Collective Operations¶
动机:AI Training¶
你可能已经在新闻中读到过,AI(artificial intelligence)是一个非常活跃的研究领域。现代 AI system 需要在海量数据上训练 model。
在这份 notes 中,我们会完全忽略这些 model 如何工作的细节。你只需要知道:我们从某个未训练的 model 开始,可以把它想象成一个填满随机数的大 matrix。然后,我们用大量 training data 来训练这个 model,可以把这个过程想象成让 training data 和 model 执行许多 matrix multiplication operation(也就是乘法和加法)。最终输出是一个 trained model,可以把它想象成前面那个大 matrix,但现在里面填的是有用的数字。

现实中,AI training 远比这复杂。例如,training process 是 iterative 的:你会在一些 training data 上运行 model,看看效果如何。然后,你会根据犯下的 mistake 计算 error term,并用它更新 model。我们不关心这些细节。这里我们只把 training 看成一个 black box,它会在非常非常大的 dataset 上运行大量 matrix multiplication。
Distributed Training¶
AI training job 太大,无法在单台 computer 上串行运行。如果你一次只把两个数相乘来执行 matrix multiplication,training job 永远不会完成。相反,我们需要 parallelize 这些 job,让许多 operation(例如 multiplication)同时运行。distributed computing(分布式计算) 有许多方法,每种方法都沿着不同维度 parallelize job:
我们可以拆分 training data,让每个 node 在 data 的不同 subset 上训练。
我们可以拆分 model 本身,让每个 node 训练 model 的不同 subset。
我们可以 pipeline operation,让每个 node 运行 operation 的不同 subset。例如,如果目标 operation 是先「add 5」,再「square the number」,我们可以把它拆开:你的 node 执行加法,然后把结果传给我,让我的 node 执行平方。这样,每一份 data 都先经过你的 node,再经过我的 node,完成整体 operation。
同样,我们会完全忽略 work 如何分布的细节。我们有一个大型 task,它已经被拆成更小的 sub-task。
我们关心的一件重要事情,是这些 node 如何彼此 synchronize。这些 node 通常需要互相通信,以确保它们的 state 保持一致。另外,运行某个 operation 后,可能每个 node 都持有 output 的一部分,所有人需要协调,把这些部分组合成完整 output。
把 training model 的图像和 distributed computing 的图像结合起来,我们就能得到 distributed training 的高层概览:
-
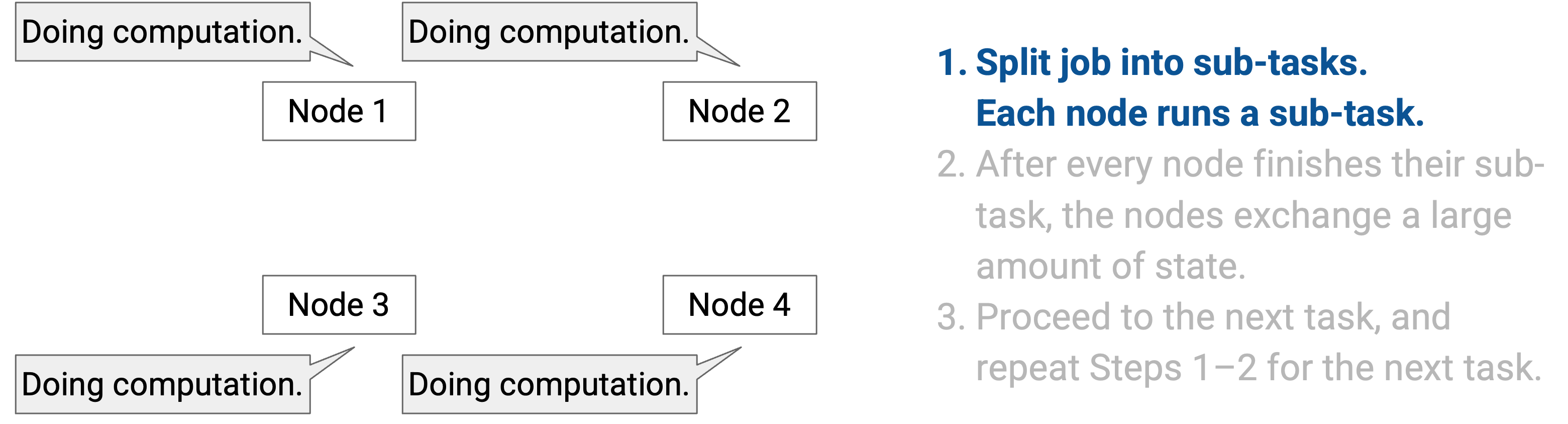
把 task 拆成 sub-task。每个 node 运行一个 sub-task。
-
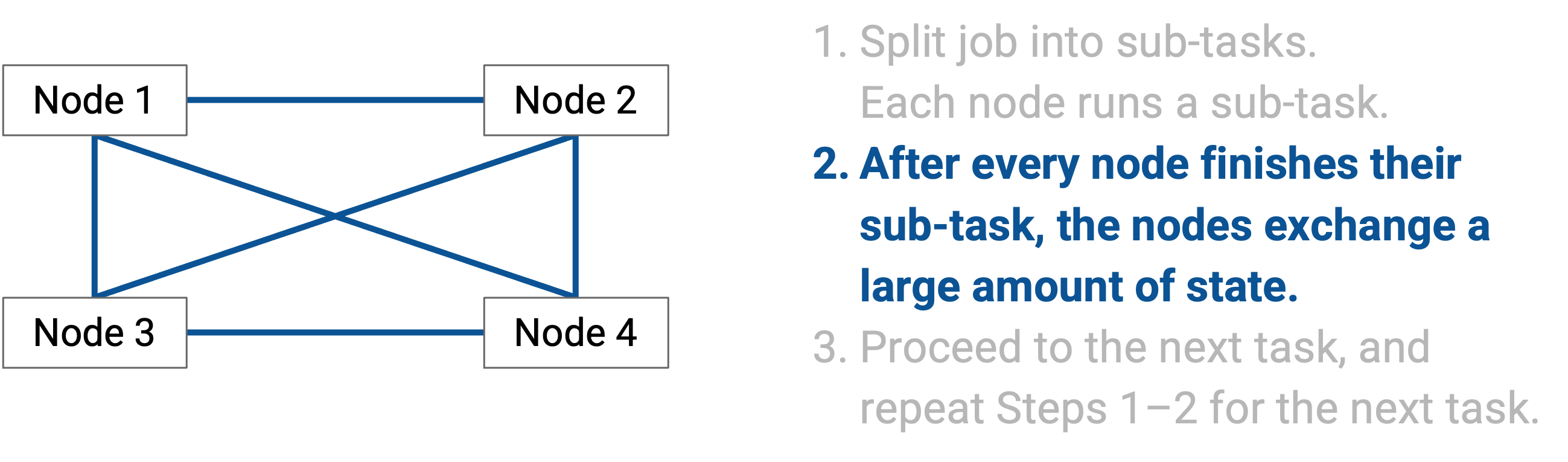
每个 node 完成自己的 sub-task 后,所有人交换大量 state。
-
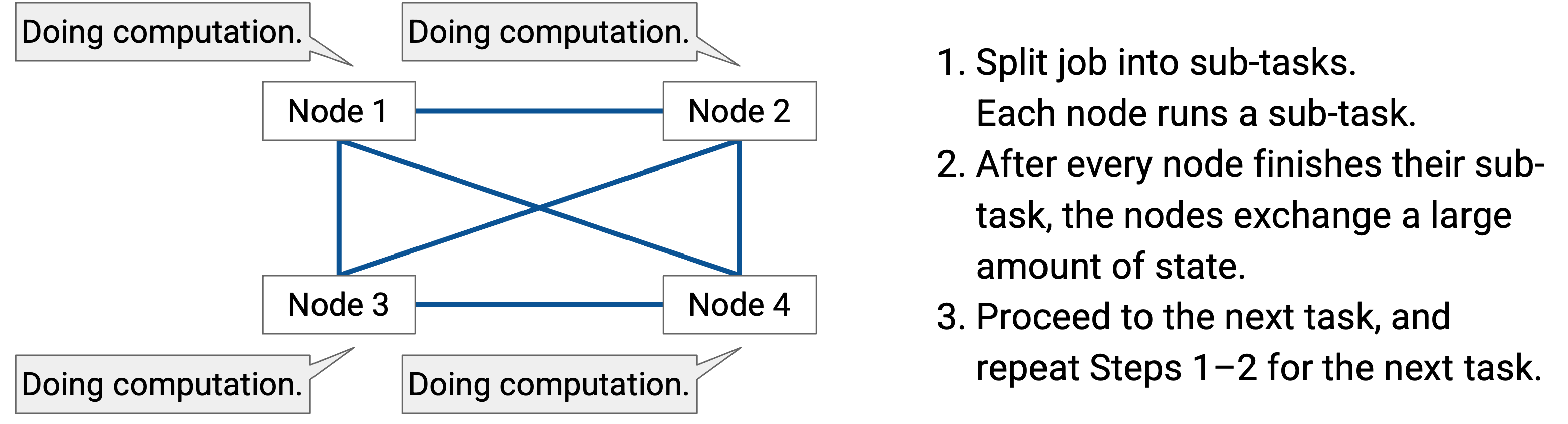
进入下一个 task,并为下一个 task 重复步骤 1-2。
我们的关注点是第二步中的 data exchange,以及如何让这个 data exchange 高效。
同样,我们并不关心具体交换的 data 是什么。根据我们如何分配 work,以及根据正在构建的具体 AI model,交换 data 的性质可能略有不同。我们关注的是这些 data 如何被交换。
Distributed Training Infrastructure¶
当我们把一个 training job 拆分到许多 node 上时,每个 node 到底是什么?
