Host Networking¶
什么是 Host Networking?¶
传统上,network 的 bottleneck 位于网络基础设施内部,而不是 end host 上。不过,在现代高性能 datacenter 中,随着 network performance demand 持续增长,end host 越来越难以跟上需求。
特别是,运行 TCP 这类 network protocol 的 CPU 已经无法提供 datacenter 所需的高性能。CPU 很昂贵,而实现高性能意味着 CPU 会把所有时间都花在运行 network protocol 上,留给实际 application 的资源更少。
另外,我们一直运行的实际 protocol,例如 IP 和 TCP,也已经无法满足现代高性能需求。
为了解决这两个问题,我们转向 host networking,也就是在 end host 上进行优化(而不是在 network 内部优化)。

优化:User Space 中的 Shared Memory¶
回忆一下,在 end host 上,Layer 1 和 Layer 2 由 network interface card(NIC,网卡)中的硬件实现。Layer 3 和 Layer 4 在 operating system 中以软件形式实现(运行在 CPU 上)。Layer 7 是 application 本身。
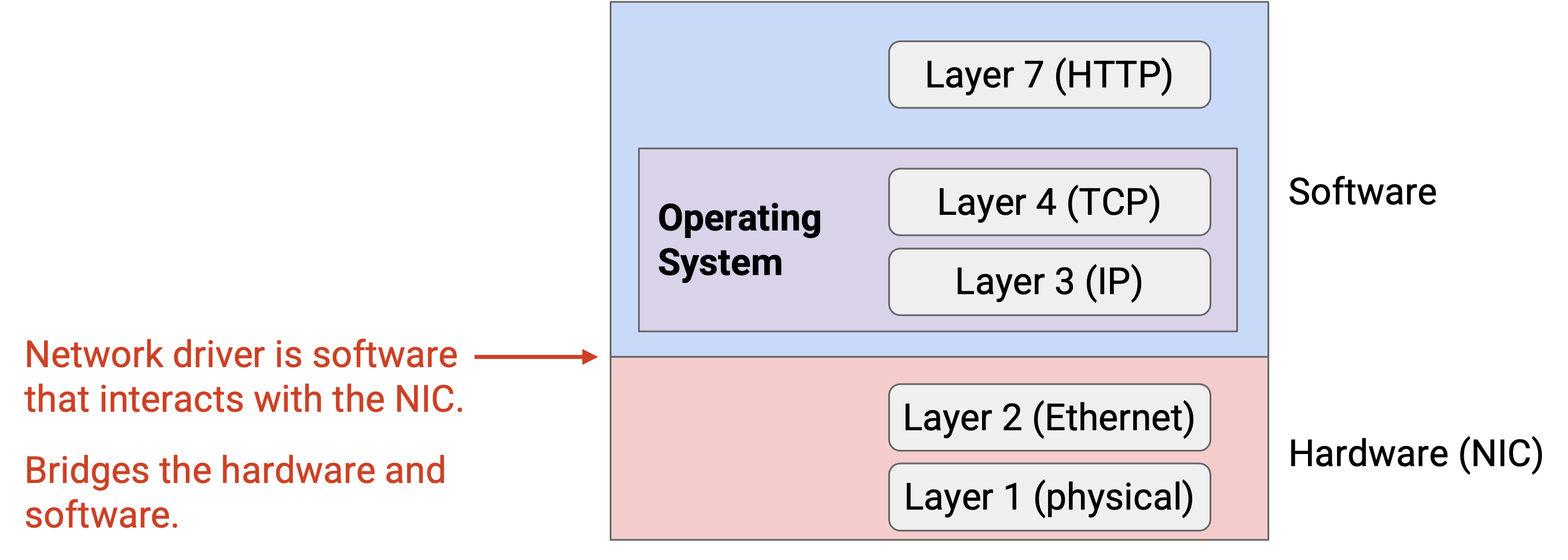
回忆一下先修课程(例如 UC Berkeley 的 CS 61C)中的内容:现代 computer 使用 virtual memory 设计,使每个 application 都拥有自己的 dedicated address space,并与其他 application 隔离。特别是,每个 Layer 7 application 在 user space 中拥有自己的 dedicated address space。相比之下,operating system 自身运行在 kernel space 中,这是内存中的一个特殊区域,user space 中的 application 无法访问。
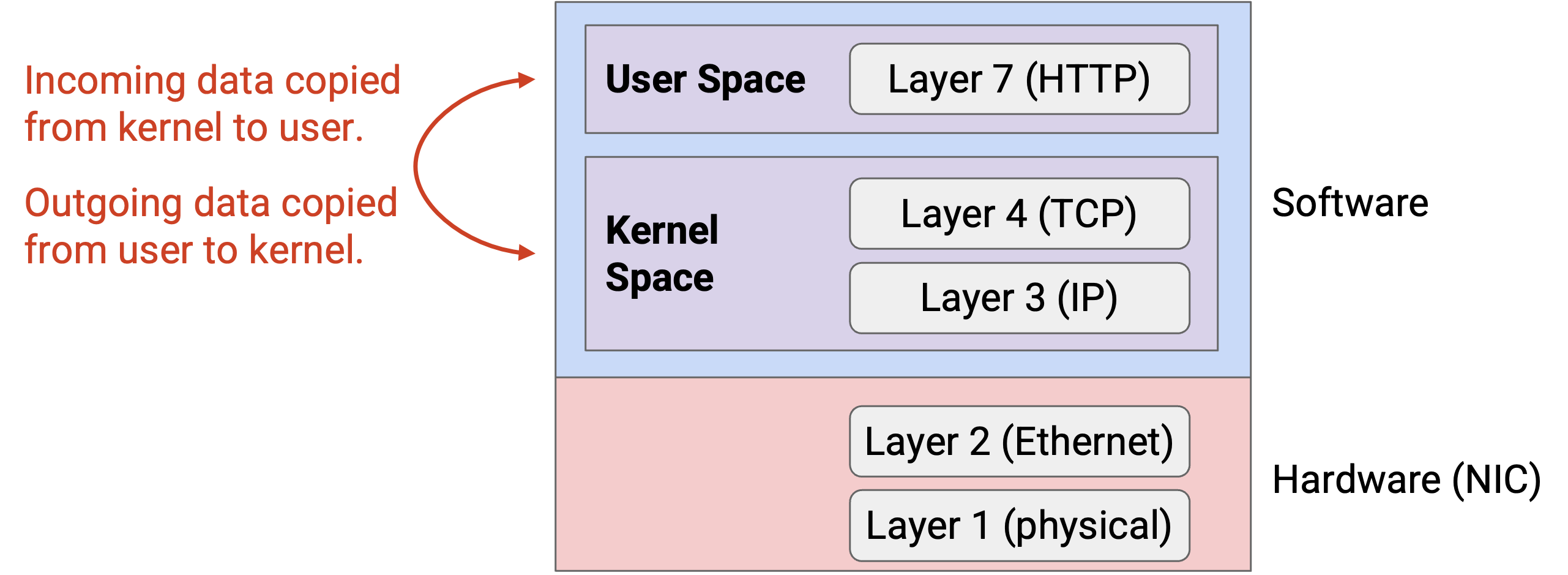
这种 memory management model 意味着,当我们沿 stack 向下传递 packet 来发送数据时,会不断把数据从 user space copy 到 kernel space。同样,当我们沿 stack 向上传递 packet 来接收数据时,也会不断把数据从 kernel space copy 到 user space。在 kernel space 和 user space 之间 copy bit 既昂贵,也有些没有意义。
这种 memory management model 的另一个问题是,在 kernel space 中编程很困难。如果我们想修改 TCP 并针对自己的目的优化它,就必须深入 operating system,并在非常底层的层面编程。Kernel space 中的部署和测试比 user space 更难、更慢。
