DVMRP¶
朴素算法:Flooding¶
回忆一下 multicast routing 的目标:我们有一个 destination 是 group 的 packet,router 需要协同工作,把这个 packet forward 给 group 的所有 member。
实现这个目标最朴素的方法是 flooding。当 router 收到一个 packet 时,它直接把这个 packet 从每个 port 转发出去(除了 incoming port)。
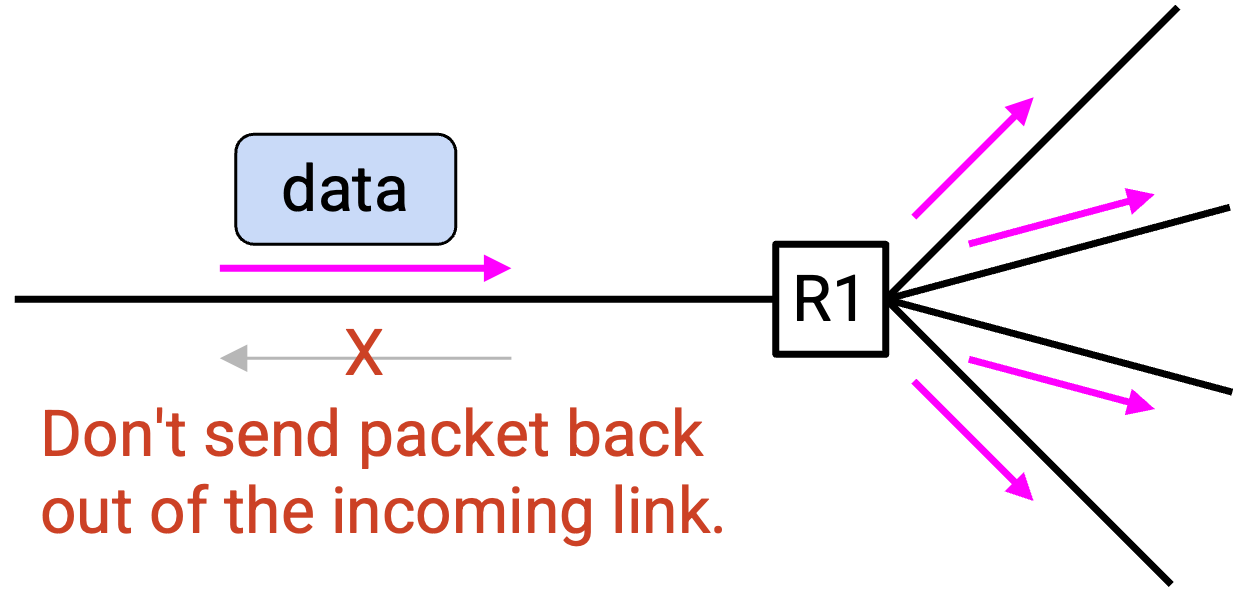
为什么 flooding 有效?它确保 network 上的每个 host 都收到 packet,而这会包括目标 group 的所有 member。
Flooding 有什么好处?概念上简单,而且不需要运行任何 routing protocol。
Flooding 有什么问题?有两个主要问题,我们会逐一解决:
-
Flooding 会沿多条 path 发送相同数据,浪费 bandwidth,而这些数据本来只需要沿一条 path 发送。
-
Flooding 会把 packet 发送给非 member,浪费 bandwidth。
另外,loop 可能导致 broadcast storm,使同一个 packet 在 loop 中被无限 forward。不过,如果让 router 在见过某个 packet 后丢弃它,就可以解决这个问题。
Reverse Path Broadcasting(RPB)¶
我们先关注第一个问题。(注意:这意味着目前我们仍然会把 multicast packet 发送给所有人,包括非 member。这个问题稍后解决。)
Flooding 会正确地把 packet 发送给所有人,但会沿 redundant link 浪费数据。例如,如果 R1 和 R4 之间有多条 path,flooding 会让 packet 的副本沿从 R1 到 R4 的每条 path 传输。然后,R4 会丢弃 packet 的所有重复副本。
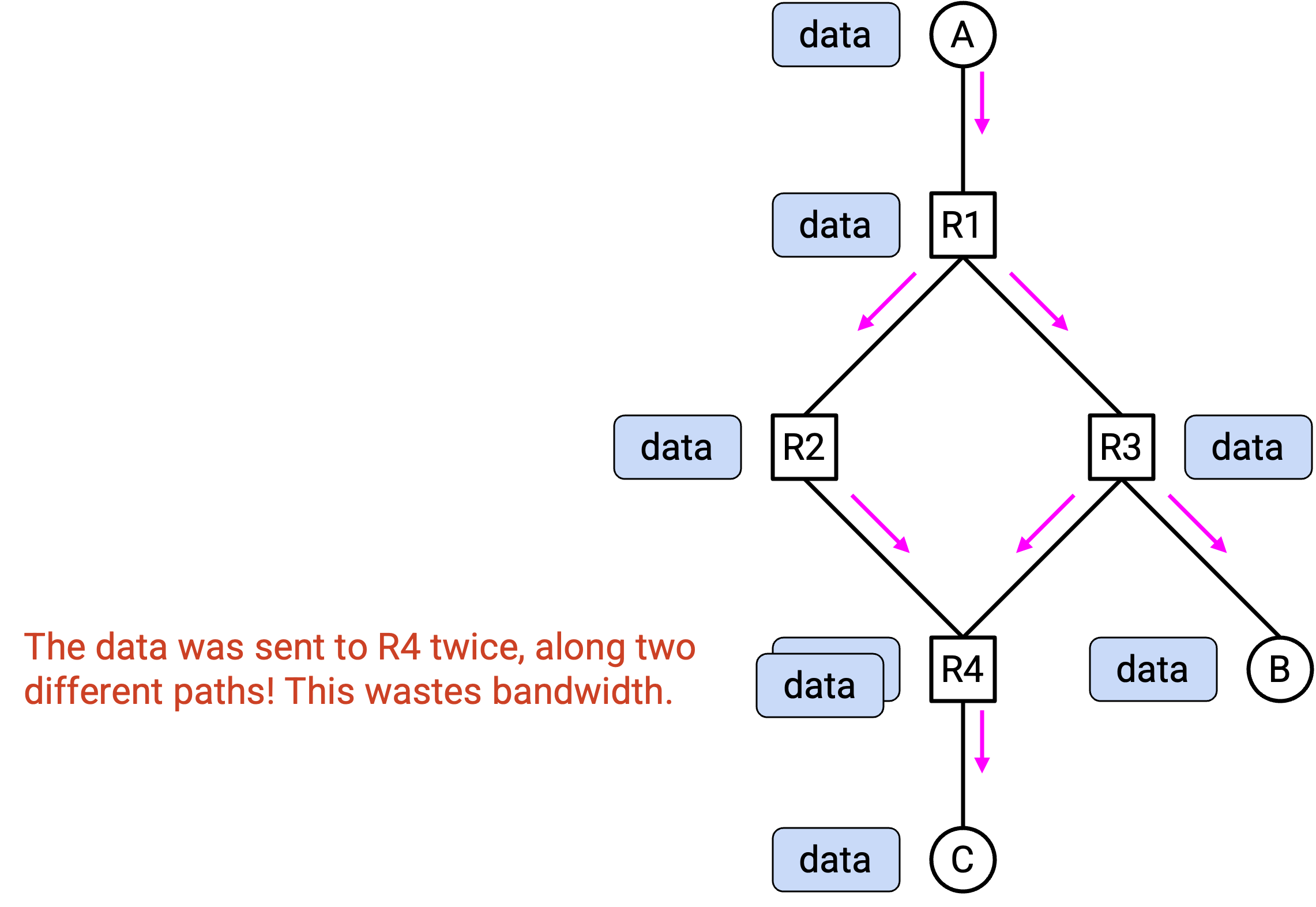
理想情况下,我们希望 packet 只沿一条 path 从 R1 传到 R4,并且在任何其他 router pair 之间也同样如此。
我们希望 packet 在任意一对 node 之间只走一条 path。这让你想起什么数据结构?Tree 在任意一对 node 之间只有一条 path!
