Congestion Control 问题¶
混淆损坏和 Congestion¶
TCP 通过检查 packet loss 来检测 congestion,但 congestion 并不是 packet 丢失的唯一原因。packet 也可能因为损坏而丢失,而 TCP 无法区分 loss 是由损坏还是 congestion 导致的。如果某个 packet 损坏,TCP 仍然会降低速率,即使网络并不 congested。
我们也可以从方程中看到这一点:方程把 throughput 和 loss rate 联系起来。即使是非 congestion 导致的 loss,throughput 和 loss rate 也成反比。这个方程可以帮助估计一条有损 link(例如经常损坏 packet 的无线 link)会如何影响 TCP。
短连接¶
现实生活中的大多数 TCP connection 都非常短。50% 的 connection 发送的数据少于 1.5 KB,80% 的 connection 发送的数据少于 100 KB。在这些 connection 中,发送的 packet 非常少(可能只有一个)。
假设有一个 connection,sender 只有 3 个 packet 要发送。TCP congestion control 会怎么做?我们会从 window size 1 开始,发送第一个 packet。然后,等待 ack,把 window size 增加到 2,并发送剩下两个 packet。然后,再等待两个 ack,完成传输。

这个 connection 花了两个 RTT 才发送 3 个 packet,导致 throughput 极低(每个 RTT 1.5 个 packet)。
更一般地说,这些短连接永远不会离开 slow-start 阶段,也永远达不到自己的公平带宽份额。这会让短连接承受不必要的长传输时间。
短连接的另一个问题是处理 loss。回忆一下,我们在有 3 个 duplicate ack 时检测 loss,但在短连接中,可能没有足够的 packet 来触发这些 duplicate ack。例如,如果我们有 4 个 packet 要发送,并且丢失了第二个 packet,就永远不会得到 3 个 duplicate ack。相反,我们必须等待 timeout 触发。在典型现实 timeout 值大约为 500 ms 的情况下,这也会让短连接耗费不必要的长时间。
如何修复这两个问题?一种部分修复方法是从更高的 initial window 开始(例如 10 个 packet,而不是 1 个)。这样,包含 10 个或更少 packet 的 connection 就可以在 connection 开始时直接发送所有数据。
TCP 会填满队列¶
TCP 使用 loss 检测 congestion,而 congestion control 算法会有意提高速率,直到触发 loss。为了触发 loss,队列需要被填满。这意味着 TCP 会在整个网络中引入排队延迟,而且这些延迟会影响网络中的所有人。
假设我们有一个大流量 connection 正在传输 10 GB 文件,稍后又启动一个只传输单个 packet 的小 connection。两个 connection 共享同一个 bottleneck link。大流量 connection 会提高速率,直到 bottleneck link 的 queue 被填满。现在,当小 connection 启动时,它会被卡在队列中,排在大流量 connection 的 packet 后面等待。
如果 router 保留极大的队列,这个问题会变得更严重。router 拥有过量内存来维护长队列的现象称为 bufferbloat。家庭 router 中可能出现 bufferbloat:它可能有一个巨大 queue,但使用这个 queue 的 connection 很少(只有你家里的那些)。现在,你发起的任何 connection 都会给其他 connection 带来很大的排队延迟。
为了避免队列被填满,我们可以寻找一种不需要故意触发 loss 的 congestion 测量方法。特别是,我们可以在 RTT 开始增加时检测 congestion,因为这表示 delay。这就是 Google 近期 BBR algorithm(2016)背后的思想。sender 学习自己的最小 RTT,并且如果开始注意到 RTT 超过最小值,就降低速率。
作弊¶