为了解决这两个问题,我们可以把 networking stack(例如 Layer 3 和 Layer 4 protocol)移出 kernel space,放入 user space。现在,Layer 3、4、7 都可以访问一个 shared address space,不再需要来回 copy。另外,在 user space 中迭代和创新也更容易。
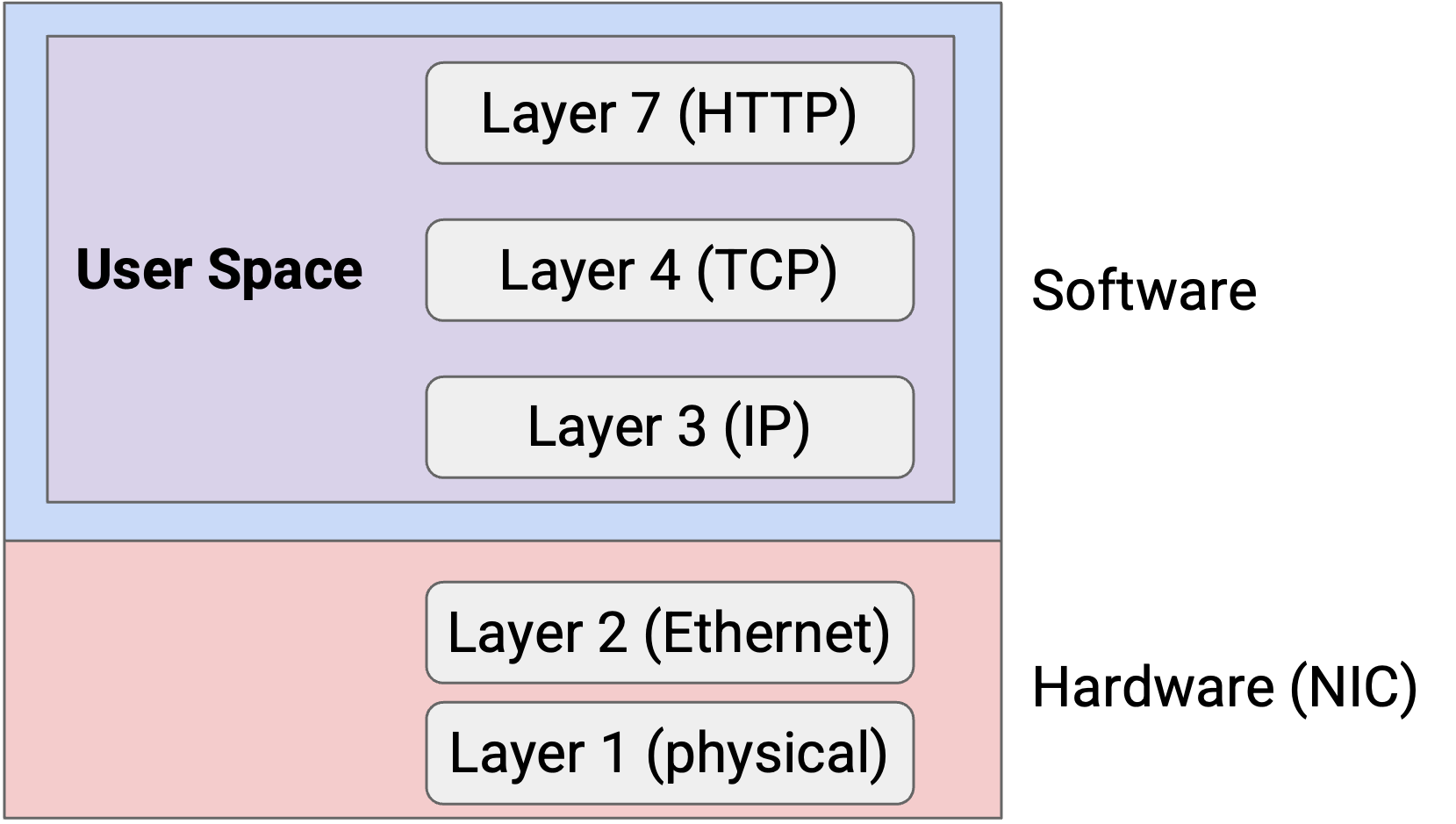
在 user space 中使用 shared memory 可以帮助我们消除一些额外工作,例如来回 copy,但这仍然不足以让 host 满足现代性能要求。
优化:Offload 到 NIC¶
CPU 不够快,无法以现代性能速度运行 network protocol(例如 IP、TCP)。另外,用 CPU 运行 network protocol 会让 application 自身可用的 CPU 资源变少。
为了解决这个问题,我们可以把 networking stack 从 CPU(软件)offload 到 NIC(硬件)中。
NIC 是执行 offloading 操作的自然位置。每个 packet 都必须经过 NIC,因此 NIC 可以做一些额外处理,避免 CPU 做这些工作。
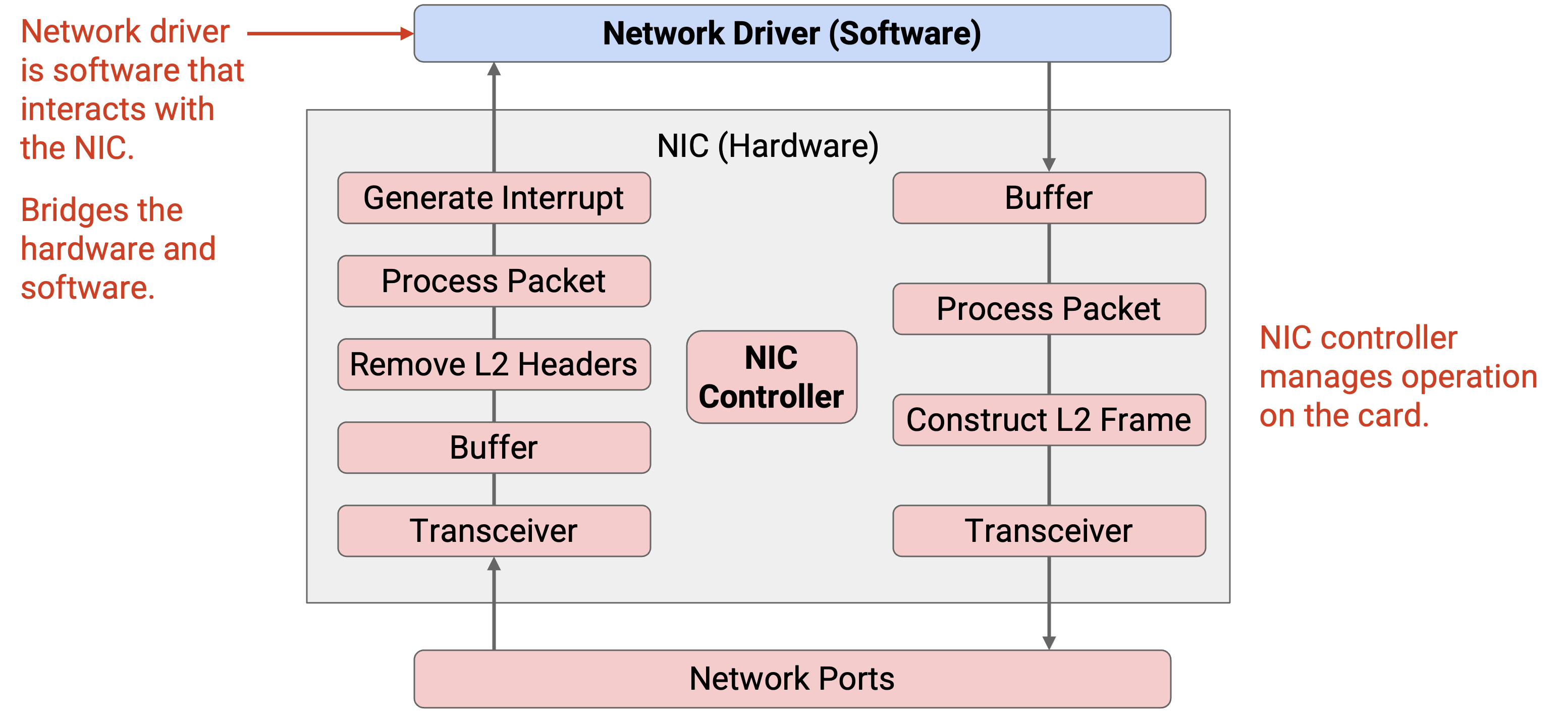
Network driver 是 OS 中一段用于编程和管理 NIC 的软件。Driver 提供一个 API,让 OS 中更高层程序能够与 NIC 交互。你可以把 driver 看作硬件和软件之间的桥梁。
Offloading 有什么好处?它释放 CPU 资源,让 application 使用。另外,硬件中的专用处理可以比通用 CPU 上的处理更高效。这里的效率同时指速度和功耗。最后,在硬件中运行操作不仅带来更低 latency,也带来更可预测且一致的 latency。当在软件中运行 application 时,CPU 必须调度不同 process,这可能增加不可预测的 delay。(例如,如果我有一个 packet 要处理,CPU 可能必须先完成当前 job,才能切换过来处理我的 packet。)
Offloading 简史:Epoch 0¶
把操作从 OS(软件)offload 到 NIC(硬件)是一个活跃且仍在进行的研究领域。它经历了三个 development epoch,其中越来越复杂的操作被 offload 到 NIC。
Epoch 0:在任何 offloading 之前,让我们先看看在目前见过的标准 networking stack 中,NIC 做了什么。
NIC 有一个中央 controller processor,用来管理卡上的操作。