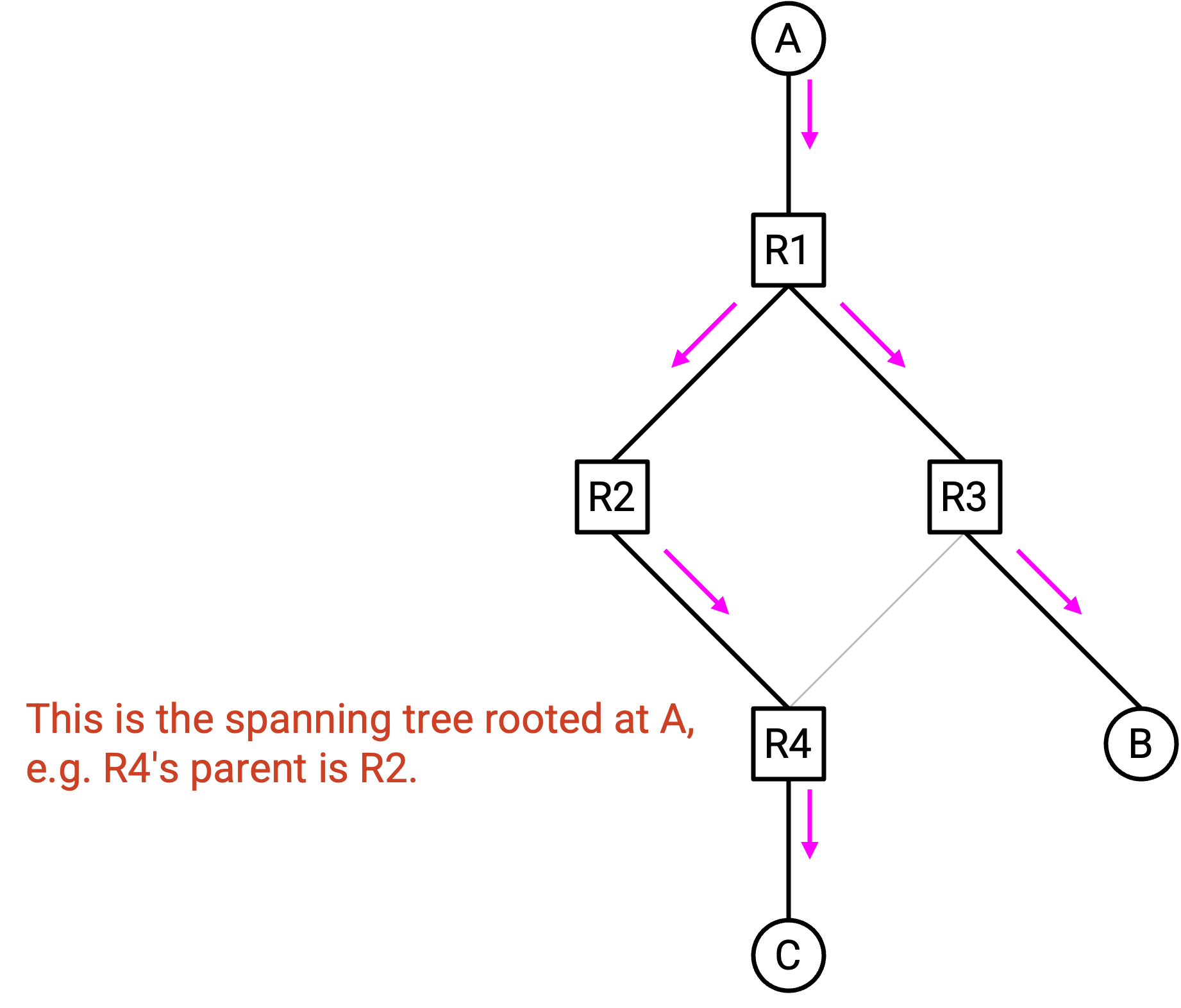
具体来说,我们想构建一个 spanning tree,使每个人都只沿单一 path 收到 packet。
我们可以从头构建 spanning tree,但也可以更聪明一些,复用已经做过的工作。我们在哪里已经见过 spanning tree?
当我们为 unicast packet 运行 distance-vector routing 时,会构建一棵指向 destination 的 spanning tree。这允许所有 packet 在 network graph 中“向上”流动,朝向单一 destination(tree 的 root)。
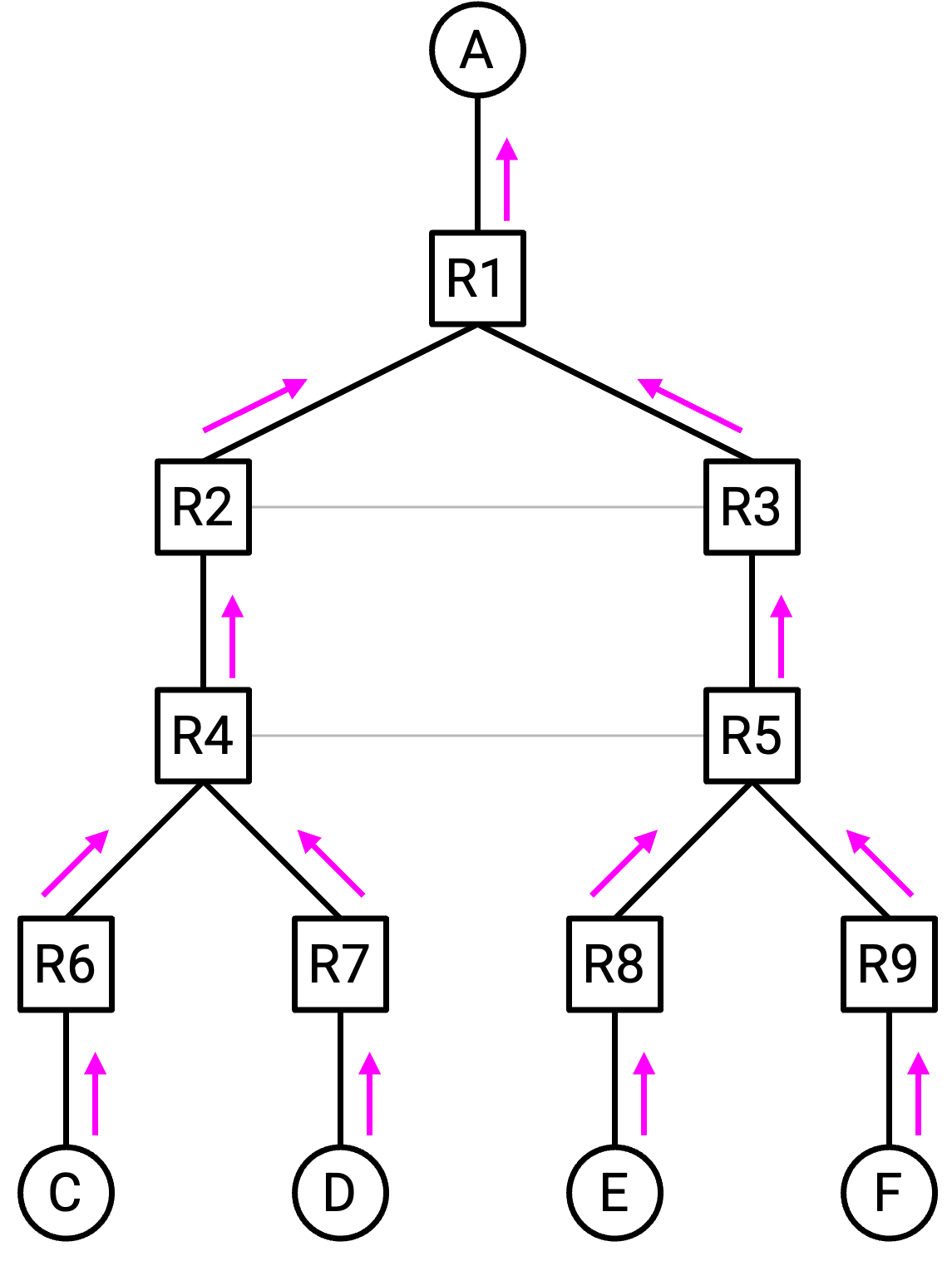
如果把这个 graph 中的所有箭头反过来,我们就得到了一棵适合 multicast packet 的 spanning tree。Tree 的 root 现在是 sender,packet 的副本在 network graph 中“向下”流动,远离 sender,穿过 network 到达每个 destination。
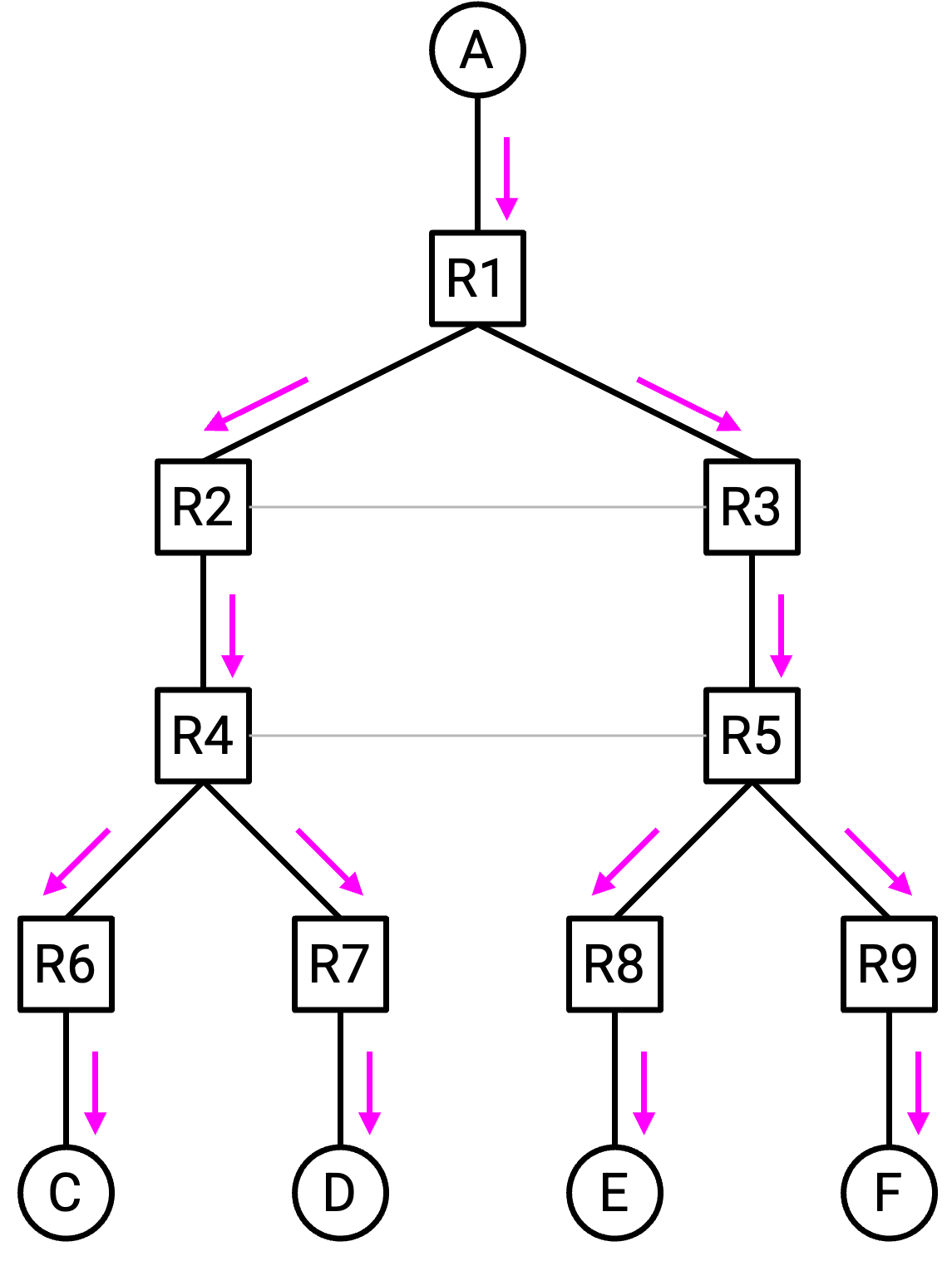
此时,继续思考反向箭头可能会让人困惑,所以我们换一组更不容易混淆的术语。在 router tree 中,每个 router 恰好有一个 parent,以及零个或多个 child。Tree “顶部”的 router 是 root,tree “底部”没有 child 的 router 称为 leaf。(这些定义和你在任何数据结构课程中习惯的定义一样,没有特殊之处。)
当我们思考 unicast routing 时,root 是 destination。每个人从自己的 child 收到 packet,并把 packet forward 给自己的 parent,“向上”朝 destination 传输。
相比之下,当我们思考 multicast routing 时,root 是 source。每个人从自己的 parent 收到 packet,并把 packet forward 给自己的 child,“向下”穿过 network 到达每个 destination。