没有任何机制强制 sender 必须遵守 TCP congestion control 算法。sender 可以作弊,以获得不公平的大带宽份额。
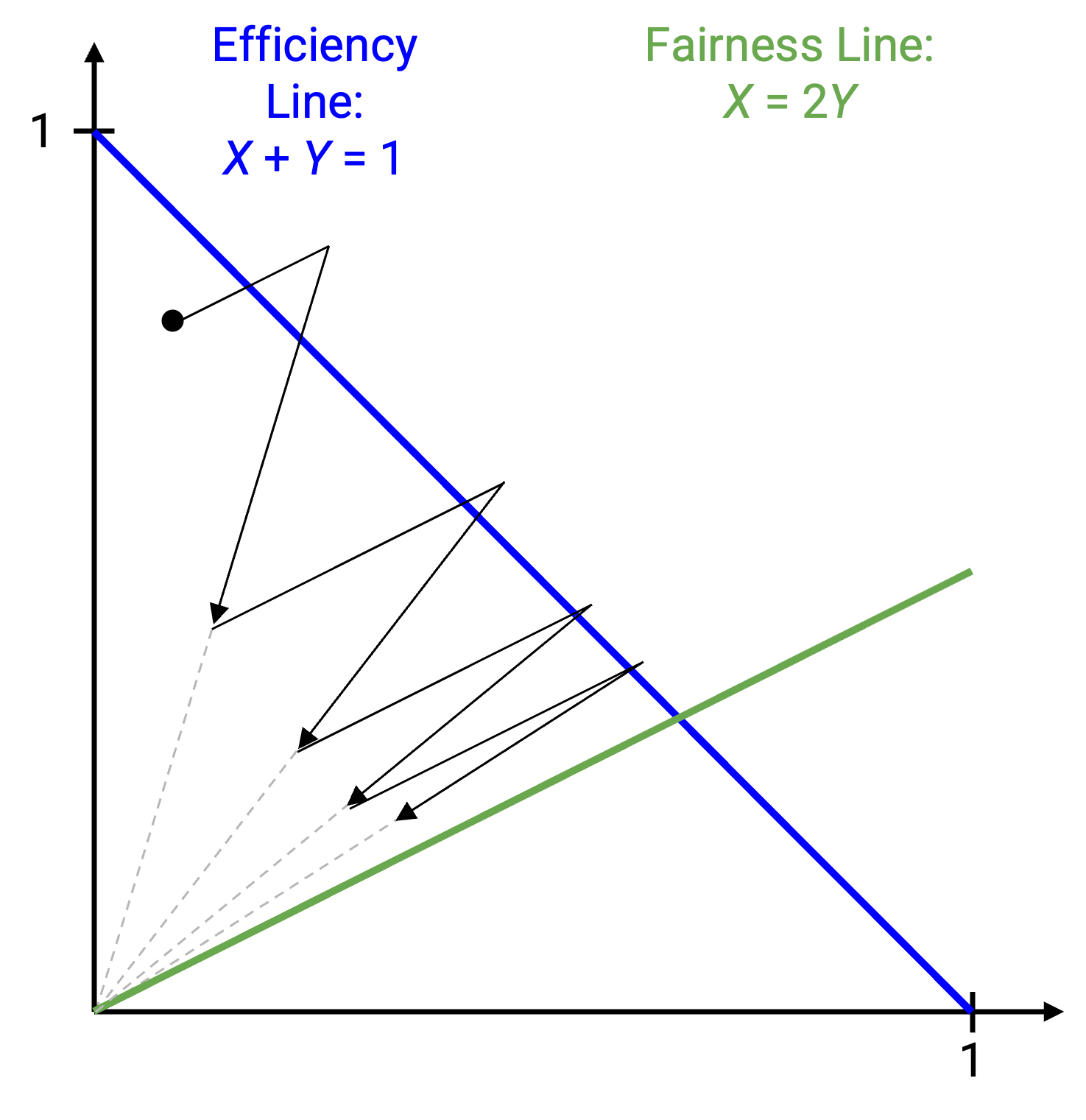
例如,sender 可以更快增加 window(例如每个 RTT +2,而不是 +1)。如果把我们的图形模型应用到一个作弊 sender 和一个诚实 sender 上,AIMD 更新实际上会收敛到一条糟糕的公平线,在那里作弊 sender 得到的带宽是诚实 sender 的两倍。
也存在许多其他修改 protocol 的方式,例如从非常大的 initial congestion window 开始。
在实践中,因为 TCP 实现在操作系统中,为了作弊,sender 必须修改自己操作系统中的代码,而绝大多数 Internet 用户不会这么做。
如果少数 sender 滥用系统,这些 sender 会获得更多带宽。如果大量 sender 滥用系统(例如 Microsoft 发布了一个滥用 TCP 的 Windows 版本),数百万 Windows 用户仍然会彼此竞争,最终不太可能有人真正得到更多带宽。
另一种不修改 TCP 的作弊方式是打开许多 connection。TCP 只保证每个 connection 得到公平份额。如果一个作弊 sender 打开 10 个 connection,而一个诚实 sender 打开 1 个,那么作弊 sender 会得到 10 倍的带宽。许多应用会有意打开更多 connection 来提高带宽。
如果可以作弊,为什么 Internet 没有再次遭受 congestion collapse?事实证明,研究人员其实也不知道答案。一种可能是:修改 congestion control 算法的作弊者也许会得到不公平的带宽份额,但如果他们仍然遵循 congestion control 的原则(例如 loss 发生时降低速率),那么他们并不会压垮网络。相比之下,在 1980 年代最初的 congestion collapse 中,sender 会持续以高速率重发 packet,完全没有调整速率的概念。
如果可以作弊,实践中有多少作弊发生?同样,我们其实不知道。作弊很难测量(例如,你不知道每个 sender 正在使用的 window)。
Congestion Control 和可靠性交织在一起¶
congestion control 和可靠性的机制紧密耦合。正如我们看到的,congestion control 是通过拿 TCP 可靠性的代码改几行实现的。
我们也可以在算法本身中看到这种依赖。window 在 ack 和 timeout 上更新,是因为可靠性代码本来就写成响应这些事件。我们用 duplicate ack 检测 loss,是因为可靠性实现使用 cumulative ack。
把可靠性和 congestion control 结合在一起是一种设计选择。一个好处是,congestion control 只是一个很小的代码补丁,可以为了应对 1980 年代的 congestion collapse 而被广泛部署。然而,从那以后,这两个功能的结合让算法演化变得更复杂。例如,如果我们想修改 congestion control 算法中的某些东西,很可能也必须修改可靠性代码。或者,如果我们想修改可靠性实现(例如从 cumulative ack 改成 full-information ack),也必须同时更新 congestion control。
从设计角度看,这是模块化失败,而不是 layering 失败。congestion control 和可靠性确实运行在正确的抽象层级(传输层)。然而,在传输层内部,我们没有把不同功能清楚地拆分到代码的不同部分。
因为 congestion control 依赖可靠性,所以很难在没有可靠性的情况下实现 congestion control。有些应用(例如视频流)可能不想要可靠性,但仍然想要 congestion control。但我们没有办法关闭可靠性,只保留 congestion control。
同样,也很难在没有 congestion control 的情况下实现可靠性。例如,如果我们有一个轻量 connection,每 10 分钟发送一个 packet,那么这个 connection 可能并不需要 congestion control。但我们无法轻易地只为某些 connection 关闭 congestion control。