Software-Defined Networking¶
为什么需要 Software-Defined Networking?¶
之前,我们看到 routing protocol 可以被调整来适应 datacenter 场景(例如 equal-cost multi-path)。如果我们想进一步针对自己特定 network 的约束和使用场景优化 routing protocol,会怎样?标准 routing protocol 可能就不再适用了。
在本节中,我们会探索 software-defined networking(SDN,软件定义网络),这是一种思考 routing 和 network management 的全新范式。在 routing 语境中,SDN architecture 会让一个集中式控制中心计算 route,并把它们分发给单个 router。我们会看到 SDN 在 datacenter 和 wide-area network 中如何工作,并讨论这种新方法的优点和缺点。
Software-Defined Networking 简史¶
虽然我们会把 SDN 看作专用 routing protocol 的一种新方法,但 SDN 范式最初是为了回应 management plane 中的麻烦而设计的。
回忆一下,management plane 对 network operation 至关重要。除非有人配置 router(例如给 link 分配 cost)并告诉它们要做什么(例如运行什么 routing protocol),否则 router 什么也做不了。另外,我们需要 router 报告 error,以保持网络持续运行。历史上,这类 management work 很多都是手工完成的。
尽管 management plane 如此重要,围绕它的创新却相对较少。在 control plane,我们已经见过许多不同的 routing protocol,但配置和控制 router 的方式演化得更慢。
在 Internet 的历史中,人们逐渐开始使用 script 以程序化方式与 network 交互。这些 script 把 operator 原本手工完成的工作变成代码实现(但没有太多智能)。例如,script 可以自动化把 router 和 link 添加到 network 的过程。用于修复 network 的 script 可能会说:如果某个 router failure,就检查它是否真的 failure,重启它;如果仍然没有修好,就报告给 operator。
尽管取得了一些进展,这些 management system 长期以来一直是 network operation 的 bottleneck。每次添加新 router 时,我们仍然可能不得不等待人工介入。
2005 年,Albert Greenberg 等人的一篇 paper 这样描述这个问题:“Today's data networks are surprisingly fragile and difficult to manage. We argue that the root of these problems lies in the complexity of the control and management planes.”
为了回应这些问题,研究者开始思考运行 network system 的不同方式。这带来了更激进的提案,重新想象 router 的基本设计。
我们将看到的概念最早在 2003 年被考虑过,不过当时没有形成太大 momentum。Network management 中的挫败感加速了新 management paradigm 的发展。到 2008 年,momentum 更强,并最终带来了 OpenFlow switch interface(我们很快会看到)。
到 2011 年,行业显然正在朝这个新方向发展,于是 Open Networking Foundation(ONF)由主要 network operator(Google、Yahoo、Verizon、Microsoft、Facebook)和 vendor(Cisco、Juniper、HP、Dell)共同成立。Nicira 是一家专注 SDN 的 startup,开发了 OpenFlow interface,2012 年时估值为 $40 million。
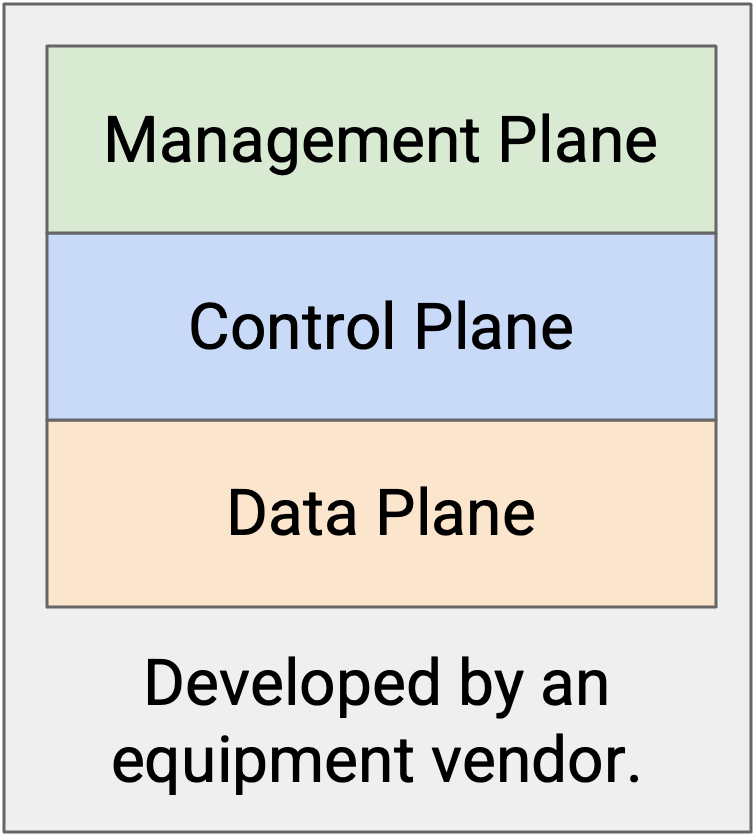
Router 是垂直集成且标准化的¶
如果我们想重新想象 router 的设计,实践中会如何实现?Router 上的技术如何随时间变化?