每个 node 可以是一台运行标准 CPU 的 computer,但现实中,node 通常是专门的 GPU (Graphics Processing Unit)。这些 processing chip 专门设计用于高效运行 AI operation(例如 matrix multiplication)。除了 GPU,node 也可以是 TPU (Tensor Processing Unit),也就是 Google 开发的面向 AI 优化的 chip。
一个 training job 可能运行在几百个 node 上,甚至运行在数万个 node 上,这取决于 job 的规模和背景,以及每个 node 有多强。
这些 GPU 通过一种类似 datacenter 的 network 互连,这给了我们之前见过的 datacenter 优势:node 在物理上彼此接近(例如在同一栋建筑中);node 按结构化 topology 组织(例如 Clos network);node 是 homogenous 的(都按相同方式构建);link 具有非常高的 bandwidth。
如果你观察一个 AI training datacenter 内部,会看到 server 像其他 datacenter 一样组织成 rack。不过,与目前见过的其他 datacenter 不同,每台 server 包含一个或多个用于 AI computation 的 GPU。server 也可以有一个普通 general-purpose CPU 来处理杂项 operation,不过这个 CPU 通常并不强,也不是主要 computation work 的承担者。server 上的所有 GPU 使用同一个 NIC 与其他 server 交换 data。
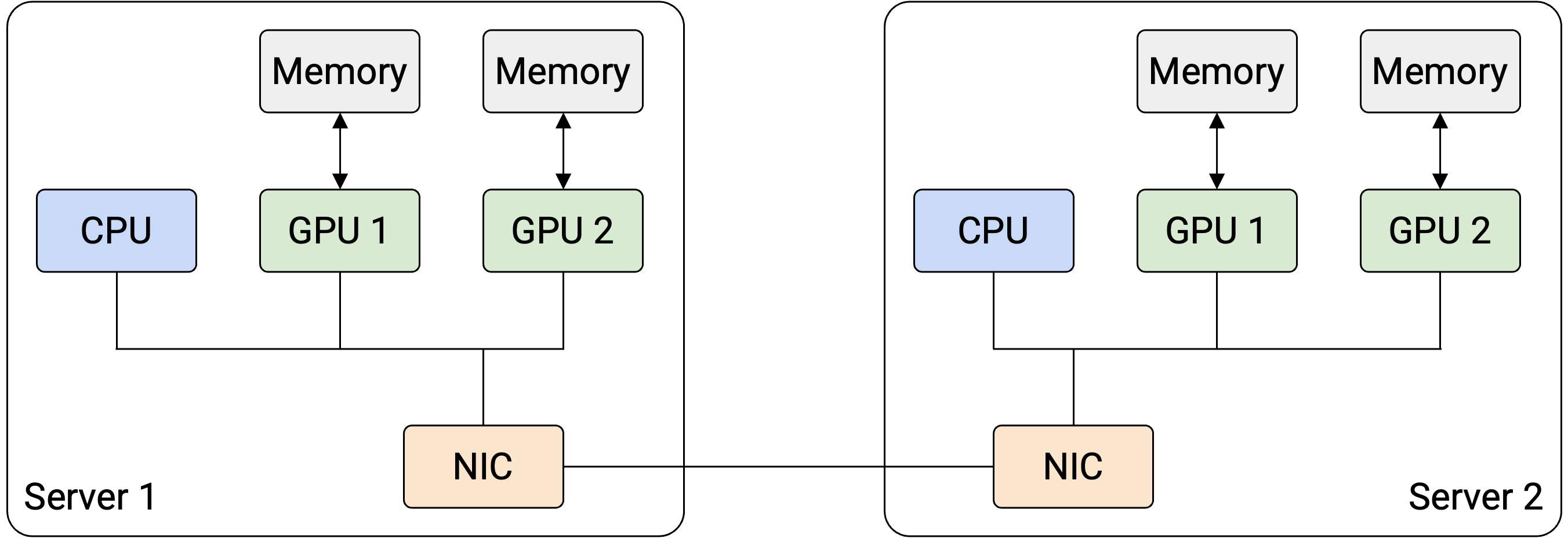
因为每台 server 有多个 GPU,我们需要稍微修改 network topology abstraction。和以前一样,server 通过 switch 和 high-bandwidth link 连接。不过,现在还需要考虑同一台 server 上两个 node 彼此通信的可能性。与跨 server 通信相比,同一台 server 内部的通信极其高效,所以我们可以把 intra-server communication 建模成一条具有无限 bandwidth、零 latency 的 link。
每个 GPU 可以拥有自己的 dedicated memory,并且可以使用 RDMA 等技术,加速把 data 从一个 GPU 的 memory 传输到另一个 GPU 的 memory。
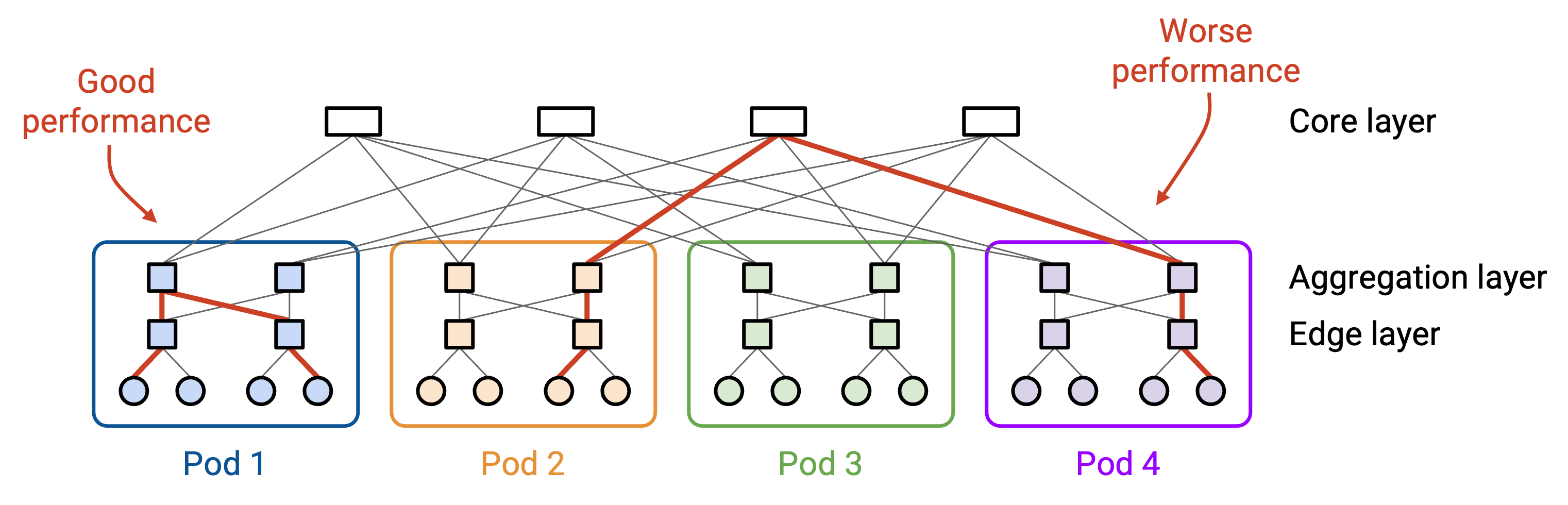