对于 incoming packet,transceiver 会把电信号转换成数字信号(1 和 0),并把这些 bit 放入 buffer。然后,NIC 从 buffer 中读取 bit,把它们解析成 Ethernet frame,处理 frame(例如验证 checksum),并移除 Layer 2 header。最后,NIC 生成一个 interrupt,告诉 CPU 停下当前工作,收集得到的 Layer 3 packet 以便进一步处理。
对于 outgoing packet,来自 network driver 的 packet 会被放入 buffer。NIC 从 buffer 中读取 bit 并处理它们,以构造 Ethernet frame。然后,frame 被传给 transceiver,后者把数字 bit 转换成电信号。
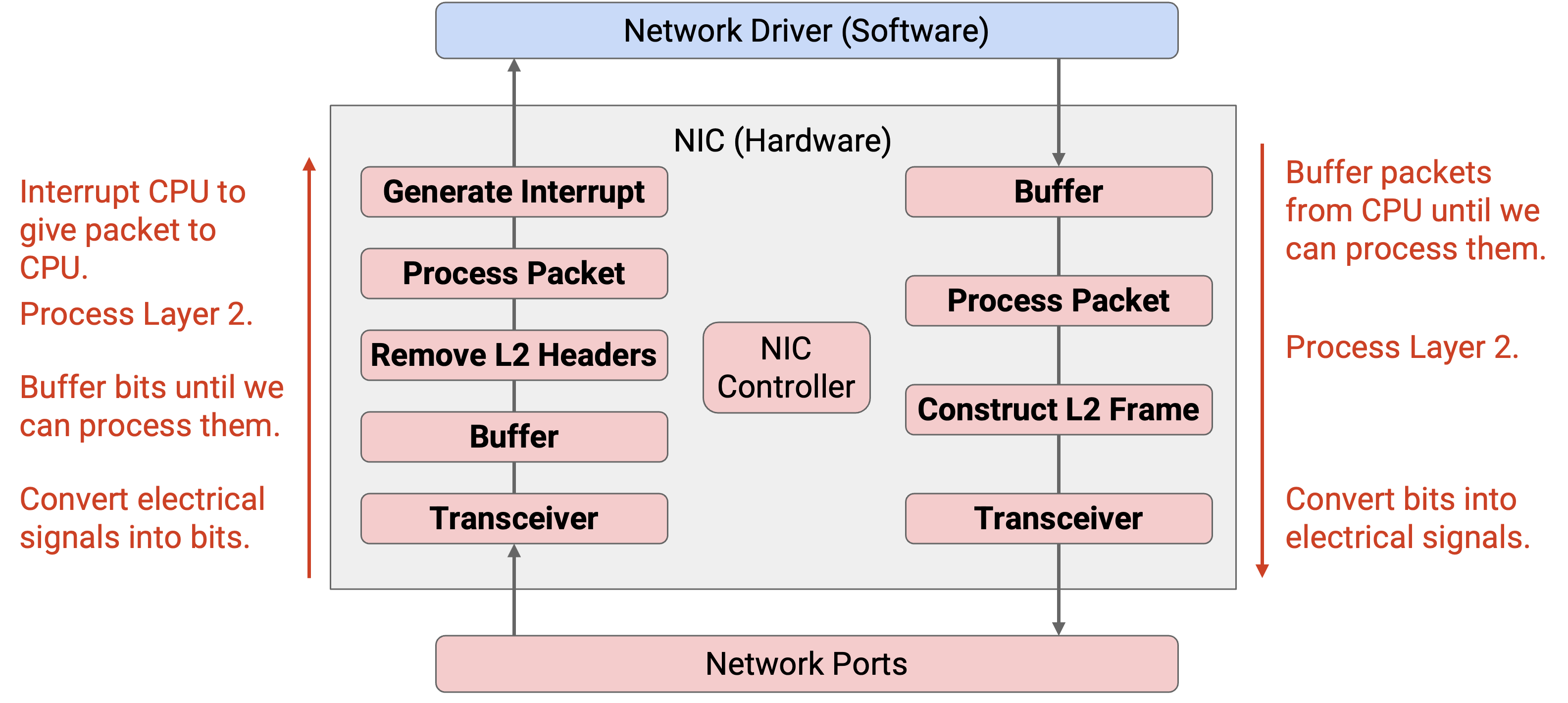
在标准 networking stack 中,你可以把 NIC 想成一个门垫:它把 incoming packet 传给 OS,并为 OS 发送 outgoing packet,但对这些 packet 做的处理非常少。
Offloading 简史:Epoch 1¶
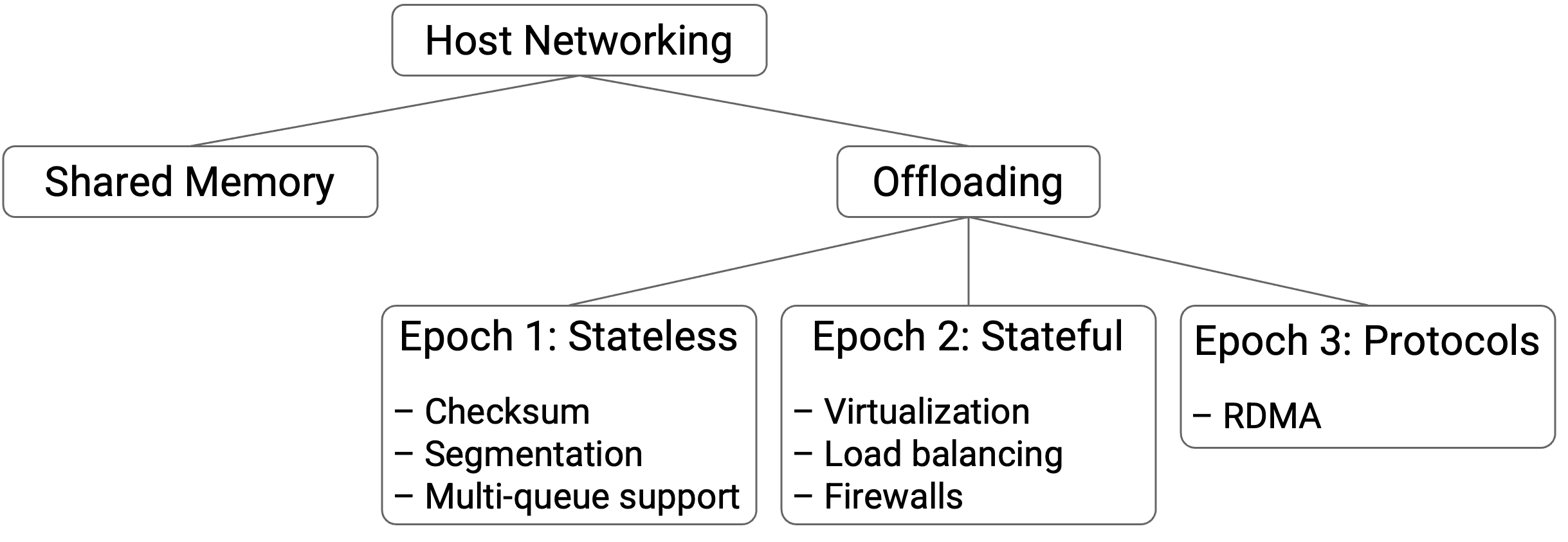
我们最早尝试 offload 到 NIC 的操作,是简单的 stateless operation。这些 stateless operation 可以独立地针对每个 packet 完成,NIC 不需要在多个 packet 之间记住任何 state。
一种可以 offload 的 stateless operation 是 checksum computation,不只在 Layer 2,也包括 Layer 3 和 Layer 4。NIC 可以验证这些 checksum(对于 incoming packet)并计算这些 checksum(对于 outgoing packet),这样 CPU 就不必做这些工作。
另一种可以 offload 的 stateless operation 是 segmentation。在我们的标准模型中,如果 application 有一个巨大 file 要发送,那么 OS 负责把这个 file 分割成更小的 packet。然后,在 recipient 端,OS 负责重新组装这些 packet。作为一种优化,我们可以让 NIC 处理 packet 的拆分和重组。现在,OS 不再需要处理大量小 packet,而是可以处理少数大 packet,这更高效(例如需要处理的 header 更少)。
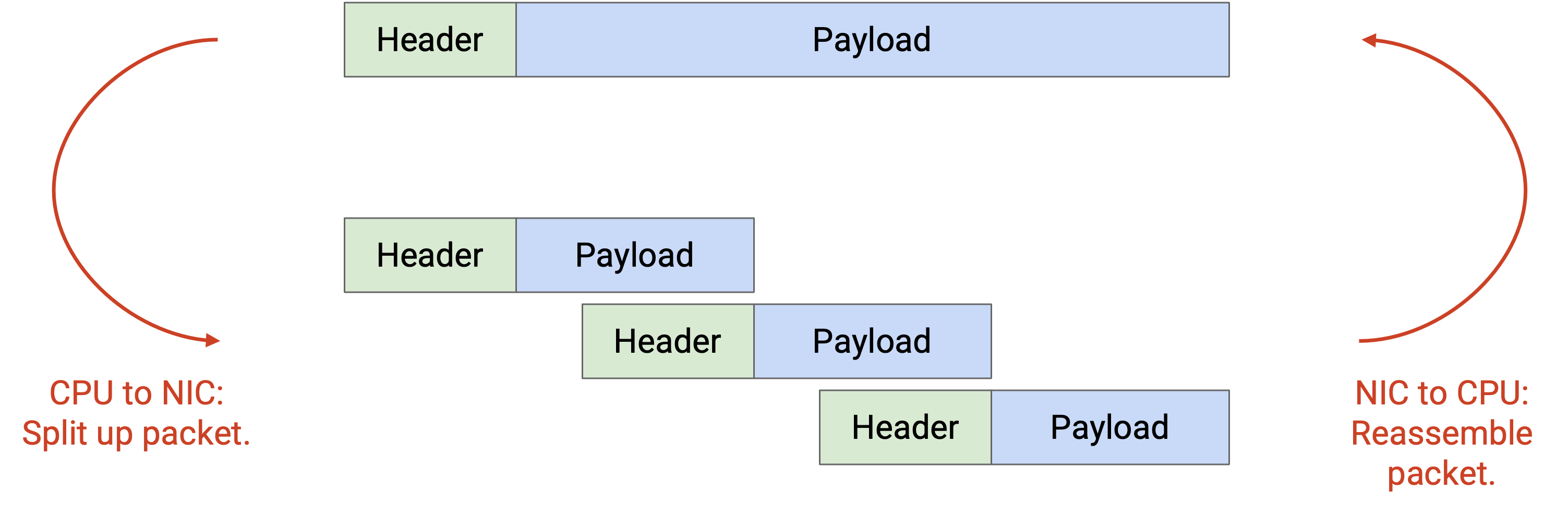
使用 segmentation 时,smooth connection 和 CPU efficiency 之间存在 trade-off。如果 application 把大 packet 交给 NIC,CPU 要做的工作更少。不过,NIC 现在会收到大 burst 的数据,connection 会更 bursty。相比之下,如果 application 把较小 packet 交给 NIC,CPU 要做更多工作,但 NIC 会获得更稳定的数据流,得到的 connection 更平滑。