如果你的 network 需要一台 router,你可能会从 Cisco 或 Juniper 这样的主要设备 vendor 购买。为了确保 router 彼此兼容,所有主要设备 vendor 都按照一些预定义 standard 构建 router。
这种商业模式会让新方法的创新和实验变得困难。假设你有一个 routing protocol 的新想法。你需要让这个 protocol 得到标准组织批准,而这可能需要数年。然后,你还必须等待 vendor 升级制造流程,以符合新的 standard。
标准化也会让实现自定义方案的 user 感到 router 不够灵活。如果你有一个只属于自己 network 的问题,但其他人没有这个问题,你的方案很可能不会被标准组织采纳。Vendor 希望制造能满足所有人需求的 router;如果别人都不想要某个方案,即使它对你来说很完美,vendor 也未必会实现。
另一方面,标准化还意味着,如果其他人有一个你没有的问题,router 可能会附带解决他们问题的方案,即使你并不需要。这会让 router 对你的特定 network 来说变得不必要地复杂。
标准化也让实验和研究变得困难。如果你想尝试一个新想法,看看它是否有效,你可能买不到能够实现这个新想法的 router。Vendor 不想为一个特定 customer 构建实验性产品,因为它甚至可能无法工作。
创新和实验的另一个主要障碍是 router 的 vertically integrated(垂直集成)。你购买的 router 已经把三个 plane 的全部功能都连接到 chip 上。它没有模块化结构,无法只替换 control plane 本身。
创新 Router¶
如果确实想创新 router,我们能在每个 plane 上创新什么?我们会面对哪些既有 standard?