rack 之间有许多不同 inter-connection topology,不过在这里,我们会用 fat-tree Clos topology 来连接 rack。无论使用哪种 topology,有些 GPU pair 会更接近,例如同一台 server 中的 GPU 完全不需要使用 network 就能通信;有些 GPU pair 会更远,例如不同 server 但在同一 pod/rack 中,通过一个 switch 连接;还有些 GPU pair 最远,例如在不同 rack 中,需要经过 multiple hops。相较于更远的 GPU pair,更近的 GPU pair 可以用更高 bandwidth、更低 latency 通信。总结一下,如果任选一对 node,有些 pair 的连接质量会比其他 pair 更好。
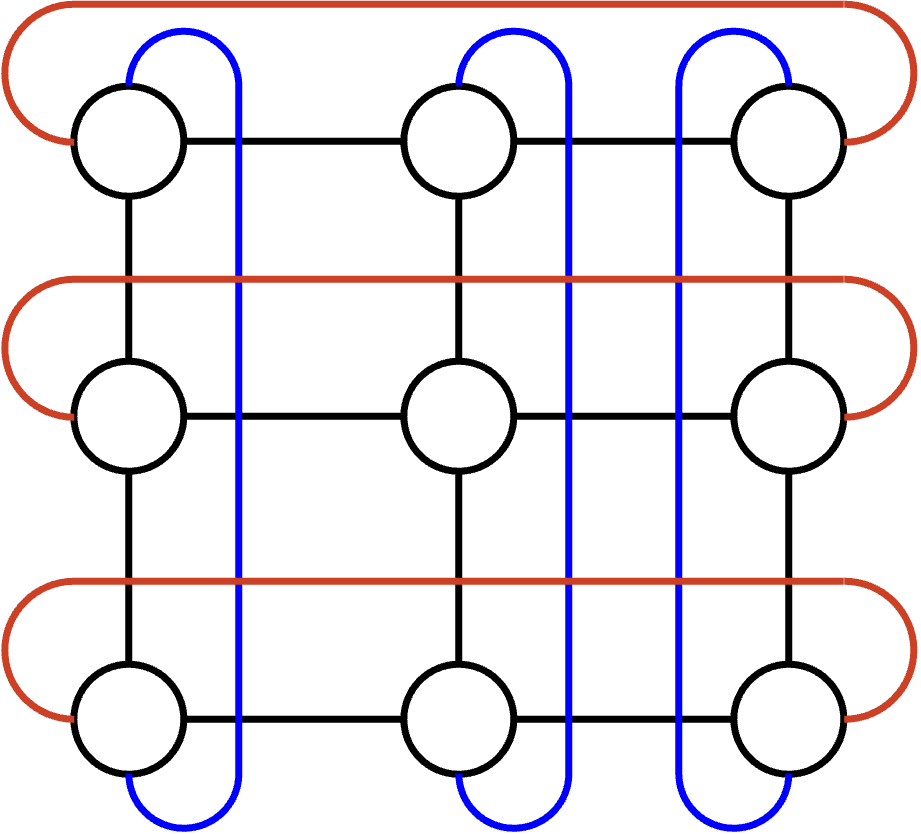
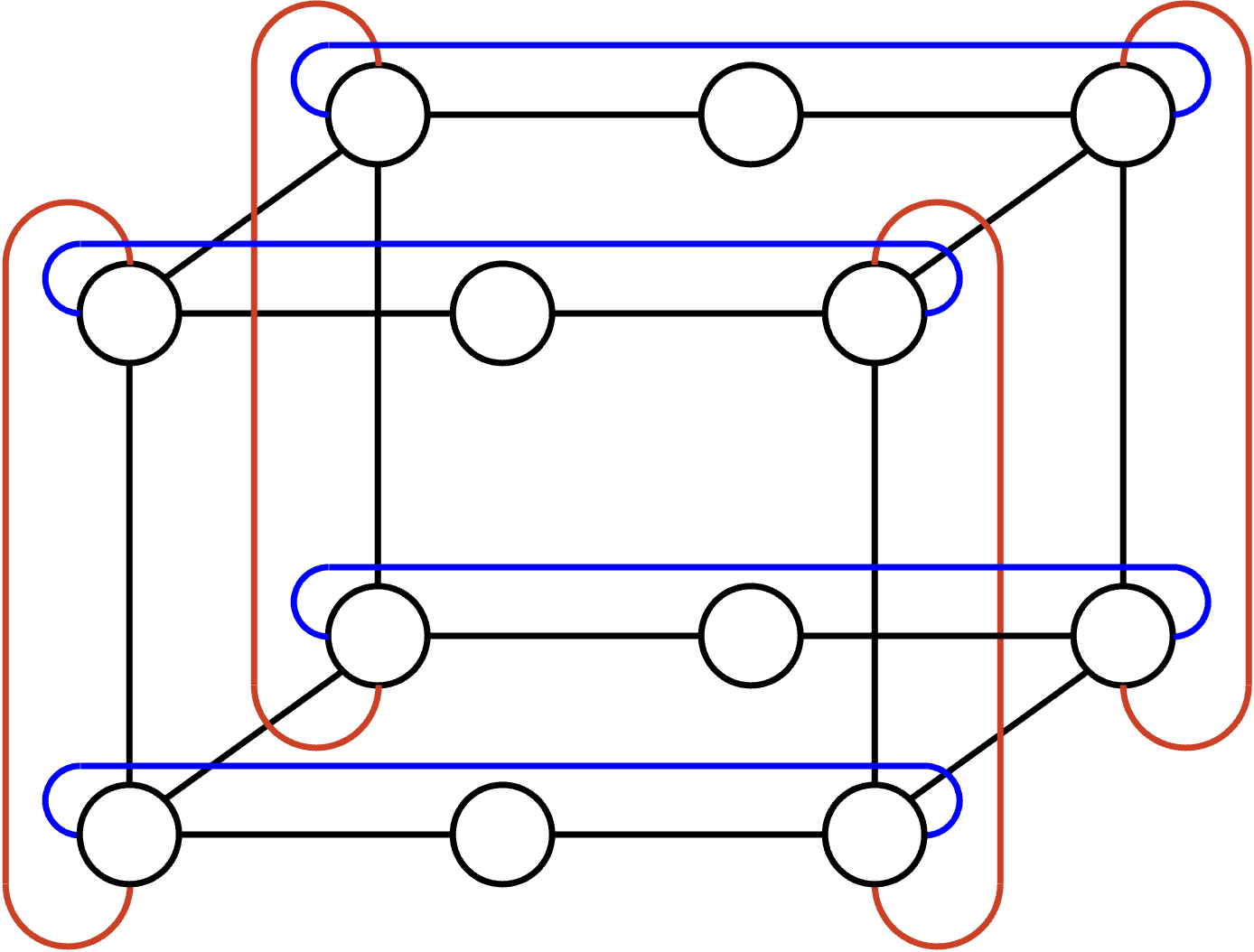
也存在其他 topology。TPU 直接内置 router,所以可以把 TPU 直接连接成 network,而完全不需要 switch。TPU 的一种常见 topology 是把它们互连成 3D torus,看起来像一个边缘会 wrap around 的立方体。例如,如果你到达立方体顶部并沿着向上的 link 继续走,就会到达立方体底部。或者,如果你到达立方体前面并沿着朝前的 link 继续走,就会到达立方体后面。和 Clos topology 一样,有些 node pair 更近(例如 direct neighbor),而另一些 node pair 更远(例如隔着 multiple hops)。
Collective Communication:定义¶
现在我们知道了 task(distributed computing)以及运行 task 的 infrastructure(由 GPU/TPU 构成的、类似 datacenter 的 network),就可以形式化定义我们想解决的问题。
collective communication 的 textbook 定义是:一组 node 作为 group computation 的一部分,以协调的方式交换 data。非正式地说,它的意思是许多 node 为了实现共同目标一起工作,并且这些 node 在过程中必须交换 data。
collective communication 背后的思想和术语,最早是在几十年前 supercomputer 的背景中发展出来的。由于 AI 的最新进展,这个话题再次成为活跃的研究领域。现代 Collective Communication Library 的实现包括 NCCL (Nvidia)、MSCCL (Microsoft)、TCCL (Thunder Research Group) 等等。如果你感兴趣,NCCL 的代码可以在线查看。
collective communication 和我们到目前为止见过的东西有什么不同?这里会看 3 个主要差异。