总结一下,multicast routing 的 forwarding rule 是:如果你从 parent 收到 packet,就把它发送给所有 child。否则,如果你从其他人(不是 parent)那里收到 packet,就丢弃这个 packet。
这个规则帮助我们避免 packet 沿多条 path 发送。即使有多条 path 通向你,你也只会从 parent 收到一次 packet(并把它 forward 给 child)。如果你从其他人(不是 parent)那里收到 packet 的另一个副本,就会丢弃它。
RPM:学习 Parent 和 Children¶
我们实际如何实现这个规则?每个 router 需要知道自己的 parent,以及所有 child。
弄清楚 parent 很容易。记住,这棵 tree 和 unicast routing 中 distance-vector 产生的 tree 完全相同。在你的 unicast forwarding table 中,到 root 的 next-hop 就是你的 parent!为了确定 parent,你只需要复用为 unicast routing 计算出的 forwarding table entry。
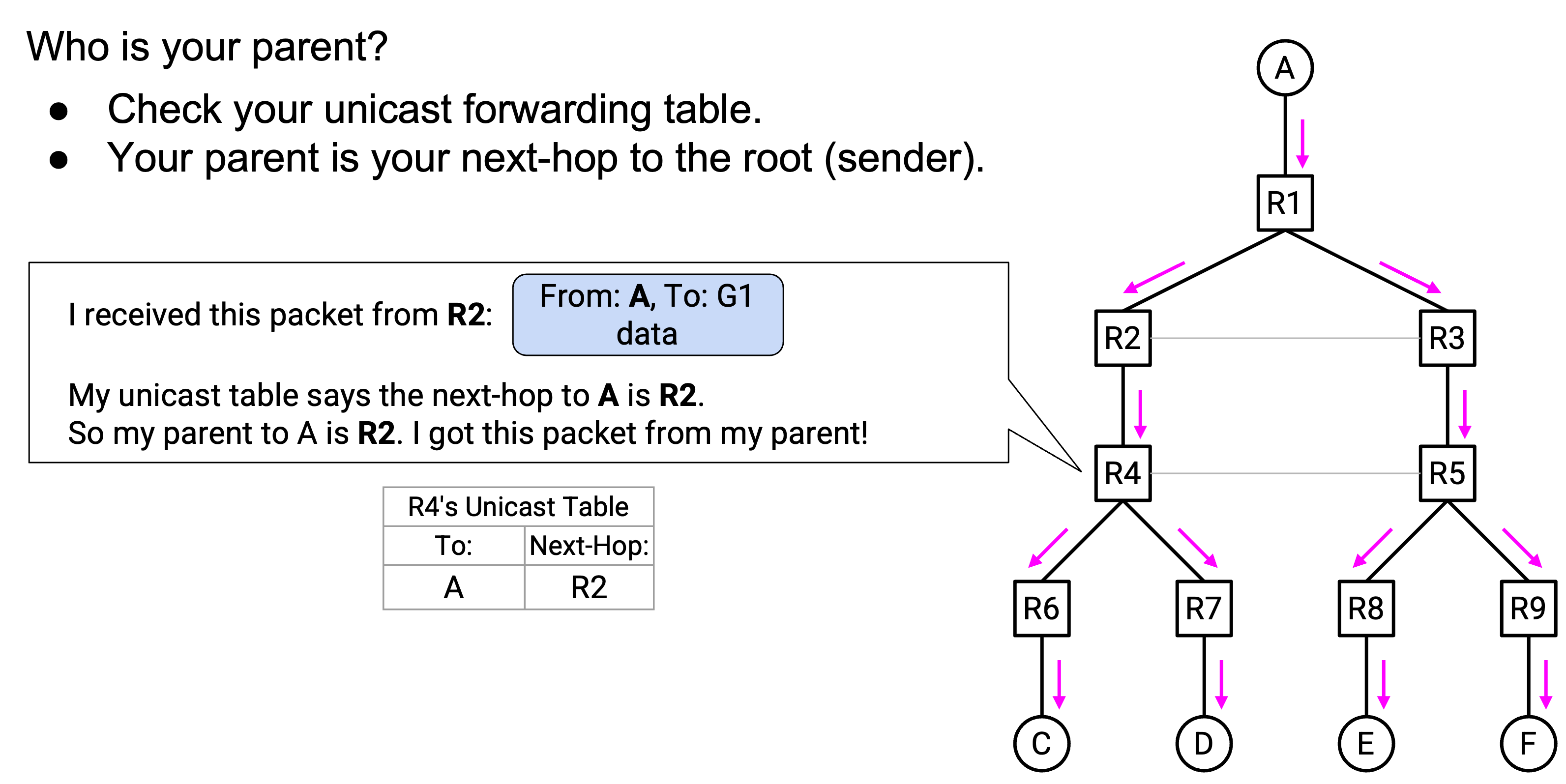
弄清楚 child 需要多一点工作。Forwarding table 只告诉你 parent(next-hop,朝向 root),但 forwarding table 没有关于 child(previous-hop,远离 root)的信息。
由于你不知道自己的 child,需要 child 告诉你他们是谁。具体来说,每个人都会向自己的 parent 发送 multicast routing advertisement,说:“我是你的 child(在以 A 为 root 的 tree 中)。”(记住,每个人都从 unicast forwarding table 中知道自己的 parent。)
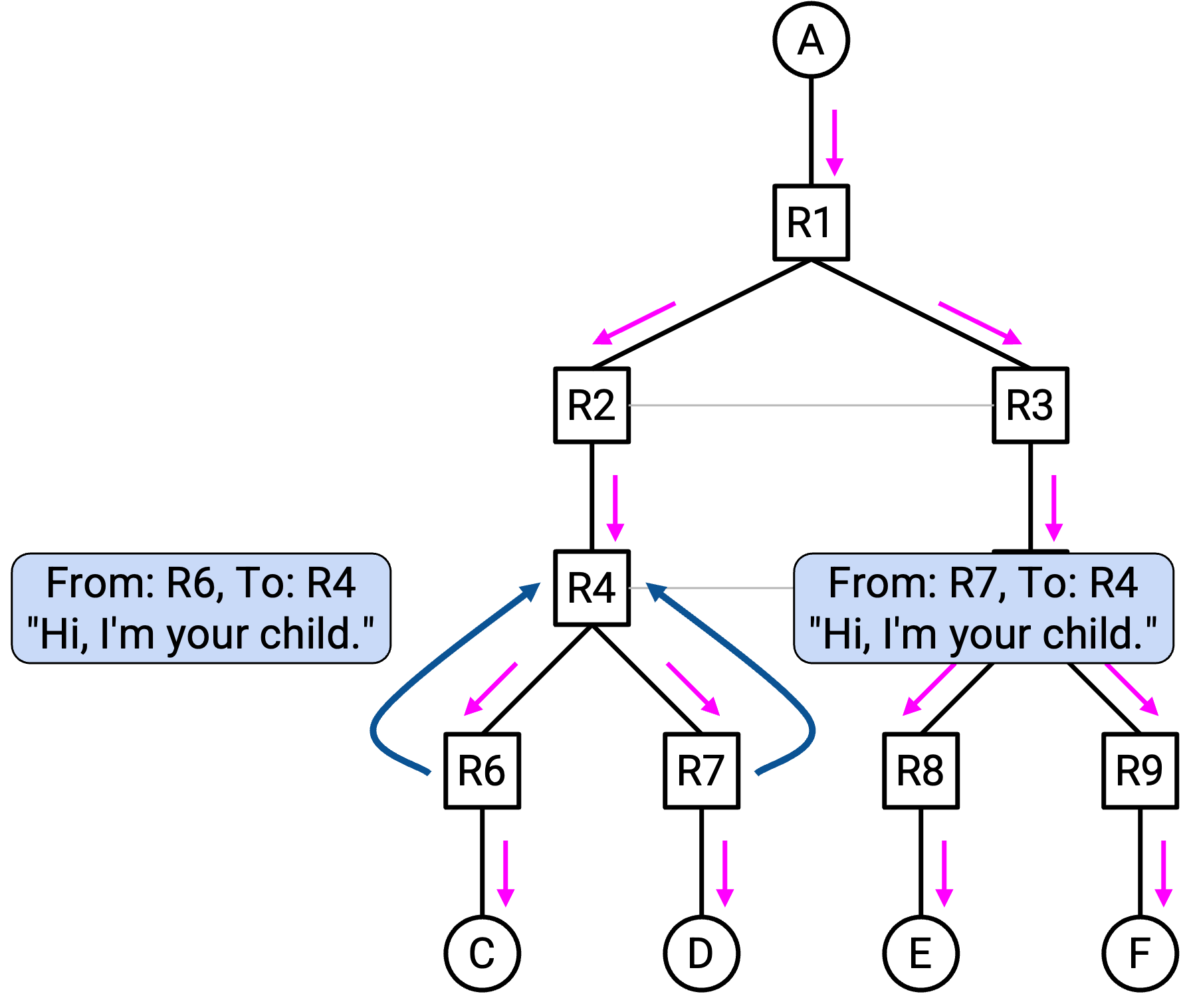
然后,每个 router 收到这些 advertisement,并存储关于自己 child 的额外信息。这是我们专门为 multicast routing 添加的新信息。这个新的 multicast forwarding table 与我们在 unicast routing 中使用的 forwarding table(也就是用于确定 parent 的 table)是分开的。