Data plane 由 IEEE(电气工程组织)标准化,并要求所有人严格遵守 standard。如果来自不同 vendor 的两个 router 相连,我们必须确保双方以相同且一致的格式沿物理线路发送 bit。
Data plane innovation 通常由更高 bandwidth router 的需求推动,而新 feature 并不常被引入。这类发展相当缓慢,通常以 2-3 年为周期,因为我们必须解决物理硬件问题,并为更高 bandwidth 设计 chip。由于核心 data plane feature 相对稳定,router innovation 并不真正聚焦于 data plane,因此较慢的发展周期是可以接受的。
Control plane 由 IETF(RFC 背后的网络组织)标准化。Vendor 有时会添加自己的 extension,不过核心 feature 大多是标准化的。例如,我们假设每台 router(即使来自不同 vendor)都遵循同一个 routing protocol。
Control plane innovation(例如新的 routing protocol)可能需要数年才能被采用。你可能必须提交 RFC draft proposal,然后 community 可能会花时间讨论这个 proposal,再同意它的条款。
Management plane 也由 IETF 标准化,不过它的标准化程度低得多。不同 operator 可以使用不同软件配置自己的 router,我们也不太需要不同 vendor 就某个标准化软件达成一致。由于这个 plane 只是松散标准化,因此存在许多具有不同 feature 的方法。
总结一下:data plane 是标准化的(但我们并没有真正想到新 feature),control plane 是标准化的(但我们想尝试新方案),management plane 则并不真正标准化。