Highly structured communication: 到目前为止,当我们思考 network 时,我们会抽象掉正在交换的 data。我们事先不知道谁想通信,并且会构建 network,让任意一对 host 可以在任意时间通信。
相比之下,在 collective communication 中,node 想达成一个非常具体的目标,而且这个目标是事先已知的。这意味着,和一般 Internet 不同,我们非常清楚通过 network 交换的 data 结构是什么,以及这些 data 需要在什么时候交换。换句话说,所有 node 会共同执行一组精确编排好的 data exchange 和 computation。
Dedicated network infrastructure: 到目前为止,我们构建的 network 可以支持多条 connection 同时发生。即使在 datacenter network 中,也可能有多个 tenant 同时通过 datacenter network 发送 data。
相比之下,AI training job 非常大,通常会运行在 dedicated infrastructure 上。training job 是这个 network 上唯一运行的 job,没有其他 data 通过这个 network 发送。这意味着我们可以准确预测任意时刻正在使用多少 bandwidth。
Data 在交换过程中会被转换: 到目前为止,当我们思考通过 Internet 发送 data(例如 HTTP/TCP/IP stack)时,心智模型是 server 拥有一些 data(例如一个 file),并想把这些 data 的副本发送给 user。
相比之下,运行 collective operation 时,data 可以在通过 network 发送的过程中被转换。这和我们之前见过的任何东西都不同。这些 operation 通常相当简单,例如计算 sum,但这意味着 sender 发送的 data 不一定等于另一端收到的 data。
我们可以为每个要构建的 AI model 从头设计一套 coordinated communication scheme,但这会很繁琐,并导致大量重复工作。因此,我们会定义一组基本 communication pattern,称为 collective。然后,我们可以把这些 collective 当作 building block,为具体 job 设计 coordinated communication scheme。你可以把 basic collective operation 理解为 distributed communication 的 API,例如提供给 user 使用的 library function。随后,user 可以用各种方式调用这些 collective function,实现自己的具体目标。