聚合小 packet 也会带来一些 challenge。如果中间某个 packet 丢失,会怎样?那么 NIC 可能不得不向上传递一堆小 packet,无法把它们合并成一个大 packet。如果有些 packet 设置了某个 flag(例如表示 congestion 的 ECN),而其他 packet 没有设置,会怎样?最终聚合出的 packet 应不应该设置这个 flag?
我们要看的第三种 stateless offload 是 multi-queue support。在标准模型中,NIC 有一个 outgoing packet queue 和一个 incoming packet queue,所有 application 共享这些 queue。Network driver(软件)负责 load balancing,以应对多个 application 或多个 CPU 正在发送和接收数据的情况。
我们可以改为把这个 load balancing job offload 给 NIC。现在,NIC 有多个 transmit queue,也有多个 receive queue。例如,在 multi-processor system 中,每个 CPU 可以有自己的 dedicated transmit/receive queue。NIC 并行维护所有 queue,确保不同 CPU 之间的隔离和 load-balancing。NIC 也可以让某些 queue 优先于其他 queue。
尽管 NIC 有多个 queue,它最终仍然必须沿一根 wire 发送所有 packet。因此,NIC 需要某种 packet scheduler 来决定下一步从哪个 queue 发送。Scheduler 可以被编程,以实现所需的 load-balancing behavior(例如,如果我们想让一个 queue 优先于另一个 queue)。
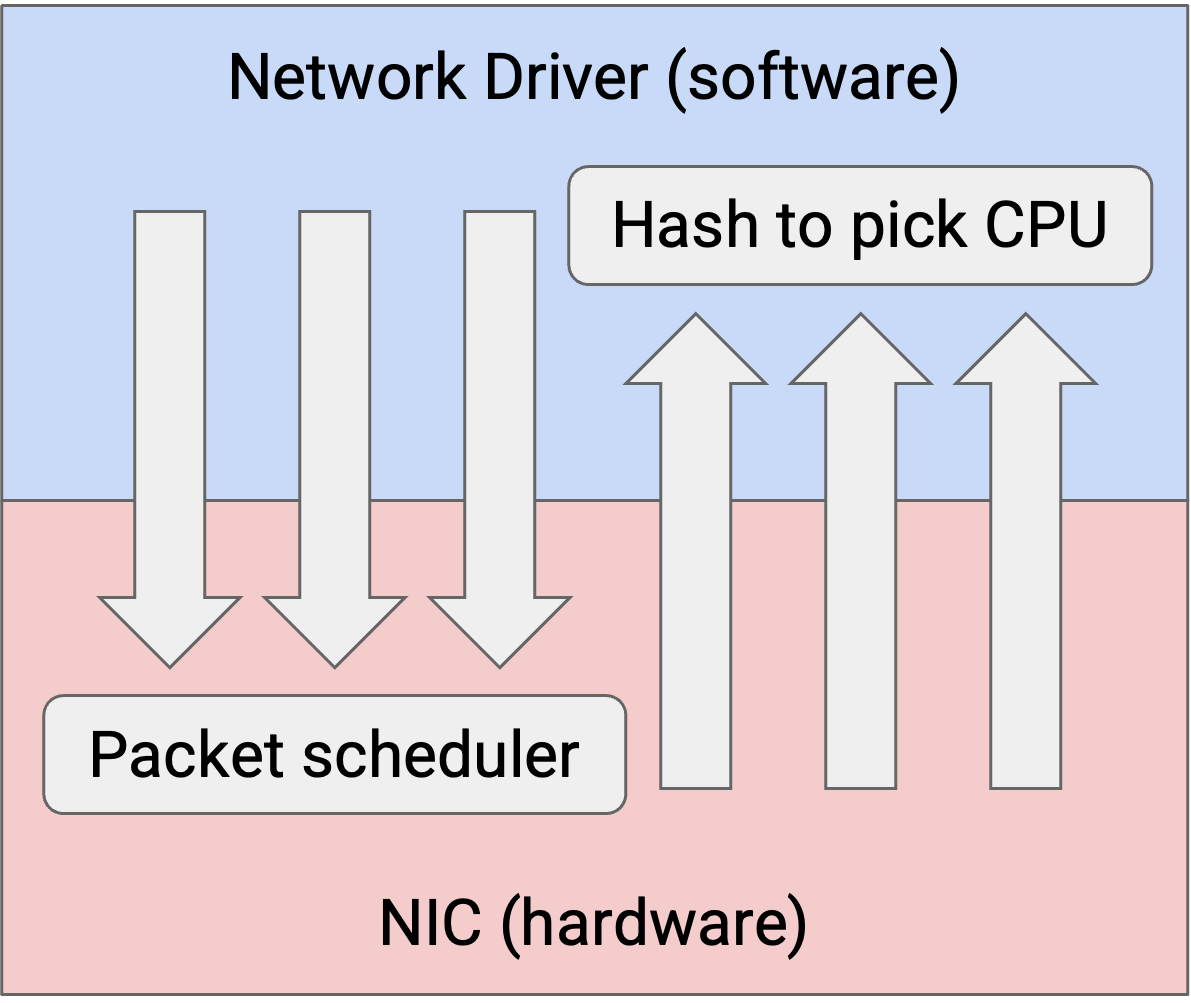
多个 queue 的一个 challenge 是把 packet 映射到 queue。当 CPU 有一些数据要发送时,它应该使用哪个 queue?特别是,我们希望确保单个 flow 中的所有 packet 都进入同一个 queue(而不是分散到许多 queue 中)。这有助于确保一个 flow 中的 packet 按顺序发送。回忆一下,在 TCP 中,out-of-order 发送 packet 是可行的,但对性能不好(例如 receiver 必须 buffer out-of-order packet)。
在处理来自多个 receive queue 的 incoming packet 时,NIC 可以对 packet 做 hash,决定哪个 CPU 来处理这个 incoming packet。然后,NIC interrupt 那个 CPU,并告诉它处理 packet。这种基于 hash 的行为类似 ECMP(Equal-Cost Multi-Path Routing),并帮助我们确保同一个 flow 中的所有 packet 都由同一个 CPU 按顺序处理。