激进想法:拆分 Router¶
标准化和垂直集成让创新和实验变得困难。这带来了一个激进想法:通过把各个 plane 拆成不同抽象层来 disaggregate router。我们不再购买一台包含三个 plane 的单体 router,而是可以分别购买 data plane 和 control plane 功能。这允许我们独立改变不同 layer。
为了连接这三层,我们需要在抽象层之间提供 API。在一个 vertically-coupled router 中,我们并不关心 data plane 和 control plane 如何彼此通信。不过,如果我们单独购买 data plane,并且想在其上设计自己的 custom control plane,就需要一个 interface 与 data plane 交互。
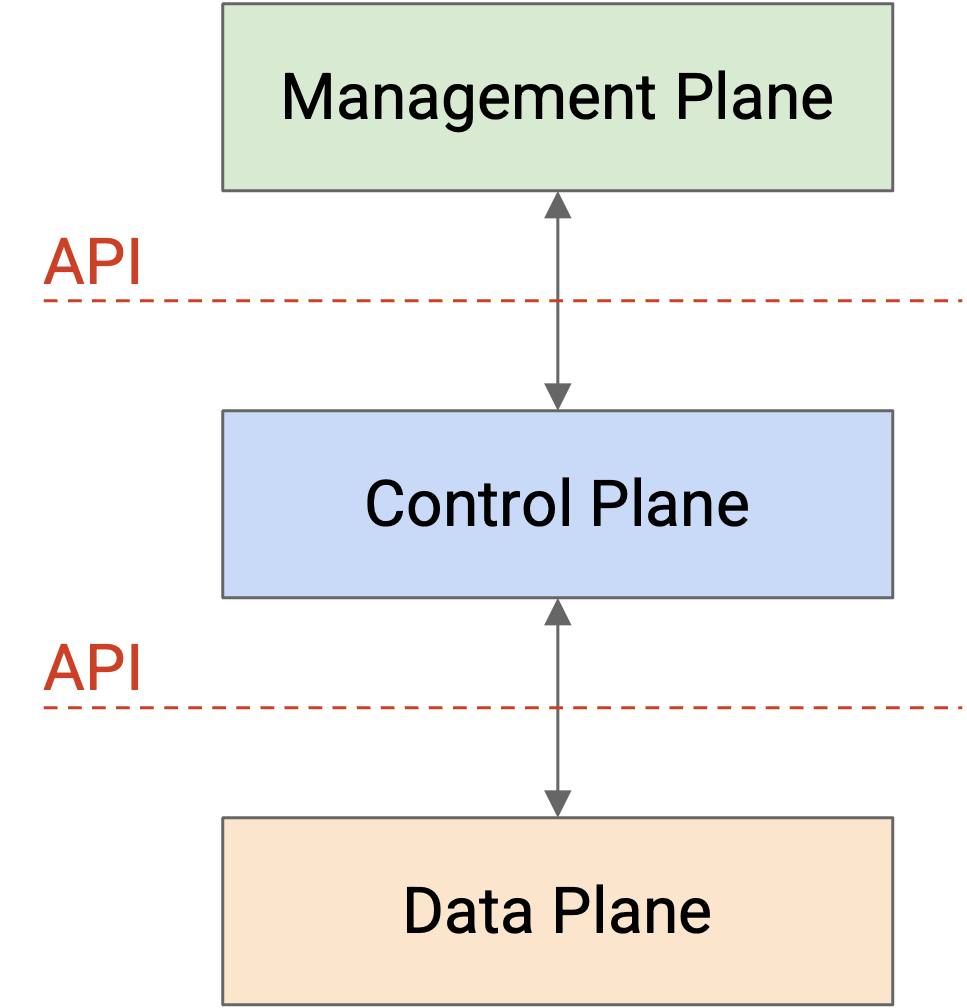
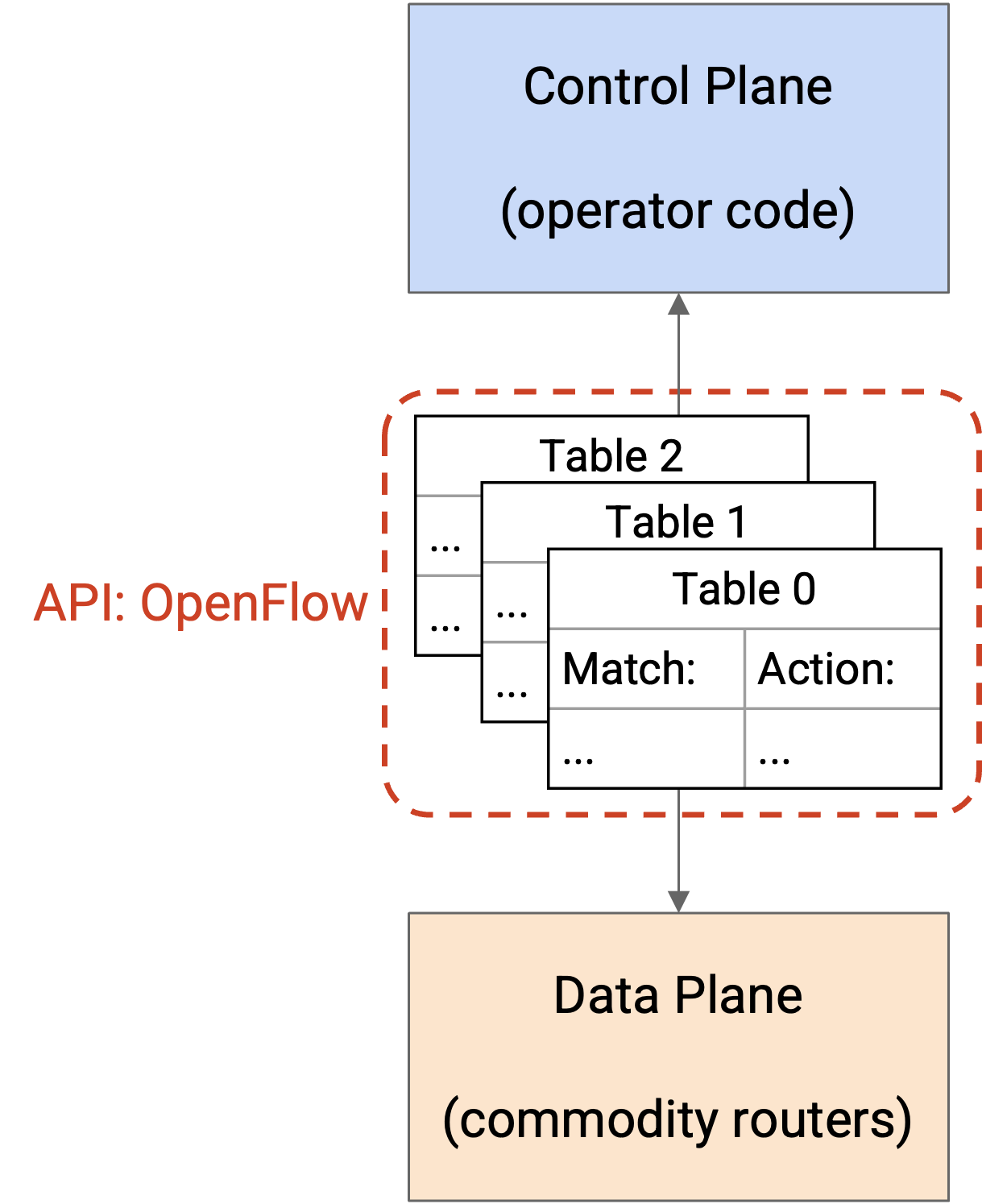
一个更激进的想法,是停止只从 router 本身的角度思考这三个 plane,而是设计一种新的 system architecture,自然地拆分 data plane 和 control plane。
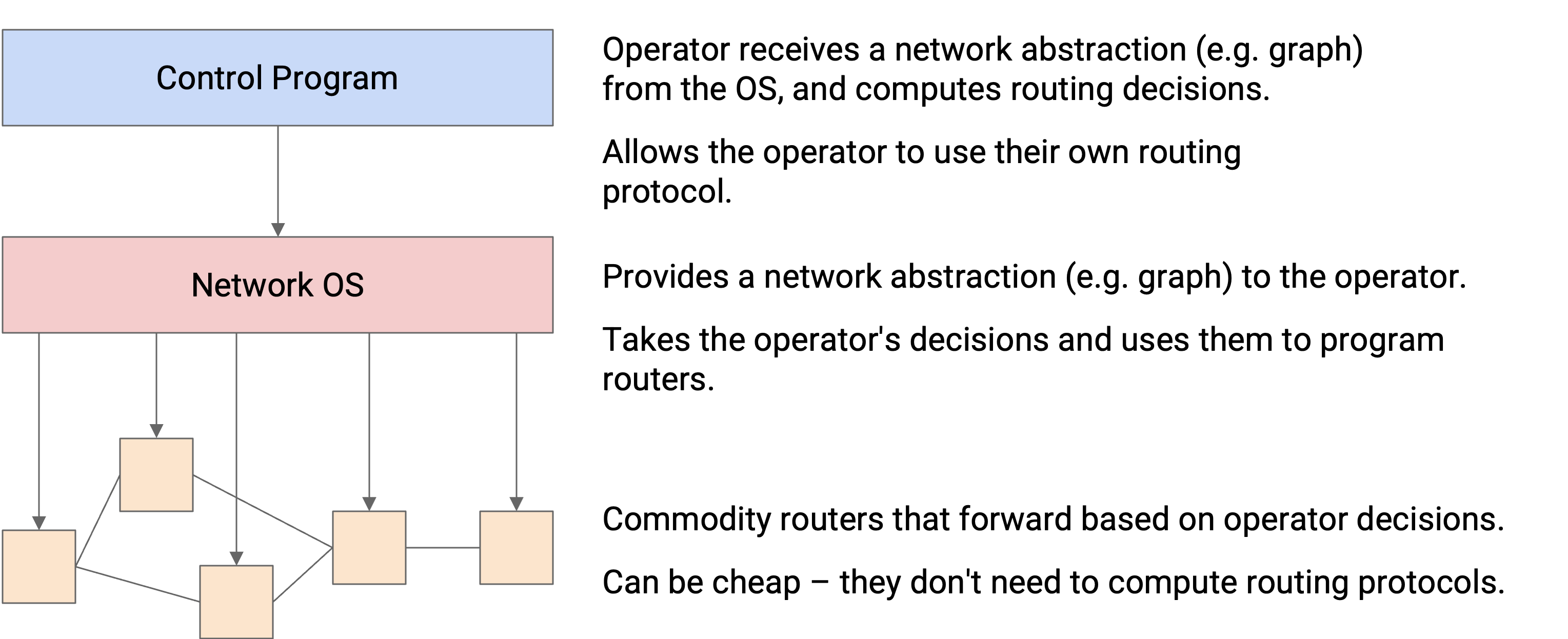
最底层是 commodity network device。你可以把它理解为只购买 data plane 本身。这些 router 通过 network OS 从 control program 接收 instruction,并简单地根据这些 instruction 转发 packet。这些 router 完全不需要思考 routing protocol,因此可以更便宜。