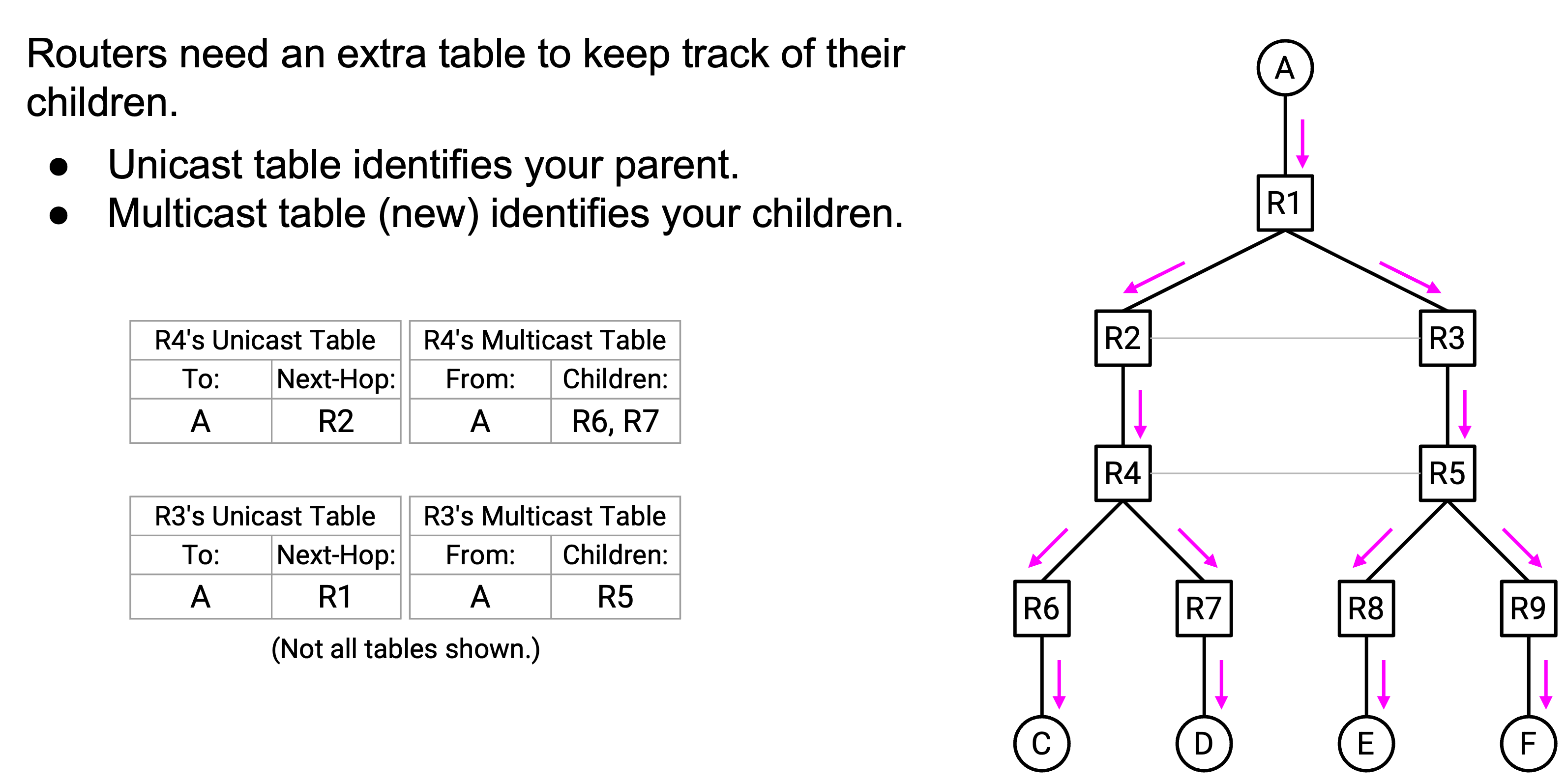
总结一下,multicast 的 forwarding rule 是这样实现的。当你收到一个 packet 时,使用 unicast forwarding table(它列出你的 parent)检查这个 packet 是否来自你的 parent。如果 packet 来自 parent,就使用新的 multicast forwarding table(包含来自 child 的 advertisement)把它 forward 给 child。
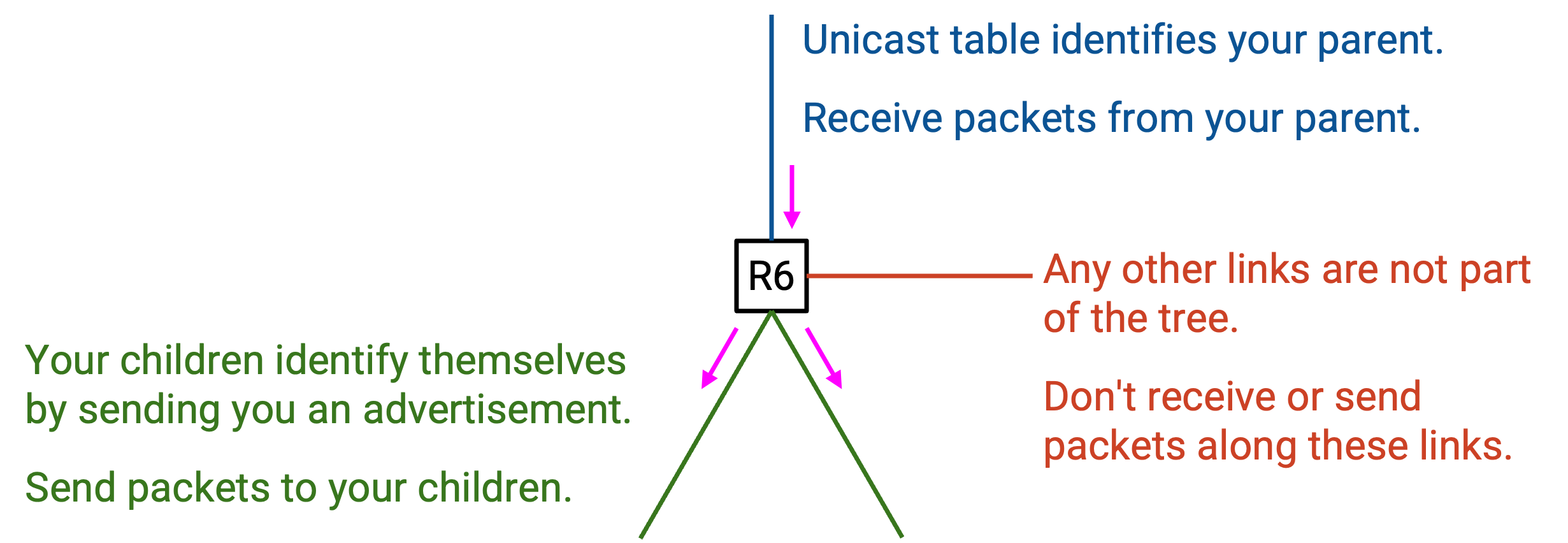
现在我们有了两个 forwarding table,停下来想想每一个如何使用。Unicast forwarding table 列出你的 parent。这个 table 用于像标准 distance-vector routing 那样,把 unicast packet 发送到 destination。这个 table 也用于检查一个 multicast packet 是否来自你的 parent。最后,这个 table 还用于发送 multicast routing advertisement,告诉 parent “我是你的 child”。
Multicast forwarding table 列出你的 child。这个 table 通过接收来自 child 的 advertisement 构建。这个 table 用于把 multicast packet forward 给你的所有 child。
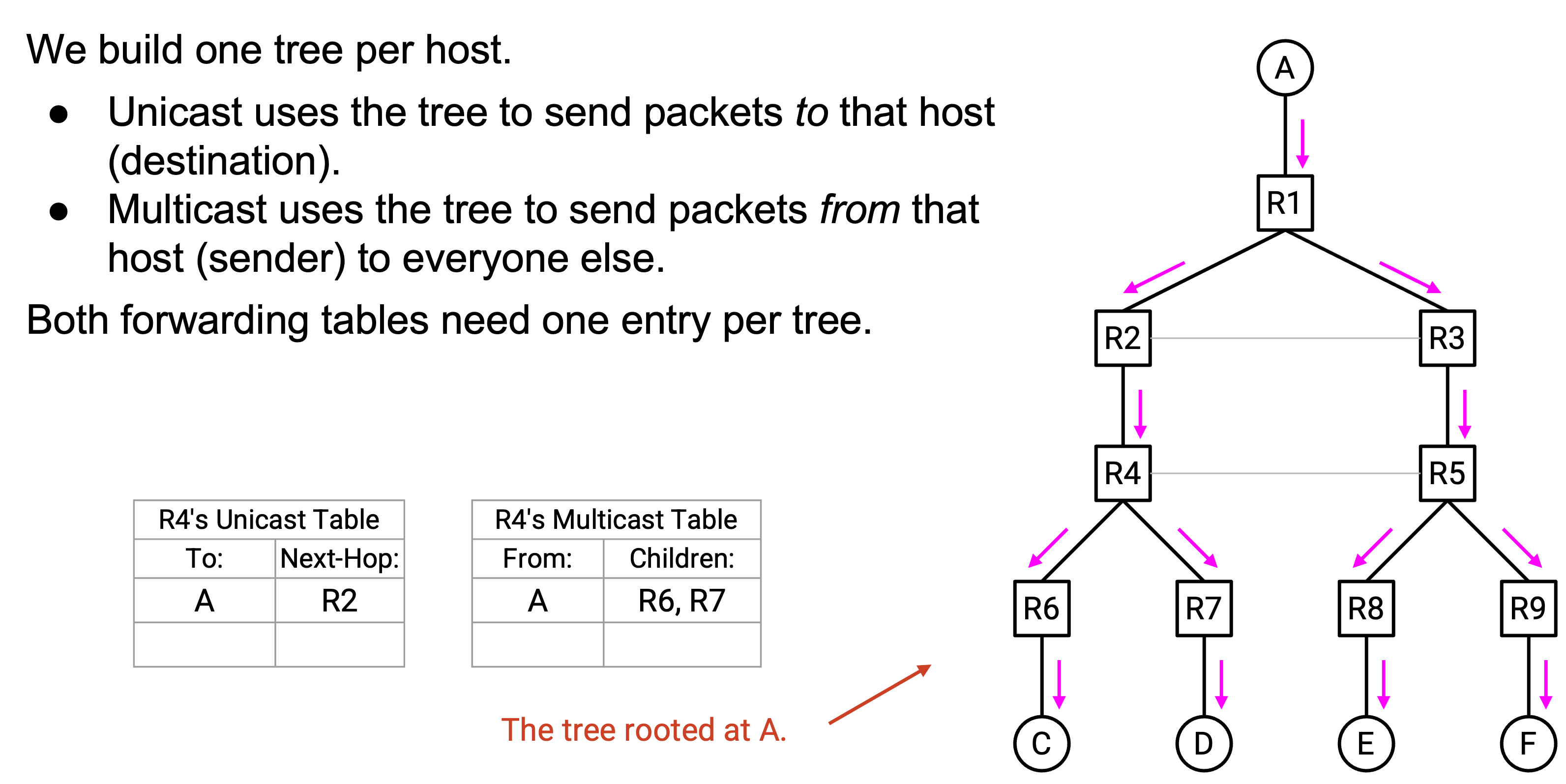
最后一个重要观察:在 distance-vector unicast routing 中,我们为每个 destination 构建一棵 spanning tree。因此,我们的 unicast forwarding table 对每个 destination 都有一个 next-hop。换句话说,对于每个 destination,你在那棵特定 tree 中有一个 parent。
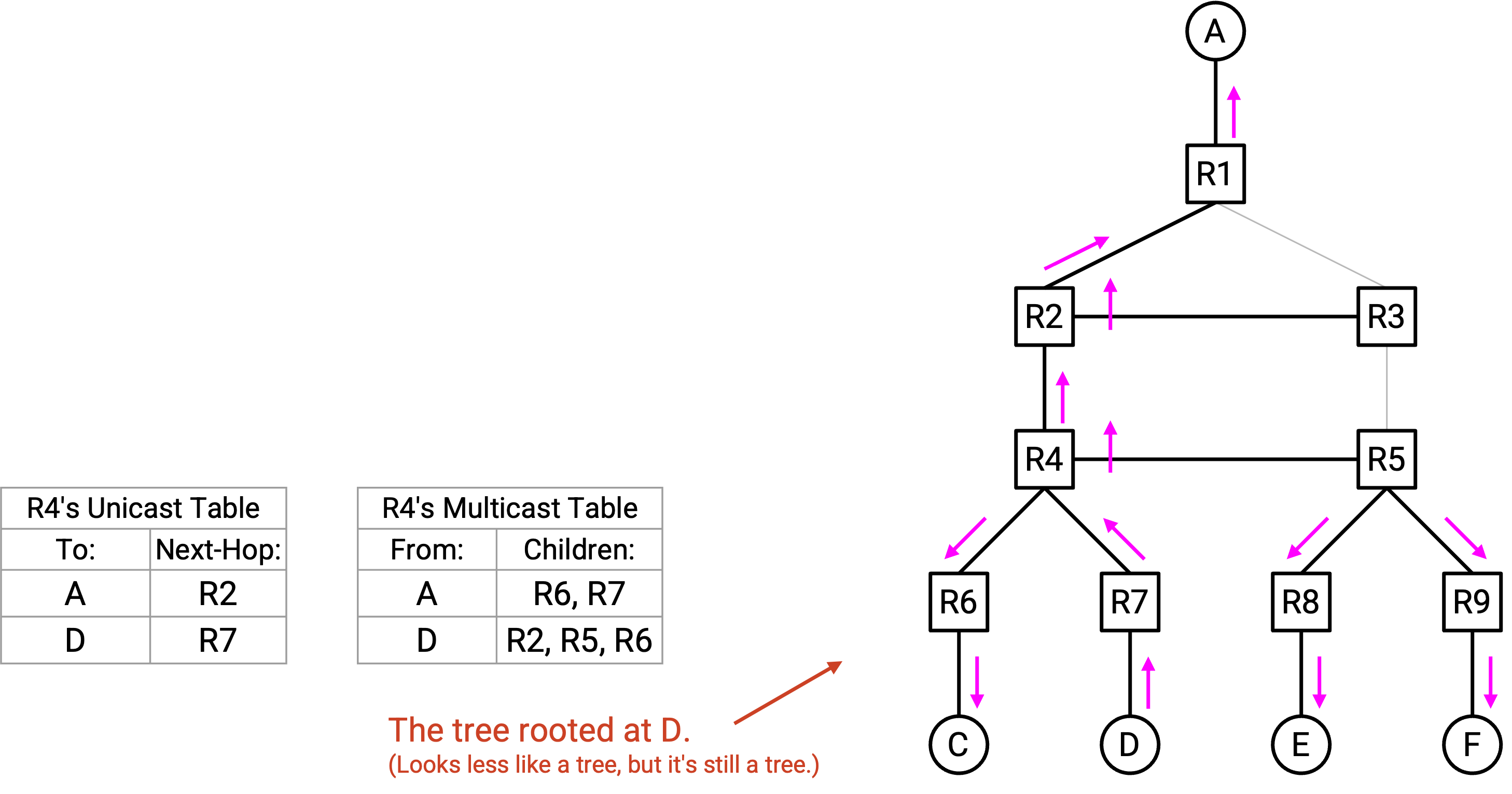