Offloading 简史:Epoch 2¶
后来,我们开始把更复杂的 stateful operation offload 到 NIC。
Epoch 2 的发展由 datacenter 中的 virtualization 推动,因为多台 virtual machine 运行在同一台 physical server 上。例如,在 virtualization 中,我们需要一个 virtual switch,把 incoming packet 转发到合适的 VM。我们展示过 virtual switch 以软件形式运行,但 virtual switch 也可以在硬件中实现。
Firewall 和 bandwidth management 是 stateful offload 的另一个例子。在软件中,我们可以实现一个 firewall 来强制执行 security policy(例如丢弃来自某个恶意 IP 的所有 incoming packet)。我们也可以强制执行 policy 来管理 user 之间的 bandwidth(例如 User A 每分钟只能发送 100 个 packet,超出的都会被丢弃)。这些 security policy 也可以由硬件检查。
为了实现这些 stateful operation,我们可以使用 match-action pair table,类似 SDN 一节中的 OpenFlow table。这个 API 允许软件把不同 policy 编程到硬件上,使硬件可以按这些 policy 处理 packet。正如前面所见,match 可以基于 5-tuple 或其他 header field。Action 可以是丢弃 packet、把 packet 转发到某个具体 next-hop,或修改 header。

Offloading 简史:Epoch 3¶
这是 offloading 的当前时代。人们正在持续努力,把完整 protocol(例如 TCP)从 OS offload 到 NIC 上。这个 epoch 由更高性能需求推动,尤其是 AI/ML(artificial intelligence、machine learning)这类具有高性能要求的 application。
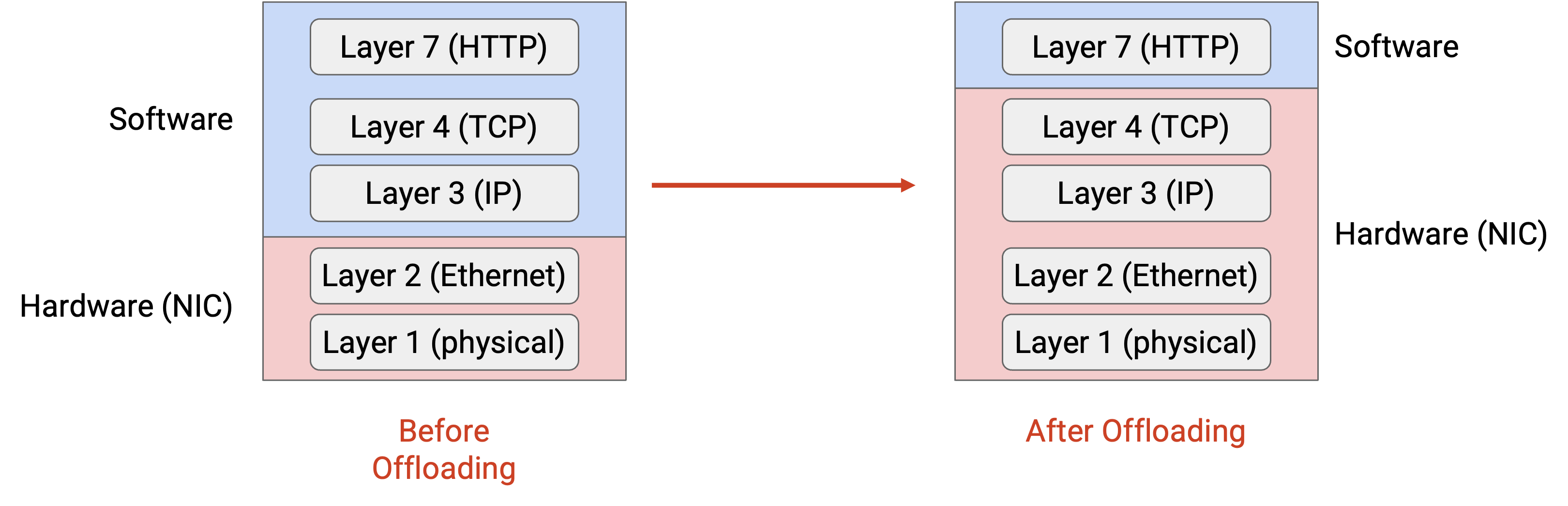
理想情况下,我们希望让 application 直接把数据交给硬件,并让硬件在 Layer 4、3、2、1 执行所有必要的 network processing。OS 完全退出这个过程,所有 network protocol 都直接在硬件中实现。
虽然人们已经尝试把 TCP 这类标准 networking protocol offload 到 NIC 上,但它们还没有被大规模部署。相反,我们设计了 RDMA 这样的新 networking protocol,它们专门设计为可以直接在硬件中实现。
RDMA:Remote Direct Memory Access¶