中间是 network OS。你可以把它理解为连接 data plane router 和 control plane program 的 API。Network OS 提供 router 的抽象(例如表示成 graph),并把这个抽象向上传递给 control program。然后,control program 可以向 network OS 发送 routing instruction,而不必担心如何为具体 router 编程。Network OS 可以把这些 instruction 转换并安装到单个 router 上。
最上层是 control program。你可以把它理解为单独购买或实现 control plane。在这里,operator 从 network OS 接收 network 的抽象(例如 graph),并用它编写自己的 custom routing protocol。然后,得到的 route 可以传给 network OS,由 network OS 把它们安装到 router 上。
OpenFlow API 格式¶
OpenFlow 是一个用于与 router 的 data plane 交互的 API。Operator 编写自己的复杂代码,这些代码与 router 分离,用来计算穿过 network 的 route。然后,这些 route 可以被编程到 forwarding chip 上。
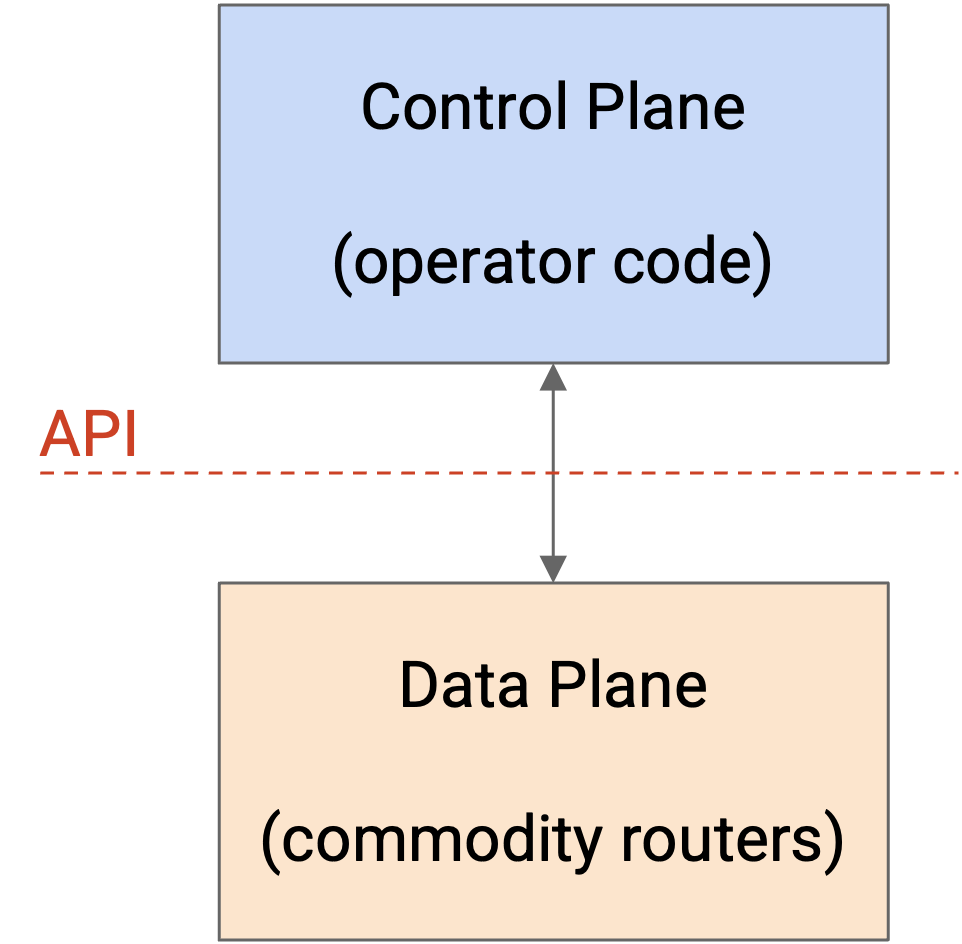
OpenFlow 范式不同于传统 router。传统 router 的 control plane 在 router 内部实现,并且没有一个清晰 API 可以把 custom route 编程到 forwarding chip 上。