当我们反转箭头后,现在会为每个 source 得到一棵 spanning tree。我们的 multicast forwarding table 对每个不同 source 都有一组 child。换句话说,一个 multicast forwarding table entry 可以解释为:“如果你收到来自 source A 的 packet,就 forward 给 child R6、R7。”
Reverse Path Multicasting(RPM):Pruning¶
我们的 Reverse Path Broadcasting 规则确保 packet 沿 spanning tree 传输,从 source(root)开始,“向下”穿过 network 到达所有 destination。使用 tree 解决了第一个问题(packet 走多条 path,浪费 bandwidth)。
不过,我们仍然需要解决第二个问题。到目前为止,我们的 packet 仍然被 broadcast 给所有人,包括不在 group 中的 host。这会浪费 bandwidth。
为了解决这个问题,我们会 prune(剪枝) 这棵 tree,切掉任何没有 group member 的 branch。
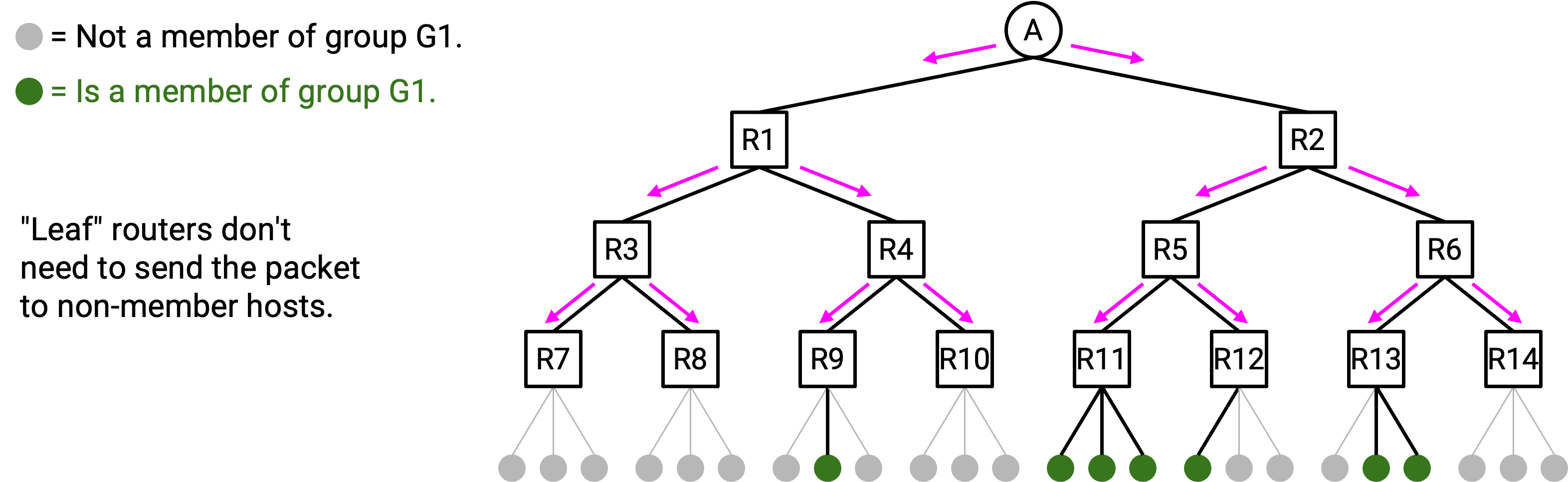
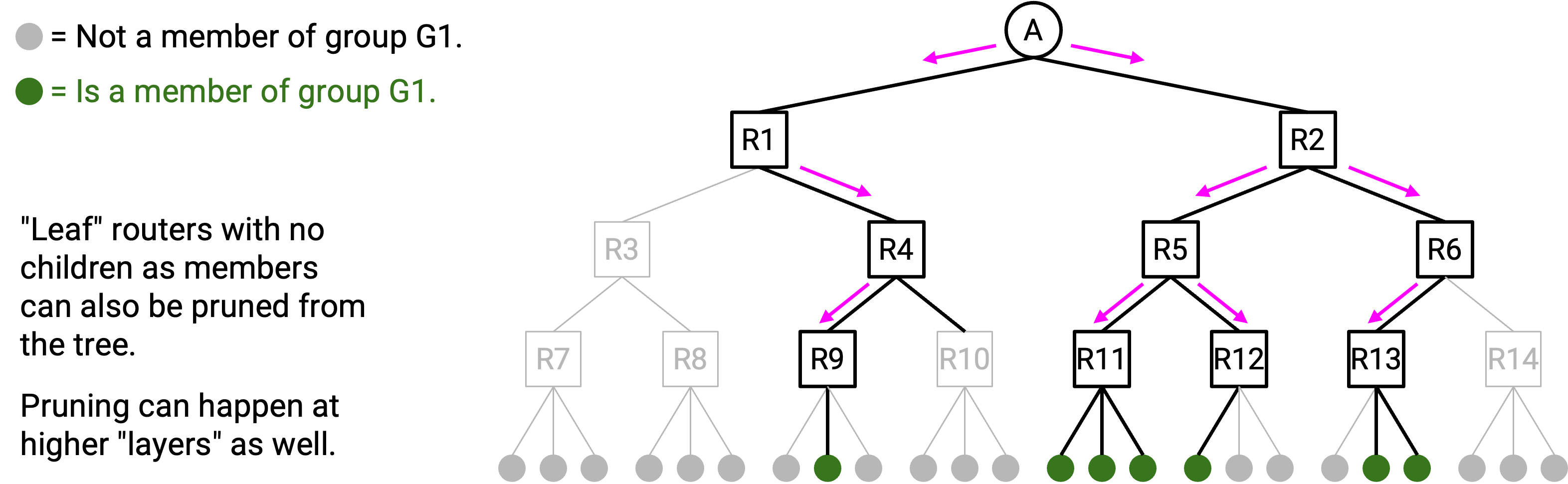
Pruning 从 child 向 parent 传播。假设你是 R5,并且直接连接了 3 台 host。使用 IGMP(也就是与这些 host 交谈),你得知它们都不在这个 group 中。这意味着你没有理由成为这棵 tree 的一部分。
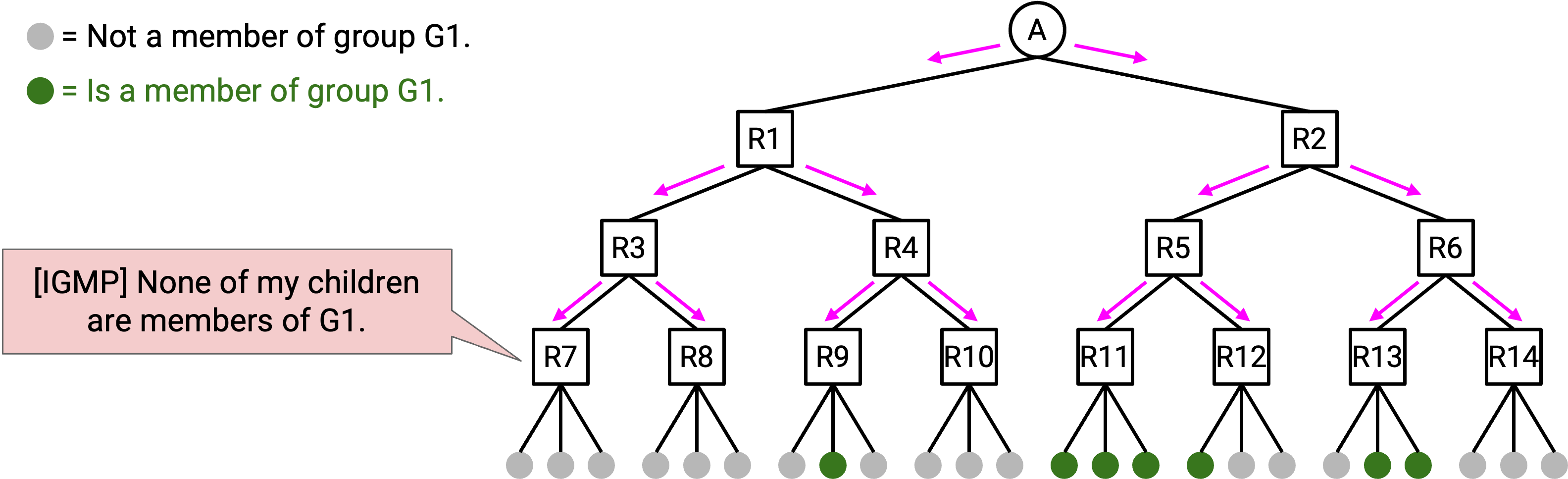
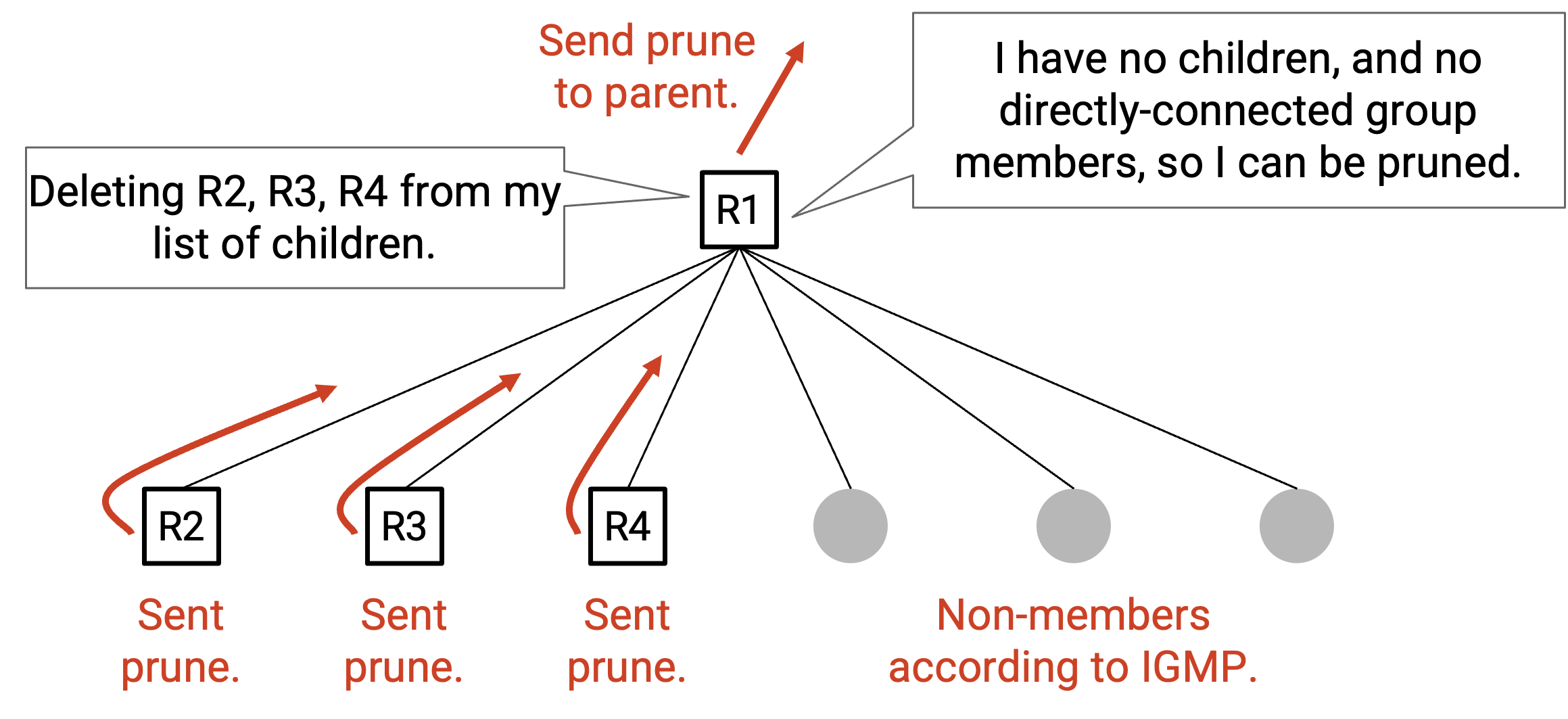
你可以向 parent 发送一条 advertisement:“我是你的 child,但我的 descendant 中没有任何人参与这个 group,所以不要给我发送 data packet。” 你的 parent 随后可以相应更新自己的 multicast forwarding table entry,使你不再是 child 之一。注意,pruning message 只发送给你的直接 parent(不会再继续 forward)。
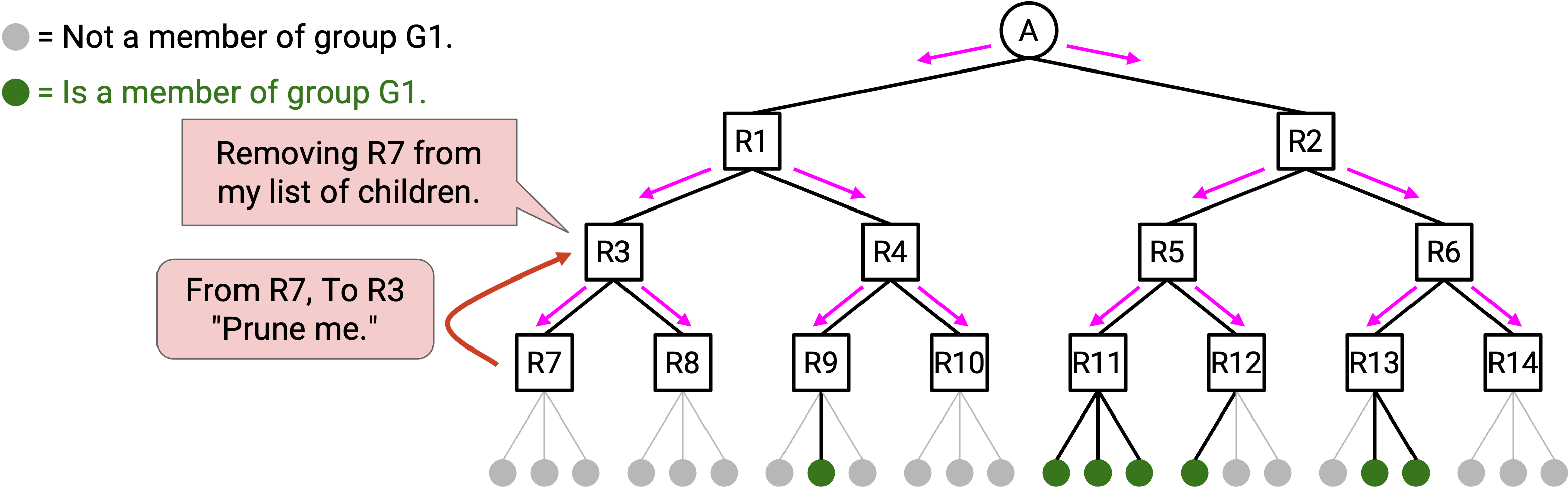
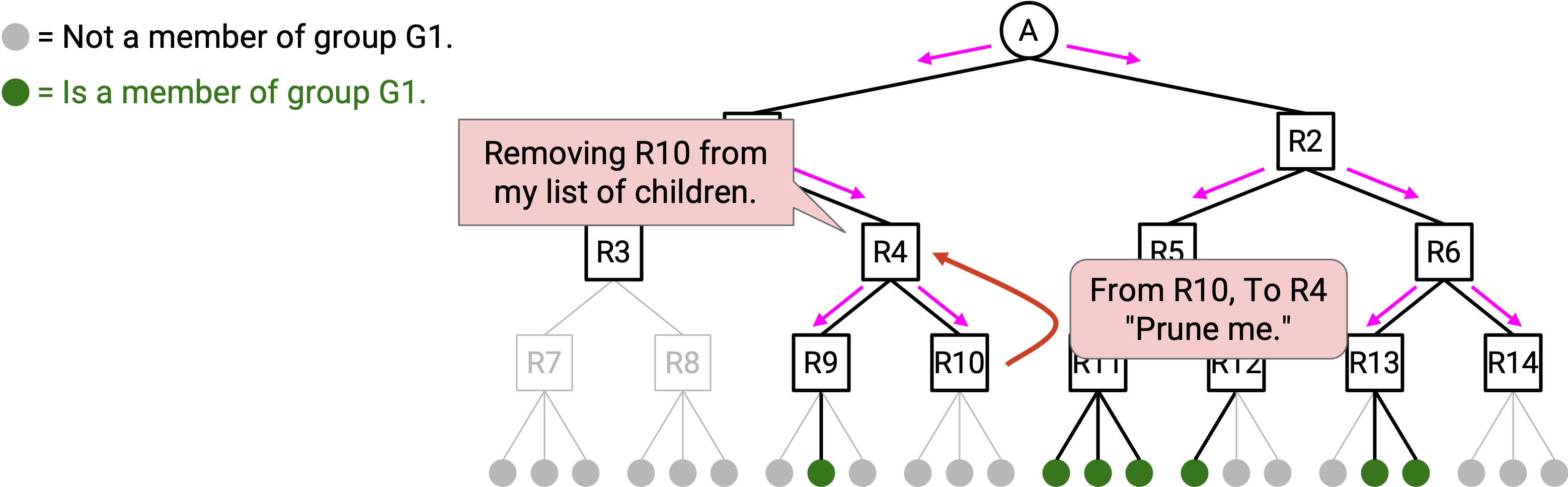