RDMA 提供一种抽象:Server A 可以直接访问 Server B 的内存,而不需要任一 server 中的 OS 或 CPU 参与。RDMA 可以直接在硬件中实现,替代标准 TCP/IP 软件 networking stack。
假设 Server A 想向 Server B 发送一个 10 GB file。在标准 networking stack 中,CPU 从内存读取 file,处理它(例如 TCP/IP),并把得到的 packet 传给 NIC。在 recipient 端,NIC 把 packet 传给 CPU,CPU 处理 packet,并把得到的 file payload 写入内存。注意,CPU 参与了这个 10 GB file 的每一个 packet 处理。

在 RDMA 抽象中,NIC 从内存读取 file 并发送出去,没有 CPU 参与。在 recipient 端,NIC 处理 incoming byte 并把它们写入内存,同样没有 CPU 参与。注意,一开始仍然需要 CPU 来设置 transfer,最后也需要 CPU 来完成 transfer。但这个 10 GB file transfer 的主体部分不需要 CPU。

使用 RDMA 时,programmer 不再使用 socket abstraction。相反,我们使用的主要抽象是 queue pair。Send work queue 包含所有 pending job,这些 job 需要把数据从我传输给别人。Receive work queue 包含所有 pending job,这些 job 需要我从别人那里接收数据。一张 NIC 可以有多个 queue pair,每个 queue pair 为 programmer 提供不同 service。例如,一个 pair 可能提供 reliable、in-order delivery,而另一个 pair 可能提供 unreliable delivery。配置为 reliable 且 in-order 的 queue pair 最接近传统 TCP connection。
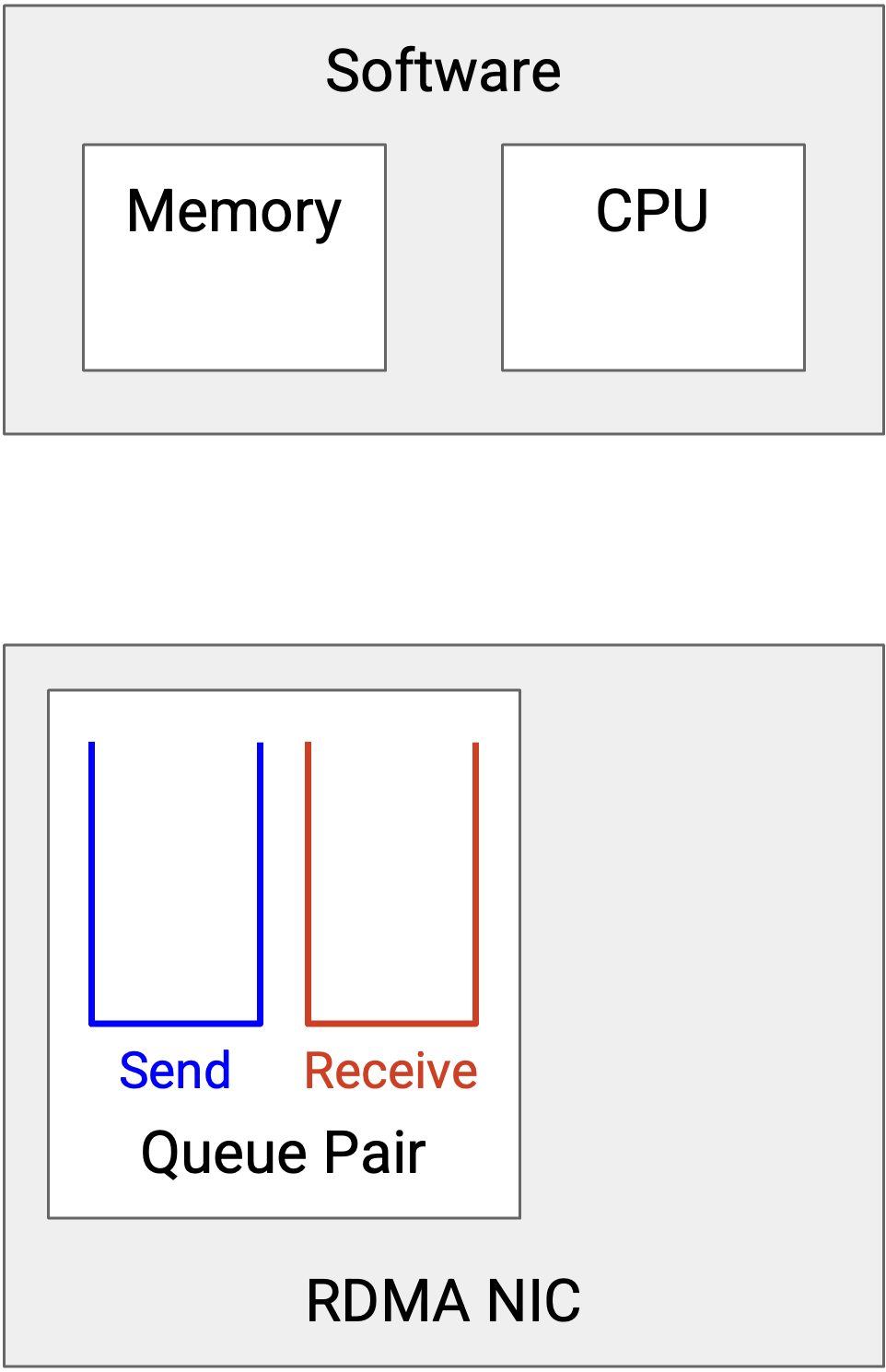
Queue 中的每个元素称为 work queue element(WQE)。WQE 允许 application 描述需要完成什么工作。用英语描述,receive queue 中的 WQE 可能会说:“Take 100 MB starting from address 0xffff1234 on the remote server, and write them to address 0xffff7890 in my local memory.” 在代码中,WQE 是一个包含这些 instruction 的 struct,例如一个指向接收数据写入位置的 pointer。
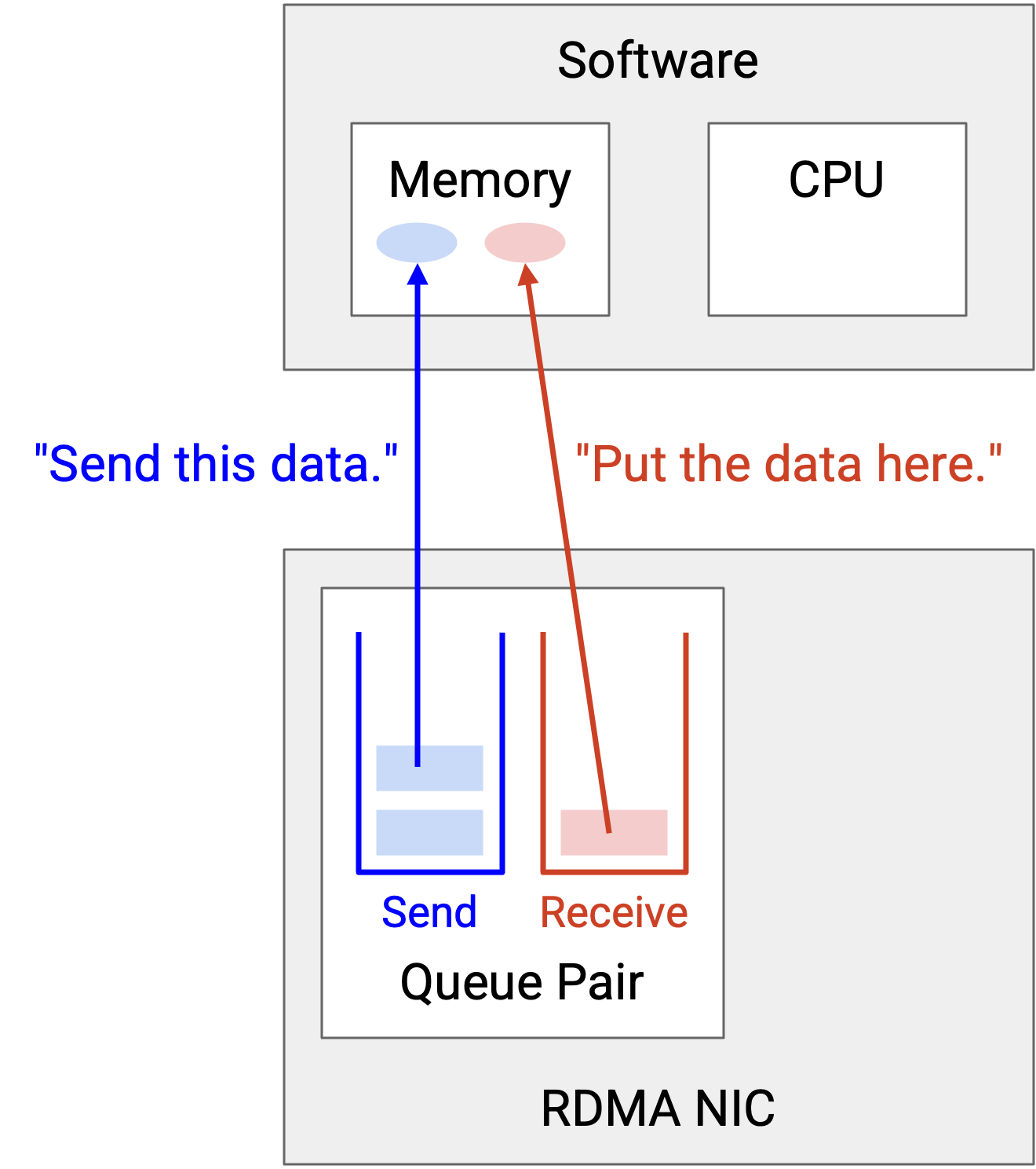
注意,WQE 抽象给了 RDMA protocol 一个更高层的 application 视图。在 TCP/IP stack 中,network 只看到 bytestream;但在 RDMA 中,WQE 允许 application 更详细地描述 job(例如指定正在传输的数据 block 的开始和结束)。