事实证明,我们只需要相对少量的 primitive collective operation,AI training 中的大多数 task 都可以拆解成这些 operation,并表示为这些 operation 的各种组合。
我们的关注点是这些 collective 是什么,以及它们如何在 network 中实现。我们不会讨论为什么 AI training 会产生这些特定 collective operation。之所以选择这些 operation 作为基本 building block,更多与 AI computation 的性质有关,这超出了我们的范围。
Collective Operations:设置
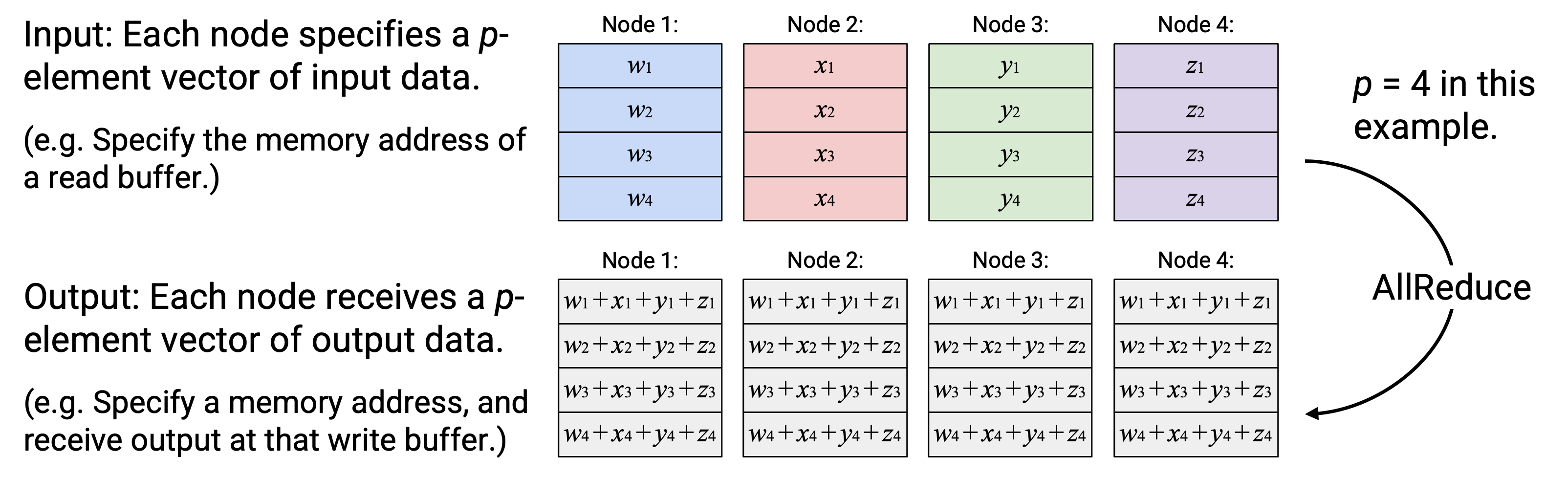
现在我们会定义 7 个基本 collective operation。我们会通过指定 input(operation 之前每个 node 持有的 data)和对应 output(operation 之后每个 node 持有的 data),来定义这些 operation 应该做什么。这里不会说明 operation 如何在 network 中实现,这部分稍后再讲。
Input: 有 \(p\) 个 node。在示例中,我们会设 \(p=4\),但其他值也可以。
每个 node 都有一个包含 \(p\) 个 element 的 data vector。在这些例子中,你可以把 data 想象成一个包含 4 个 integer 的 array。实践中,这些 data 也可以是更高维的,例如 matrix 的 4 行,或者 training data 的 4 个等大小 chunk。
Output: element 会以某种指定方式在 node 之间移动。output 指定这个 operation 结束后,哪些 value 应该进入哪些 box。
另外,有时 element 可以被 aggregate(例如求和)。同样,output 会指定这个特定 operation 执行哪些 computation(如果有的话),以及 computation result 应该放进哪些 box。
在 collective operation 发生之前,需要先做一些额外协调,让每个 node 知道自己的编号和 node 总数,例如「你是 node 1,总共有 4 个 node」。这些额外协调超出了我们的范围,但你可以想象某个 centralized scheduler 或 controller 会把这些信息分发给 node,并设置 job。
为了执行一个 collective operation,每个 node 会并行、同时运行完全相同的 code。所有 node 都独立调用同一个 collective operation 来启动 operation;当 operation 完成时,output 应该与 operation definition 匹配。理想情况下,node 拥有相同的 hardware resource,因此会同时完成。如果某些 node 比其他 node 慢,那么 operation 是 blocking 的,也就是说,我们必须等待所有人完成 operation,才能进入下一个 task。