Pruning 也可以发生在 tree 的更高层。考虑 R3,它是一个有 2 个 child 的 router。假设两个 child 都发送 pruning advertisement,说它们不参与这个 group。如果你的 child 都不参与这个 group,那么你也没有理由参与这个 group。因此,你也可以把自己从这棵 tree 中移除。做法是向 parent 发送 pruning advertisement,让 parent 停止给你发送 data packet。
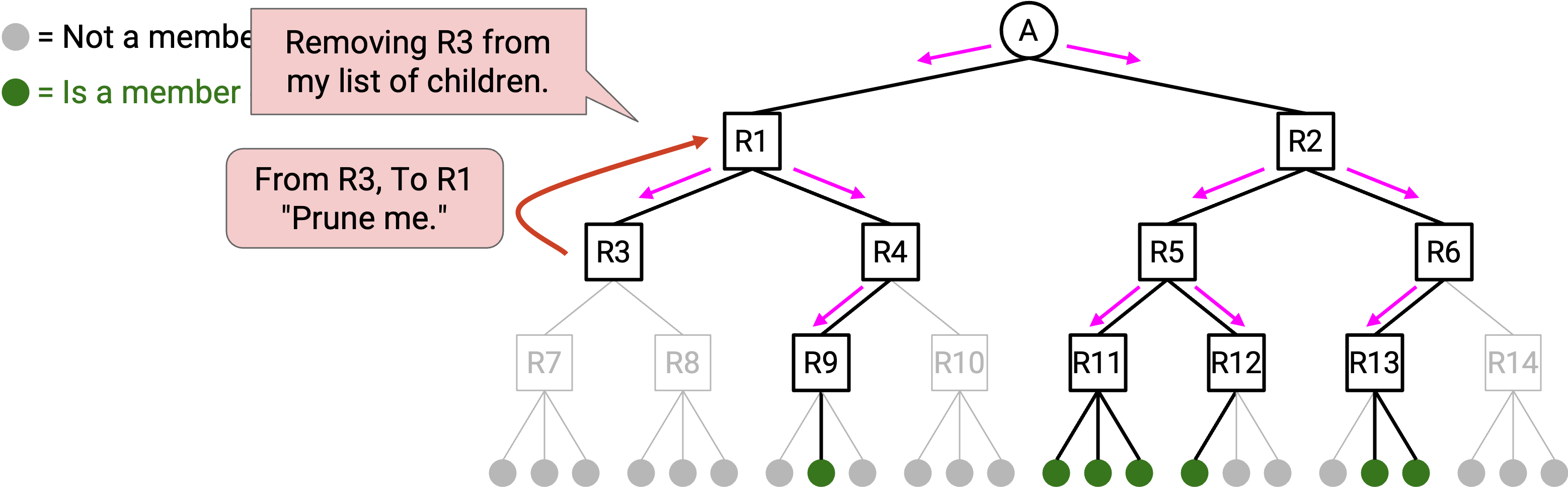
注意:较高层的 router 可能同时有 child router 和 directly-connected host。在这种情况下,只有当所有 child 都发送 pruning advertisement,并且所有 directly-connected host 都不属于这个 group 时,这个 router 才能把自己从 tree 中移除。
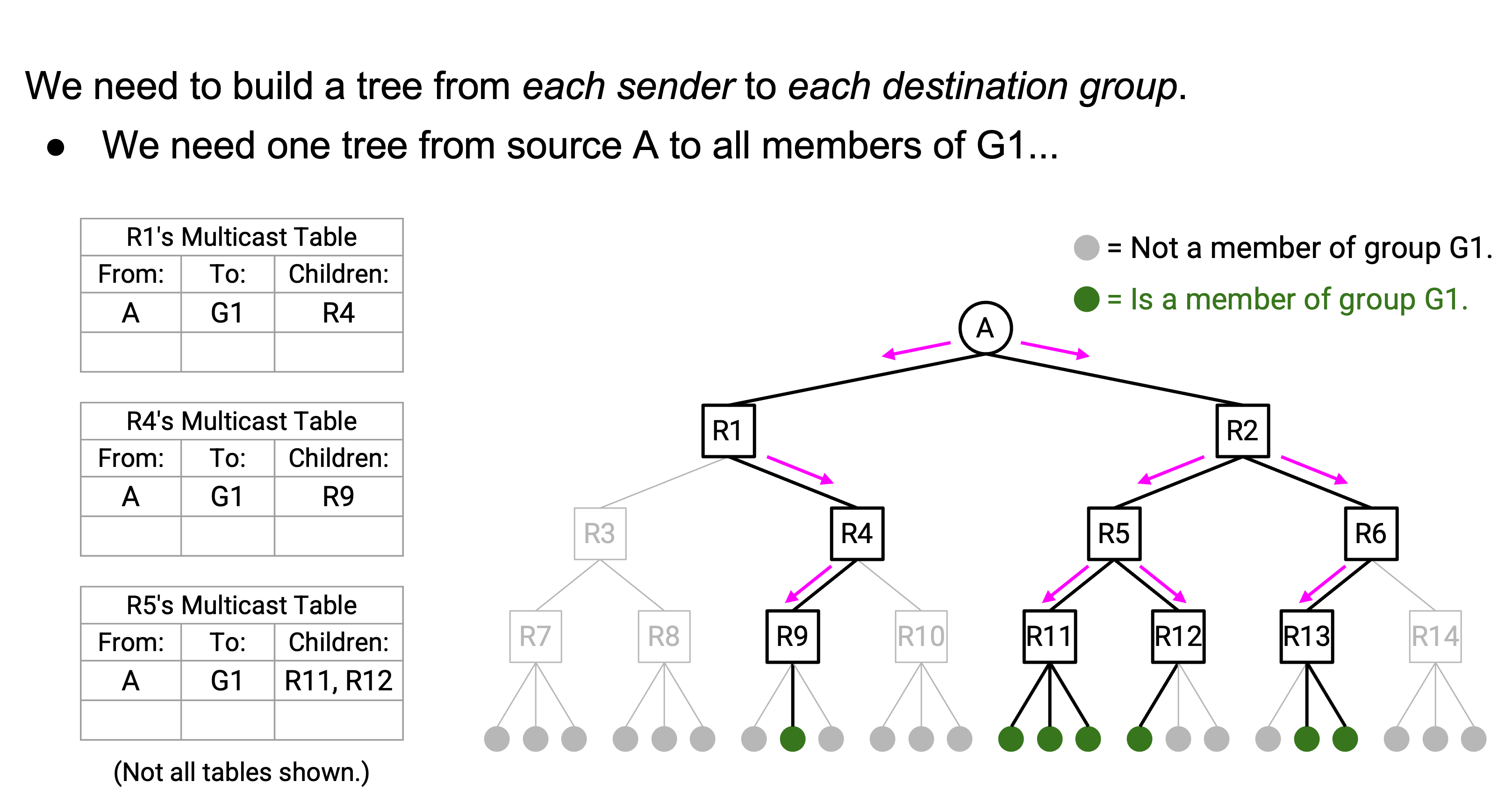
Pruning 让 multicast forwarding table 稍微更复杂。到目前为止,每个 entry 把一个 source 映射到一组 child:“如果你收到来自 source A 的 packet,就 forward 给 child R11、R12。” 不过,现在 child list 还取决于 destination group。例如,可能 R11 和 R12 都有属于 group G1 的 descendant。但是,只有 R11 有属于 group G2 的 descendant(也就是 R12 给你发送了 prune message)。
为了解决这个问题,我们的 multicast forwarding table 必须为每个 source、每个 group 都有一个 entry。例如:“如果你收到来自 source A、去往 group G1 的 packet,就 forward 给 child R11、R12。”
另一个单独的 entry 会是:“如果你收到来自 source A、去往 group G2 的 packet,就 forward 给 child R11。”
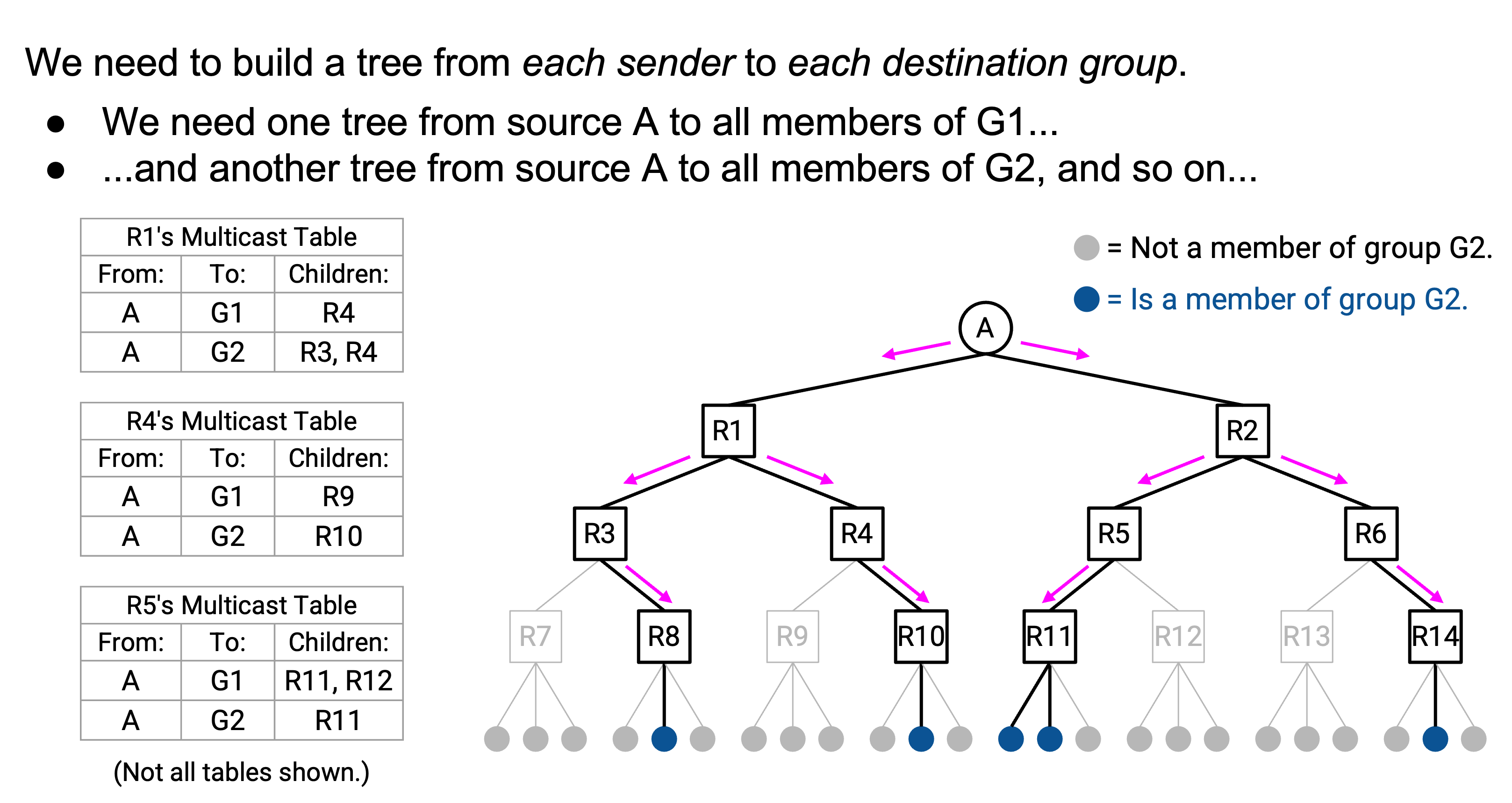