当一个 job 完成时,WQE 会从 queue 中移除,NIC 会创建一个新的 struct,称为 Completion Queue Element(CQE),描述这个 job 发生了什么(例如成功或失败)。这个 CQE 被存入 Completion Queue,并在那里等待,直到 application 准备读取 CQE 并理解这个 job 发生了什么。
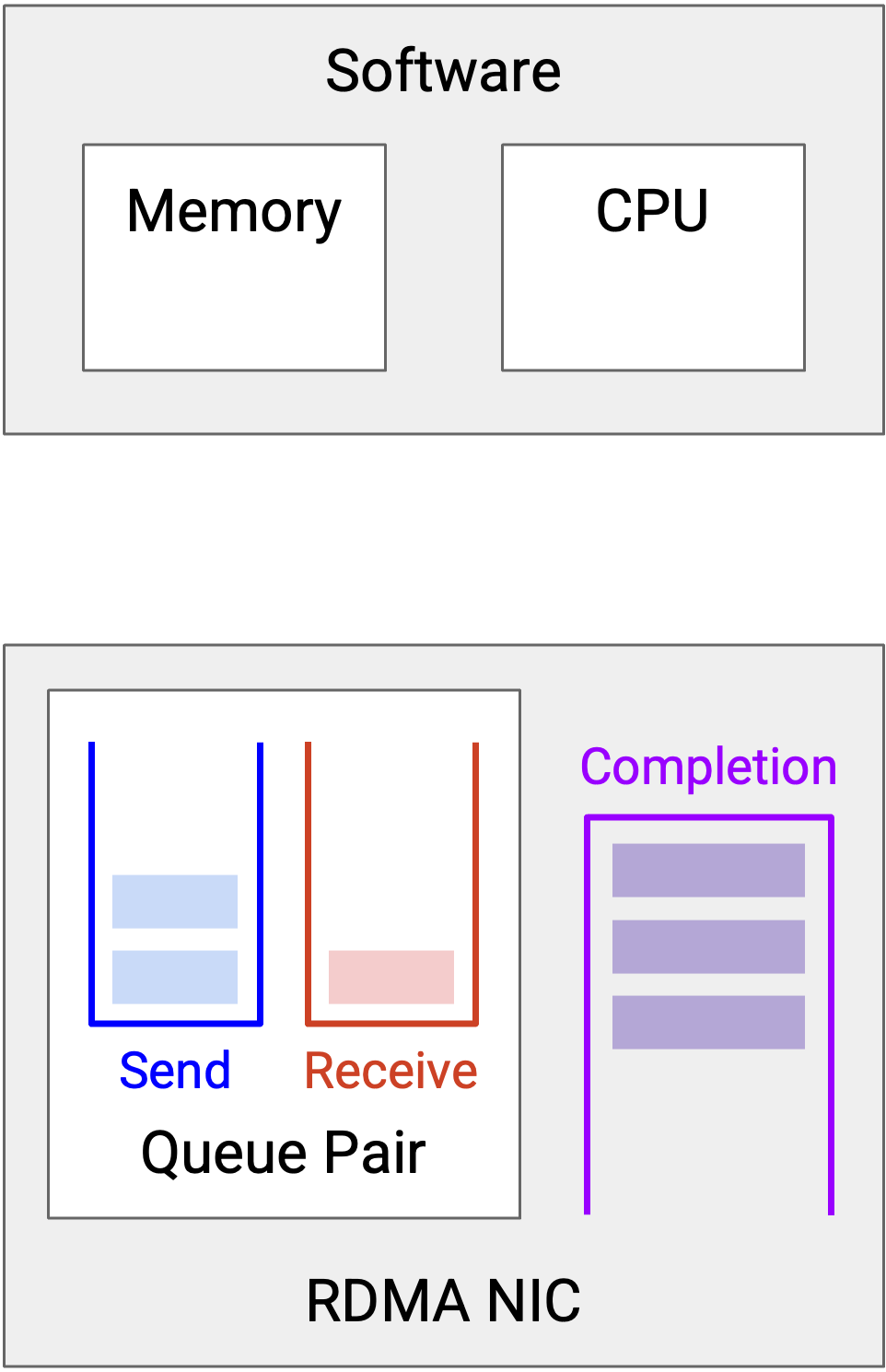
注意,RDMA 是 asynchronous 的。Application 可以随时把 job(WQE)添加到 queue pair,NIC 会按顺序处理这些 job。类似地,当 job 完成时,一个 CQE 会被放入 completion queue,而 application 可以在自己想要的时候读取 CQE。(这不同于 TCP/IP stack,在 TCP/IP stack 中,incoming data 会触发 interrupt,让 CPU 处理这些数据。)
RDMA 示例¶
RDMA 可用于 server 之间的多种不同操作。每种操作都有自己的性能规格(例如不同 latency),以及不同语义(例如不同 error message)。作为例子,让我们看一个 RDMA send operation,其中 Server A 从自己的内存读取一个 file,传输这些数据,而 Server B 把这个 file 写入自己的内存。
-
每台 server 都指定自己内存中的某个区域,让 NIC 可以为 RDMA transfer 访问。Server A 把与 file 对应的内存指定为 NIC-readable。Server B 指定一个空 buffer,它将用来接收 file,并让它对 NIC readable。

-
每台 server 设置 queue。两张 NIC 现在都有一个 send queue、一个 receive queue 和一个 completion queue。注意,这一步可以 out-of-band 完成,例如使用 TCP 这样的传统 protocol 在两台 server 之间协调。

-
Server A 在 send queue 中创建一个 WQE。这个 WQE 包含一个指向 file 的 pointer,表示要发送的数据。另一端,Server B 在 receive queue 中创建一个 WQE。这个 WQE 包含一个指向空 buffer 的 pointer,表示接收到的数据应该写到哪里。
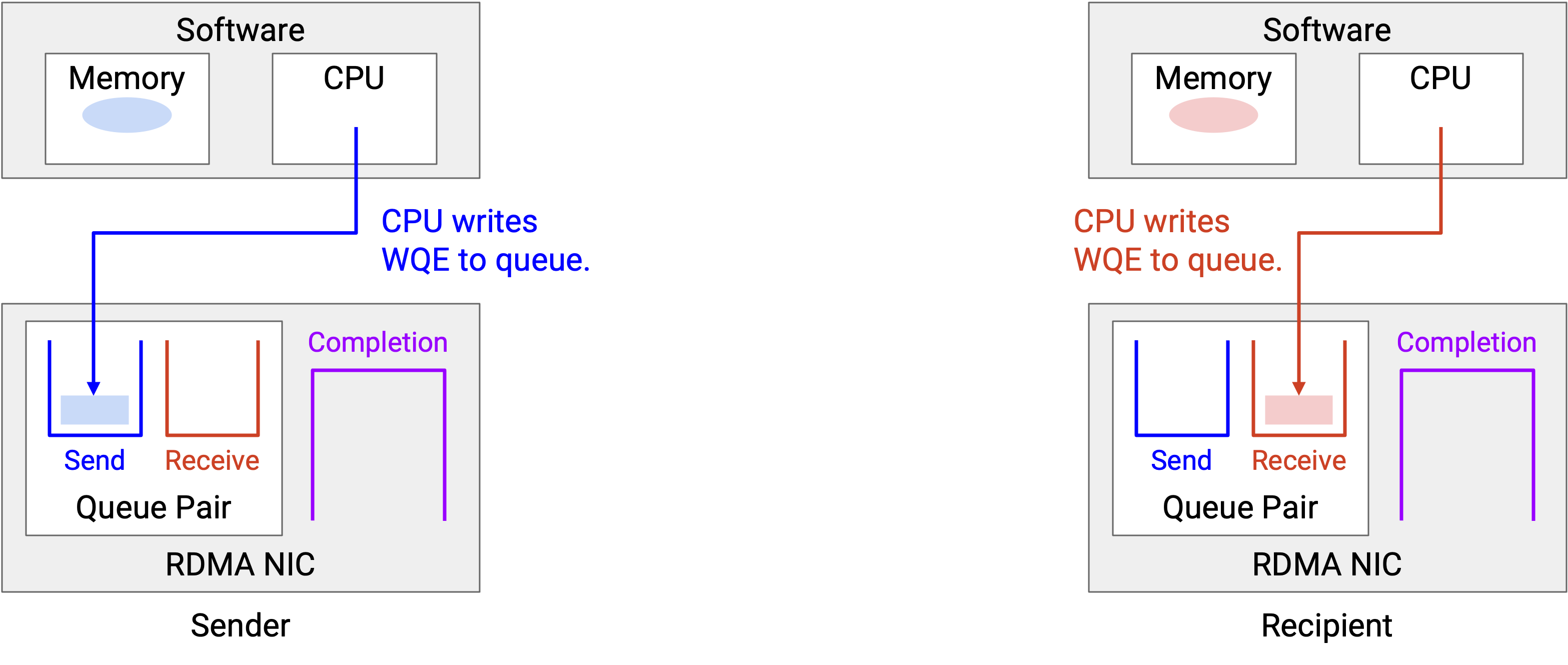

-
一旦两端都把 transfer 放入 queue,data transfer 就可以发生,且不需要软件参与。NIC 处理所有事情,包括 reliability、congestion control 等。
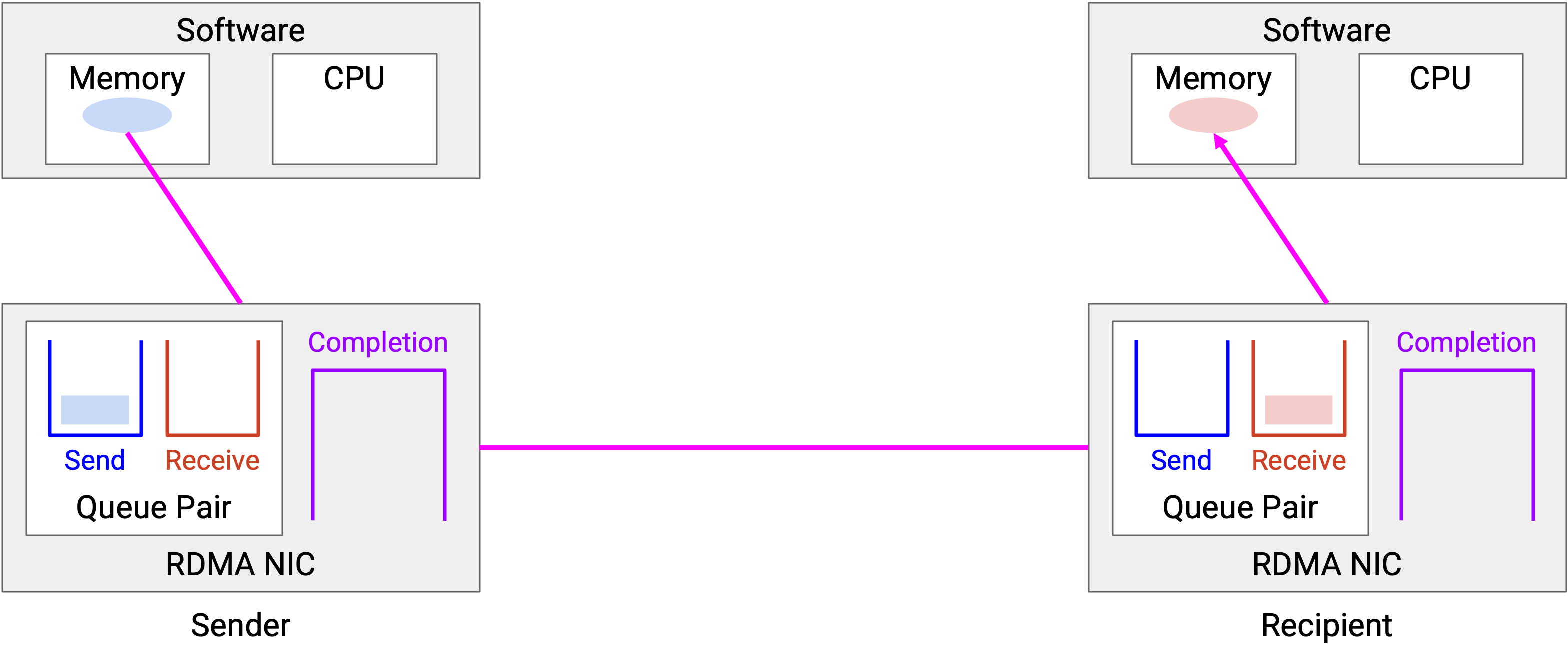