总结一下,collective operation 由 controller 编排,controller 会设置 job。operation 是 synchronized 的(所有人同时开始)、homogenous 的(理想情况下所有人同时完成),并且是 blocking 的(必须等待所有人完成才能继续)。
设置完成后,我们就可以看这 7 个 collective operation 如何定义。它们大致可以分为两类:4 个 operation 关于 redistribution(移动 data,但不转换 data),3 个 operation 关于 consolidation(把多份 data aggregate 成单个 output)。
Operation:Broadcast
英文描述:取指定 root node 中的整个 vector,并把这个完整 vector 的副本发送给每个 node。
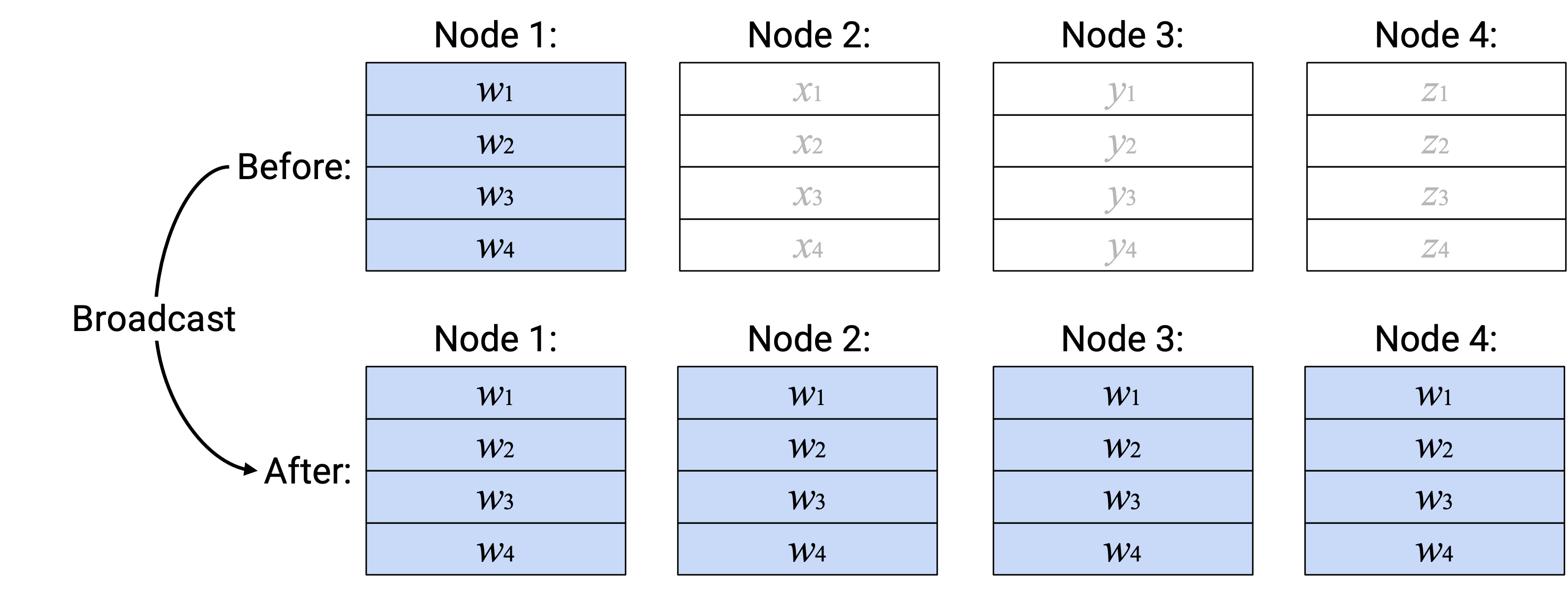
注意:这张图展示的是以 Node 1 为 root node 的 Broadcast operation,但我们也可以用不同 root node 执行这个 operation。运行 Broadcast operation 的 user 必须把 root node 指定为 operation 的一个「argument」。
注意:non-root node 中的 input vector 不用于创建 output。你可以把它们想成 function 中实际不会被使用的 argument。
注意:每个 node 的 input vector 和 output vector 不一定要存储在同一位置。如果使用同一个 memory address 同时保存 input 和 output vector,那么某些 operation(例如 Broadcast)会用 output data 覆盖 input data。另一种做法是使用不同 memory address 保存 output vector。
Operation:Scatter
英文描述:取指定 root node 中的整个 vector。把这个 vector 的第 \(i\) 个 element 发送给第 \(i\) 个 node。
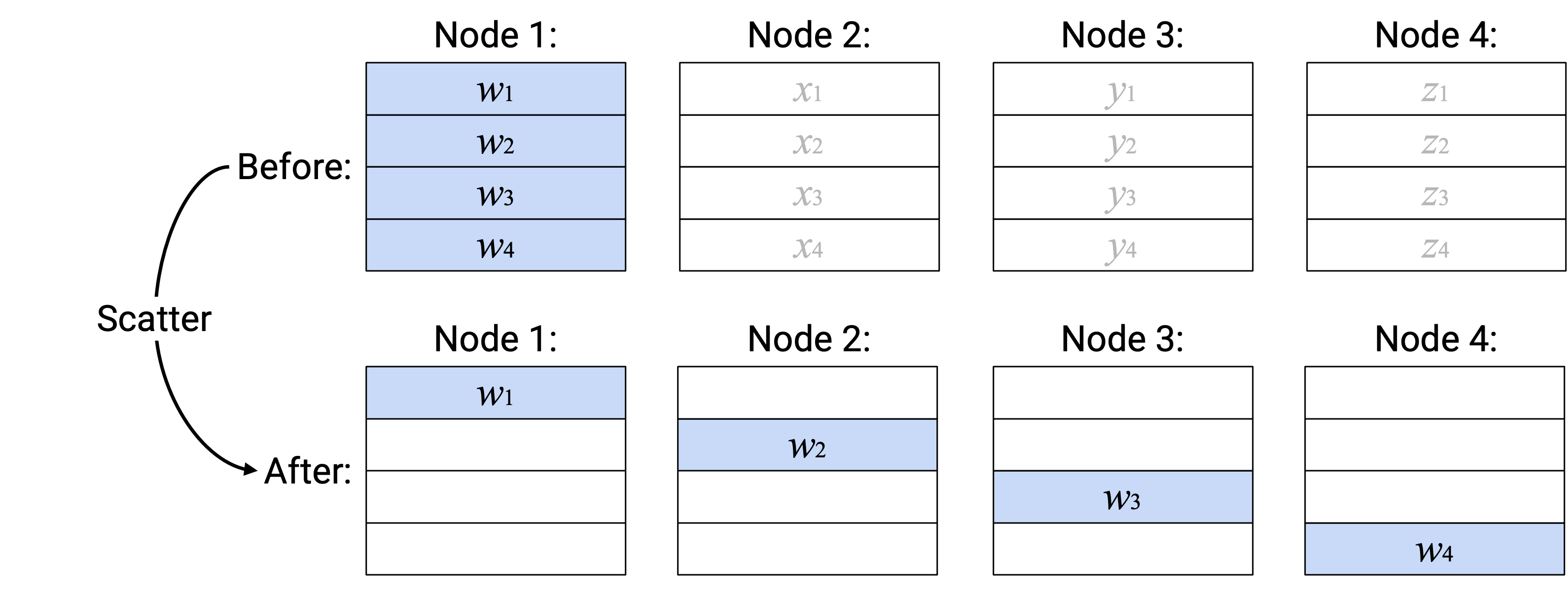
注意:和 Broadcast operation 一样,你可以指定任意 node 作为 root node。此外,也和 Broadcast operation 一样,non-root node 的 input vector 不用于创建 output(可以理解为 function 中未使用的 argument)。