另一种理解这个修改的方式是:之前,我们每个 source 有一棵 tree,显示这个 source 如何向其他所有人发送 multicast packet。不过,现在我们会根据 destination group 切掉 tree branch。因此,我们需要为每个 source、每个 destination group 都准备一棵 tree。
最后补充一点:现在可能没有任何 child 属于某个 group,但过一段时间后,你的某个 descendant 决定加入这个 group。为了解决这个问题,每个 router 会周期性清除自己的所有 pruning information,使没有任何人再被 pruned。这会让所有人恢复到原始 RPB 行为,也就是总是 forward 给所有 child。
这样,如果你的某个 descendant 已经加入 group,那么 timer 到期后,你就不再处于 pruned 状态,并重新加入 tree。另一方面,如果仍然没有任何 descendant 属于这个 group,你只需要再次向 parent 发送 pruning message,把自己再次从 tree 中移除。
DVMRP 规则总结¶
Routing Rules:
对于每个 source 的 spanning tree,你需要学习自己的 parent 和 child。
-
学习 parent:不需要任何动作。你的 unicast forwarding table 已经标识了你的 parent。
-
学习 child:每个人都向自己的 parent 发送 advertisement。当你收到这些 advertisement 时,就知道谁是你的 child。
Forwarding Rules:
-
当你收到一个 packet 时,使用给定 source 的 unicast forwarding table,检查这个 packet 是否来自你的 parent。
-
如果 packet 来自你的 parent,使用新的 multicast forwarding table 把它 forward 给 child。对于给定 destination,只 forward 给没有被 pruned 的 child。
-
否则,如果 packet 不是来自你的 parent,就直接丢弃这个 packet。
Pruning Rules:
对于每个 (destination group, source) pair:
-
