理想 FCT 是使用一个全知 scheduler 时的完成时间,这个 scheduler 拥有整个网络和所有 connection 的全局知识。然后,scheduler 可以利用这些知识最优地调度 flow,并为 flow 分配 bandwidth。
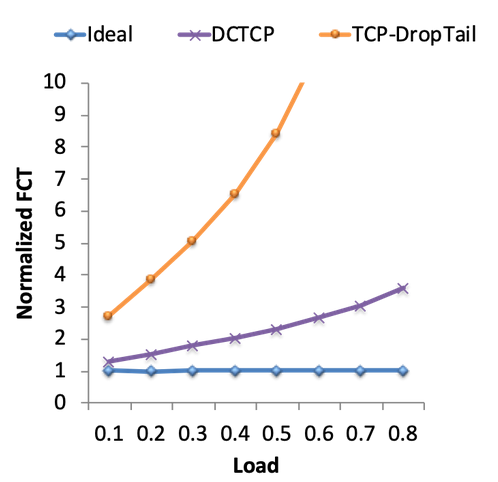
这张图展示了 normalized FCT,也就是实际 FCT 与理想 FCT 的比值。它告诉我们,相比理想 congestion control algorithm,我们差了多少。可以看到,标准 TCP congestion control 比理想情况差 3 倍;如果网络负载更高,最多会差 10 倍。相比之下,DCTCP 明显优于标准 TCP congestion control。DCTCP connection 完成得快得多,queuing delay 也更低。
pFabric:Packet 优先级¶
我们看到,datacenter 中的问题是 mouse 可能被 elephant 堵在 queue 后面。如果我们给 mouse 某种方式,让它们可以跳到 queue 前面、更快完成,会怎么样?
为了优先处理 mouse,我们会给每个 packet 分配一个 priority number。priority 由剩余 flow size(未确认 byte 的数量)计算得到。数字越小,priority 越高。
在这个系统中,mouse packet 会有高 priority(flow size 很小)。Elephant 会有低 priority,不过 elephant connection 最后的几个 byte 会有更高 priority。这会产生一种效果:优先处理快要完成的 connection(即使它们属于更大的 elephant connection)。
为了实现这个想法,回忆一下,IP packet header 有一些字段可以表示 packet 的 priority。在 pFabric 中,每个 packet 携带一个 priority number,并且 switch 会被修改为发送 priority 最高的 packet。如果 queue 已满,switch 会丢弃 priority 最低的 packet。
有了 priority system 后,sender 现在可以安全地以 full line rate 发送和重传 packet,而不需要为了 congestion control 调整自己的 rate。sender 只需要在极端 loss 情况下(例如 timeout)降低 rate。
如果再次看 FCT 图,我们会看到 pFabric 的性能甚至比 DCTCP 更好,并且非常接近理想情况。
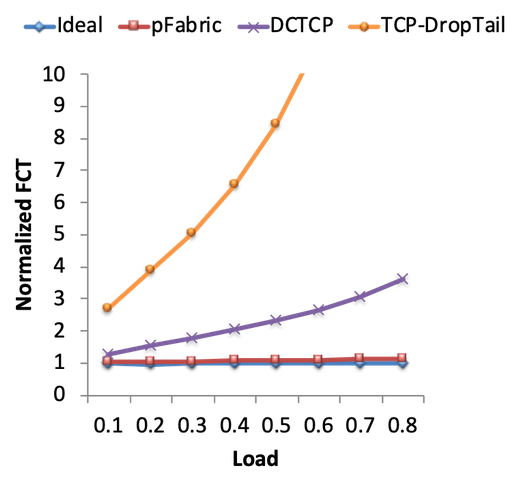
为什么 pFabric 效果这么好?Elephant 和 mouse 一起传输,并且所有人都以 full line rate 发送,这保证了可用 bandwidth 被充分利用。我们不必在 slow start 上浪费时间。同时,由于大型 elephant 中的大多数 packet priority 都很低,我们可以避免 collapse。Priority system 确保 mouse packet 仍然能以低 latency 穿过 queue。
实现这个系统需要对 switch 和 end host 都做非平凡的改动,并且要求完全控制 switch 和 end host。Switch 需要实现 priority system,sender 需要替换自己的 TCP 实现,以 full line rate 发送。尽管如此,pFabric 仍然是 network(switch)和 end host 协作以获得良好性能的一个好例子。