-
Transfer 完成后,WQE 会从 queue 中移除。两张 NIC 都会生成一个 CQE,表示 transfer 已完成,并包含所有相关 status message(例如 error message)。Server A 的 CQE 表示数据已成功发送,Server B 的 CQE 表示数据已成功接收。
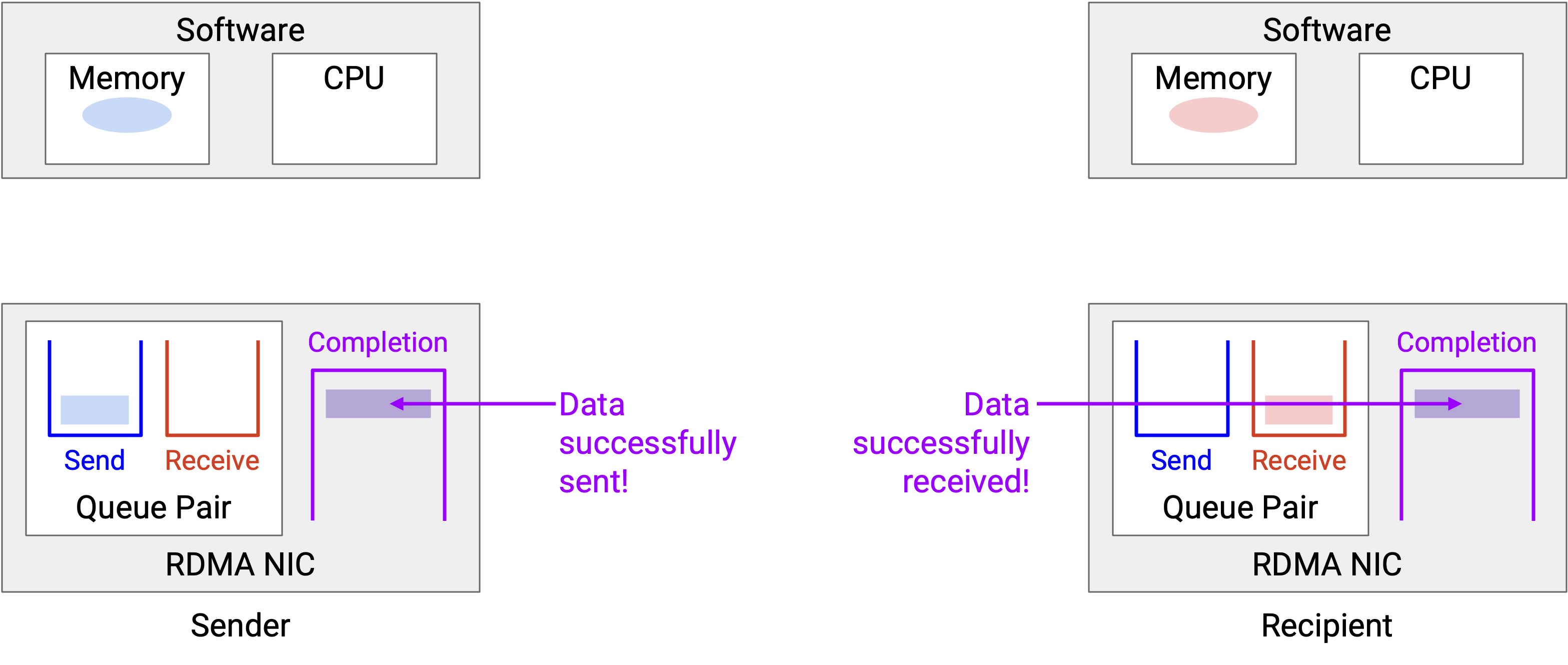
-
最终,application 读取 CQE,以理解这次 transfer 发生了什么。

RDMA 的优点、缺点和应用¶
RDMA 提供高性能 data transfer(低 latency、高 bandwidth),并释放 CPU 给 application 使用。不过,RDMA 并不是免费的。RDMA 需要专用硬件和软件,并且通常比传统 networking stack 更复杂。记住,RDMA 正在替代 TCP/IP stack,因此它必须直接在硬件中实现 TCP/IP 的所有功能,例如 reliability 和 congestion control。
RDMA 也有一些限制,并且通常最适合两台 server 在物理上彼此接近的 datacenter。如果两台 server 距离很远,主导 delay 来自跨 network 发送数据,而 RDMA 节省的时间可以忽略不计。相比之下,如果两台 server 距离很近,host 处理 packet 可能成为主导 delay,因此 RDMA 能显著节省时间。
RDMA 已经被应用在许多需要高性能、低 latency computing 的场景中。例子包括科学研究、金融建模、天气预报、machine learning 和搜索 query。在 cloud computing 中,RDMA 可用于把大型 VM 从一台 physical server 迁移到另一台,从而释放 CPU 给 customer 使用。在 AI/ML training 中,RDMA 不仅释放 CPU 并提供低 latency,还提供可预测 latency;当不同 server 需要协调来训练 AI/ML model 时,这一点很重要。
实现 RDMA¶
记住,RDMA 替代了 TCP/IP networking stack,因此 RDMA 负责 reliability、congestion control 等功能。如何实现这一点有两类广义思路。
一种选择是在 network 本身中实现这些 feature,例如在 switch 上实现 reliability。这是 Nvidia InfiniBand 背后的思想。
另一种选择是在 NIC 中、queue-pair abstraction 之下实现这些 feature。这是 Google 当前正在推进的思路。
在两种情况下,软件中的 application 和 OS 都会通过 queue pair abstraction 获得 reliable、in-order delivery 的错觉。这里的区别在于 RDMA 实际如何实现这些 service guarantee。