如果你从某个 child 收到 pruning message,就从这个 destination group 的 multicast forwarding table entry 中移除这个 child。
-
如果你的 descendant(directly-connected host 或 child)都不属于这个 group,就向 parent 发送 pruning message。
-
周期性清除所有 pruning information(恢复为 forward 给所有 child)。
DVMRP 的优点和缺点¶
这个 routing protocol 有什么不好?
Pruning information 会被周期性清除。当这种情况发生时,packet 会再次被 broadcast 给所有人,直到 pruning 再次 convergence(回忆一下,没有 pruning 时,packet 会发送给所有人)。
Forwarding table 扩展性很差。Multicast forwarding table 需要为每个 source、每个 destination group 都有一个 entry。
这个 routing protocol 有什么好处?
DVMRP 是对现有 routing protocol(distance-vector)的一个简单、优雅的扩展。我们能够优雅地复用 unicast forwarding table 来帮助实现 DVMRP。例如,我们不需要费力思考如何识别 parent,因为这个问题已经替我们解决了。
因为我们复用了 distance-vector protocol 中的 delivery tree,所以生成的 tree 也是 least-cost tree。换句话说,它们给出了从 sender 到所有 group member 的最佳 path。这个性质就是我们说 IP multicasting 是 optimal 的原因:换句话说,就 network topology 中的 cost 而言,DVMRP 实现了可能的最佳性能。
把 multicast 和 unicast routing 绑定在一起的一个缺点是,切换 protocol 更困难。例如,如果我们把 unicast routing protocol 从 distance-vector 切换到 link-state,就也必须重新思考 multicast routing protocol。