Operation:Gather
英文描述:构建一个新 vector,其中第 \(i\) 个 element 定义为第 \(i\) 个 node 中的第 \(i\) 个 element。把这个 vector 发送给指定 root node。
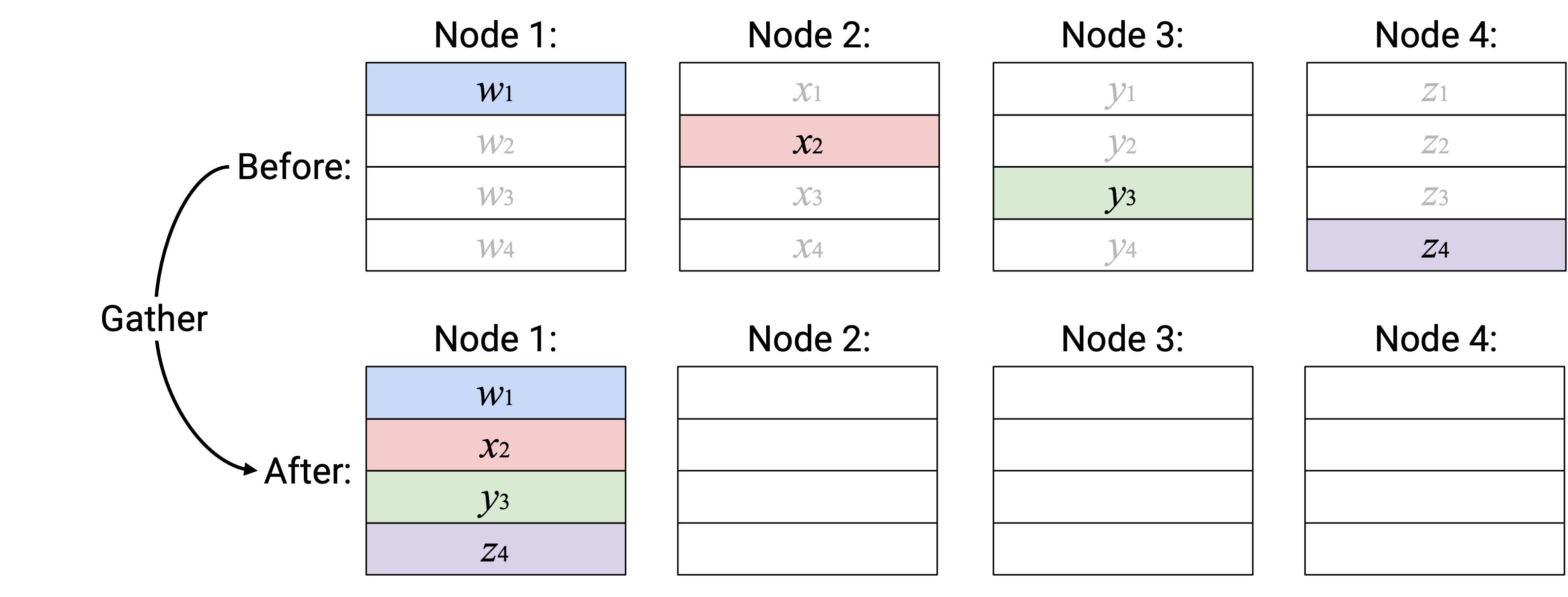
注意:在这个 operation 中,non-root node 的 receive buffer 中不会存储任何东西。
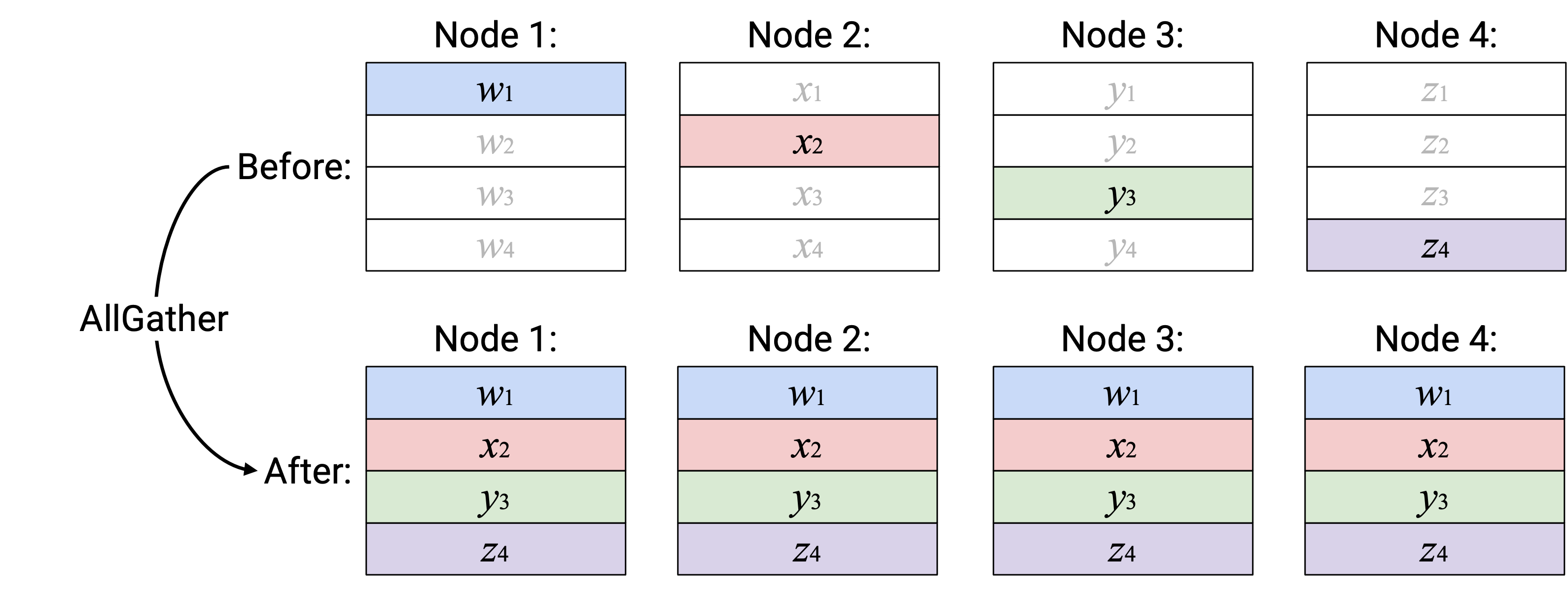
Operation:AllGather
英文描述:构建一个新 vector,其中第 \(i\) 个 element 定义为第 \(i\) 个 node 中的第 \(i\) 个 element。把这个新 vector 的副本发送给每个 node。
另一种描述(与上面等价):Node \(i\) broadcast 它的第 \(i\) 个 element,让它成为每个 node 的 output vector 中的第 \(i\) 个 element。
Operation:Reduce
英文描述:计算所有 vector 的 element-wise sum,并把得到的 sum vector 发送给指定 root node。

在这些 notes 中,我们会使用 summation 作为 reduction operation,但也可以存在其他 reduction operation。例如,我们可以在 Reduce operation(或 ReduceScatter、AllReduce)中把 addition 换成 multiplication。reduction operation 通常是 associative 和 commutative 的,粗略地说,这意味着你可以按任意顺序执行它们,并仍然得到相同结果(例如 addition 就是 associative 和 commutative 的)。
Operation:AllReduce
英文描述:计算所有 vector 的 element-wise sum,并把得到的 sum vector 的副本发送给所有 node。

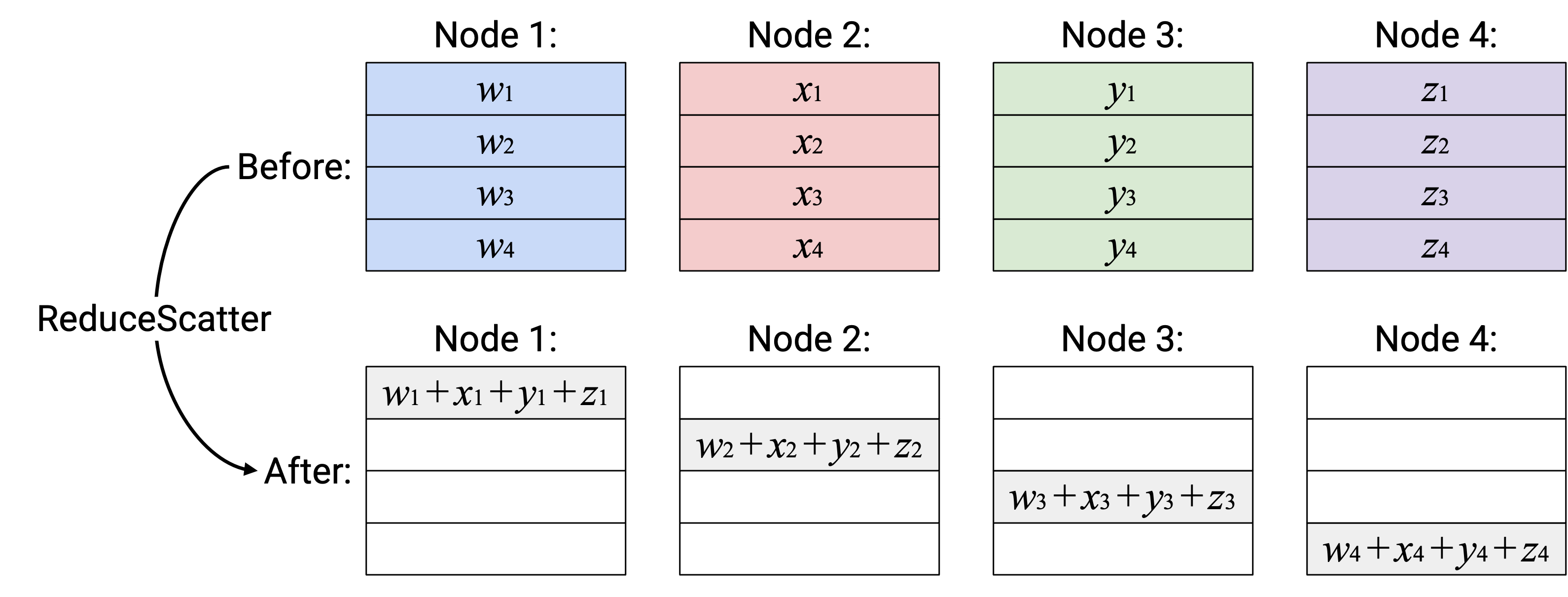
Operation:ReduceScatter
英文描述:计算所有 vector 的 element-wise sum。把 sum vector 的第 \(i\) 个 element 发送给第 \(i\) 个 node。
另一种描述(与上面等价):每个 node 的第 \(i\) 个 element 被求和,得到的 sum(scalar)发送给 node \(i\)。
Duals¶
有些 operation pair 彼此是 dual。粗略地说,这意味着一个 operation 是另一个 operation 的反向。例如,在数学中,你可以说 square 和 square root 彼此是 dual。
检查一对 operation 是否构成 dual pair 时,我们会忽略任何 reduction computation。我们只关心 output 中哪些 box 被写入,而不关心写入这些 box 的 value 是什么。
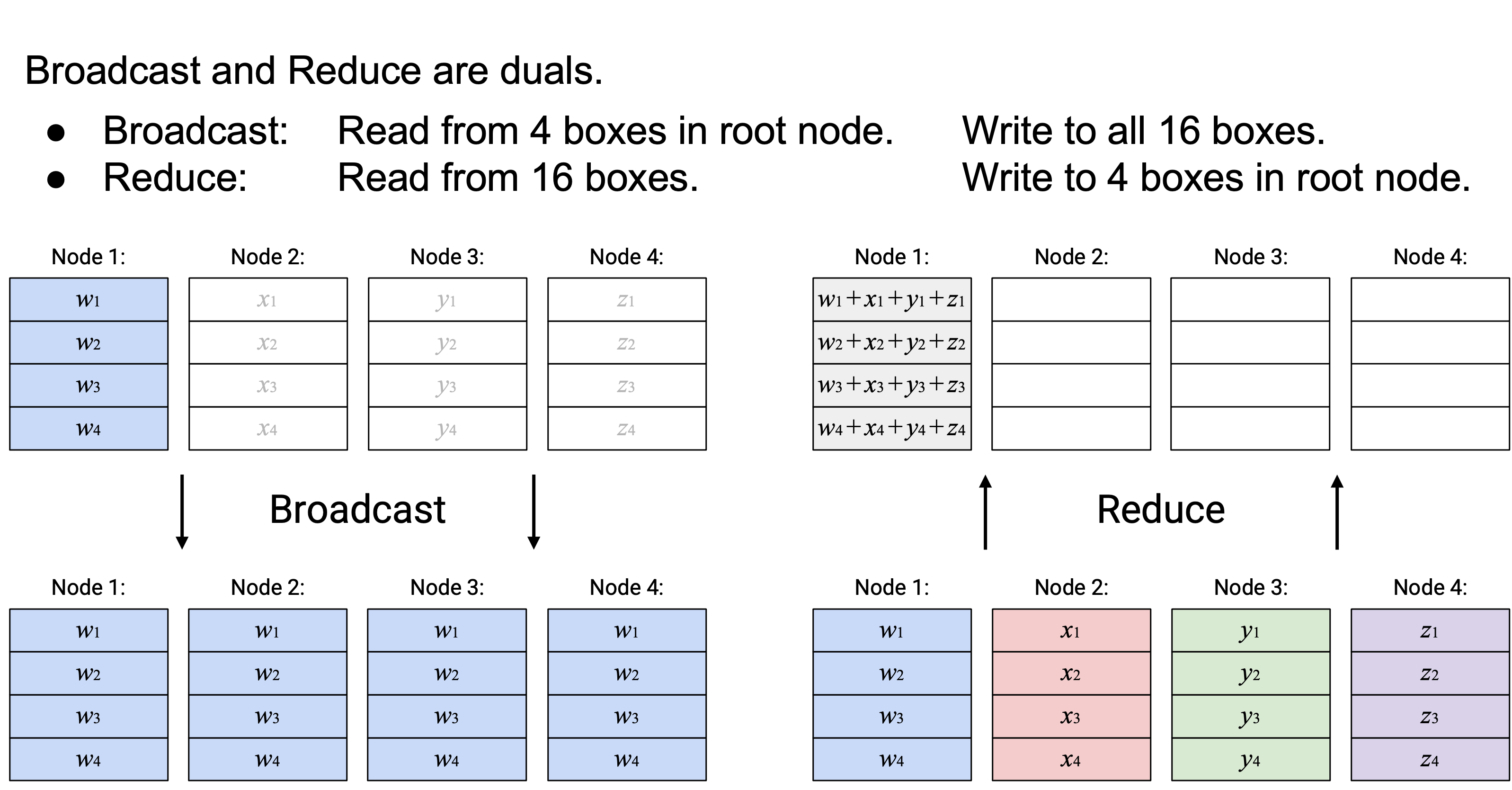
Broadcast 和 Reduce 彼此是 dual。Broadcast 从 root node 的 4 个 box 读取,并写入所有 node 中的全部 16 个 box。Reduce 做的是反向操作:它从所有 node 中的全部 16 个 box 读取,并写入 root node 中的 4 个 box。
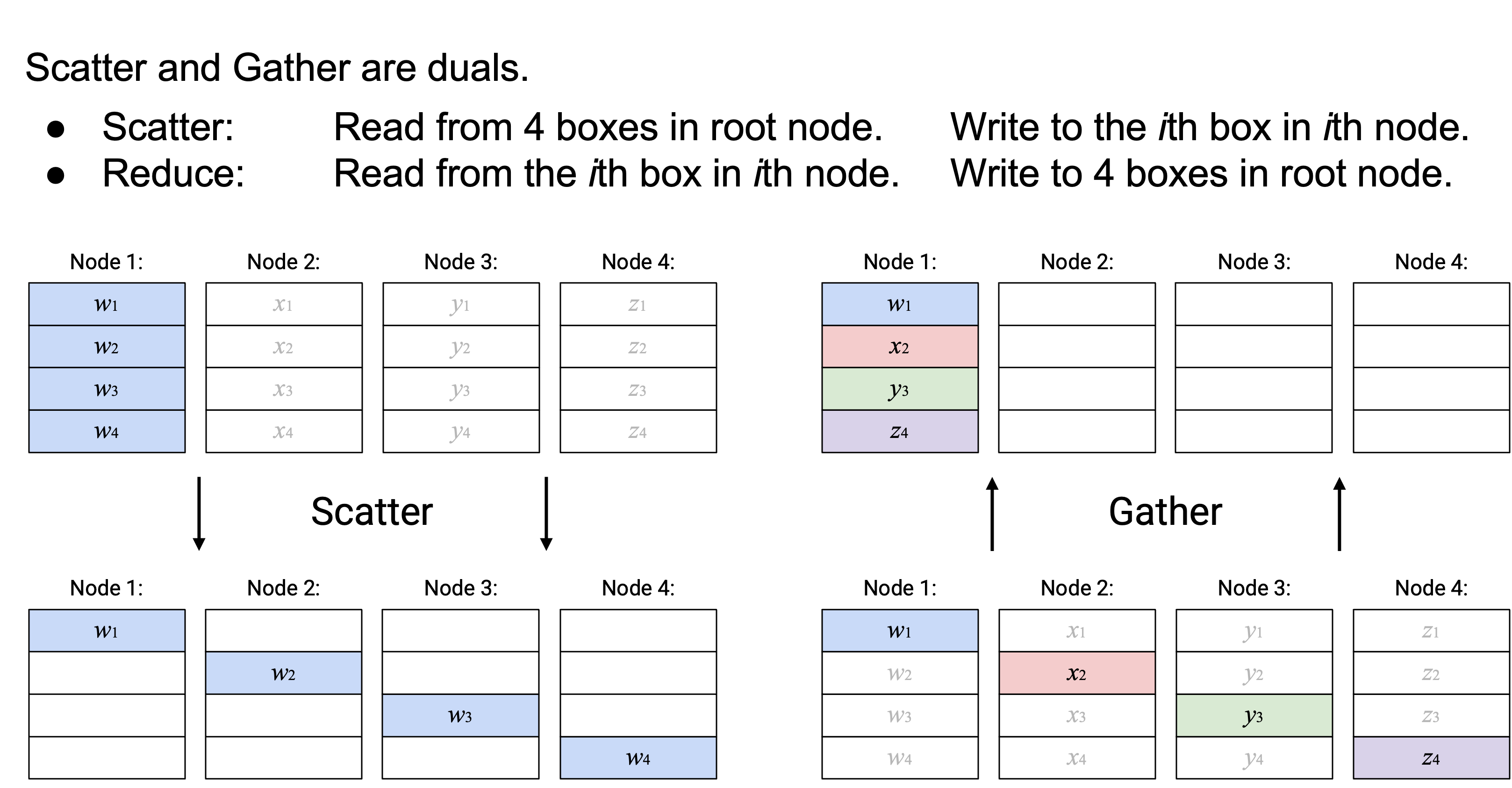
Scatter 和 Gather 彼此是 dual。Scatter 从 root node 的 4 个 box 读取,并写入第 \(i\) 个 node 的第 \(i\) 个 box(总共 4 个 box)。Gather 做的是反向操作:它从第 \(i\) 个 node 的第 \(i\) 个 box 读取(总共 4 个 box),并写入 root node 中的 4 个 box。
AllGather 和 ReduceScatter 彼此是 dual。AllGather 从第 \(i\) 个 node 的第 \(i\) 个 box 读取(总共 4 个 box),并写入所有 node 中的全部 16 个 box。ReduceScatter 做的是反向操作:它从所有 node 中的全部 16 个 box 读取,并写入第 \(i\) 个 node 的第 \(i\) 个 box(总共 4 个 box)。
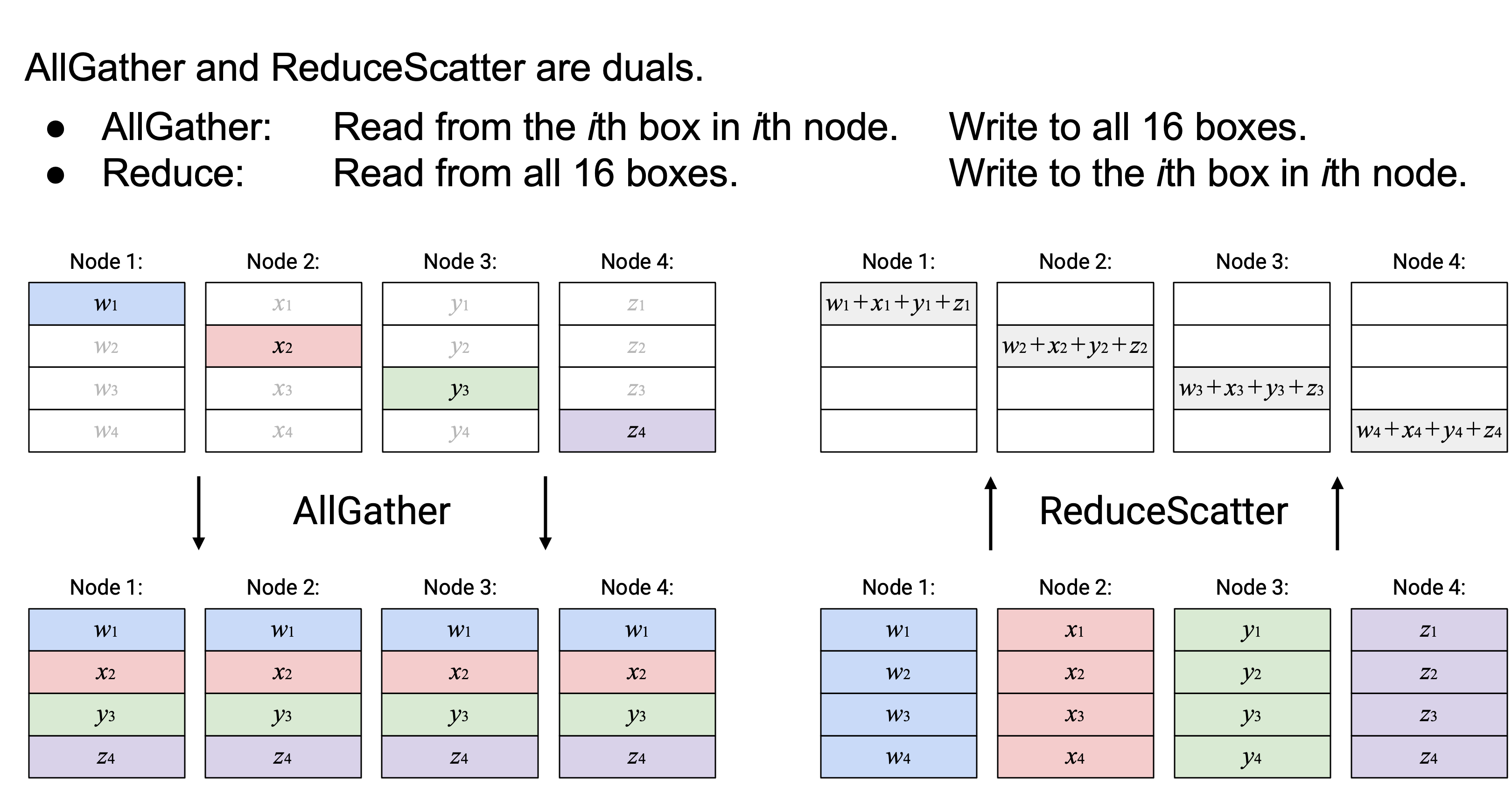
AllReduce 没有 dual。或者,你也可以把 AllReduce 看成自己的 dual,因为它从全部 16 个 box 读取,并写入全部 16 个 box。
当我们开始思考这些 collective 的实现时,dual 这个概念很有用。对于某个特定 topology 和 routing scheme,一个 collective 及其 dual 会有相同性能(例如相同的总 bandwidth usage),因为在这个 collective 和它的 dual 中,发送和接收的 data 总量相同。
Compositing Operations¶
user 可以组合多个 operation,得到自己想要的 operation。
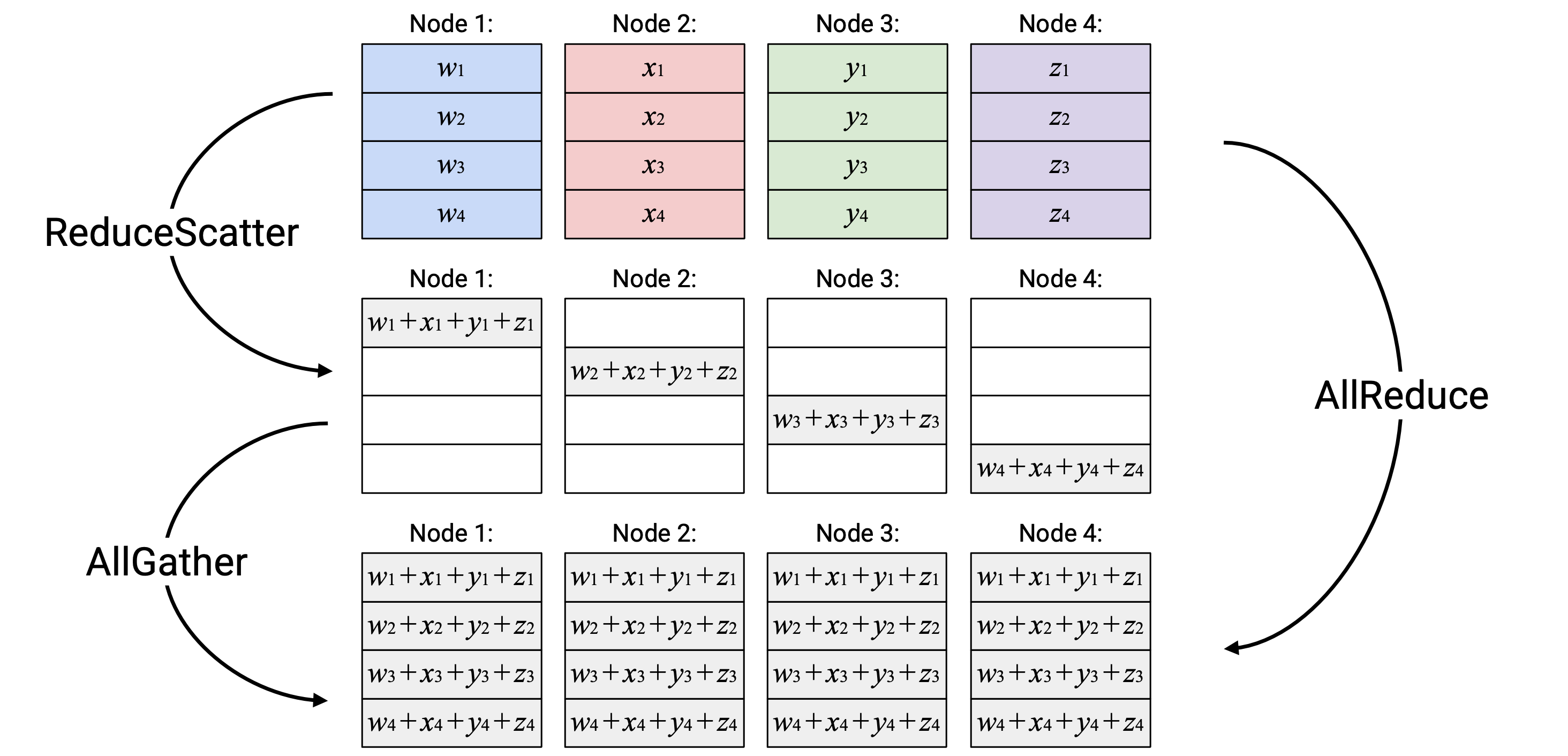
例如,AllReduce 可以等价地表示为先执行 ReduceScatter,再执行 AllGather。