OpenFlow API 定义了一个 flow table 抽象,用来描述 route 和 forwarding rule。Operator code 可以输出任意想要的 rule 和 route,并把它们安装到 router 上,只要它们符合 flow table 格式。
这个 API 的基本构件是 flow table,你可以把它看作 forwarding table 的泛化版本。每个 flow table 都由 key-value pair 组成,就像 forwarding table 一样。Key 指定 packet 要与什么内容 match。这可以是 destination prefix、精确 destination、5-tuple,或其他相对简单的 match。对应的 value 指定 packet match 时要设置什么 action。Action 可以是把 packet 发送到 next hop(类似 forwarding table),也可以指定更复杂的 action,例如添加额外 header。
输出格式是一个或多个编号 flow table 的序列,其中每个 table 都有自己不同的 match-action entry。然后,这些 flow table 可以被编程到 forwarding chip 上。

当 packet 到达 router 时,它会按顺序与每个 table 检查(例如 Table 0、Table 1、Table 2 等);一旦 match,我们就记下对应 action(但还不执行)。最终,当 packet 与最后一个 table 检查完之后,我们记下的所有 action 才会应用到 packet 上。
还有一些特殊 action 可以跳到后面的 table,我们可以在这样的 rule 中使用:如果 source port match 这个数字,就跳到 table 5 设置额外 action。
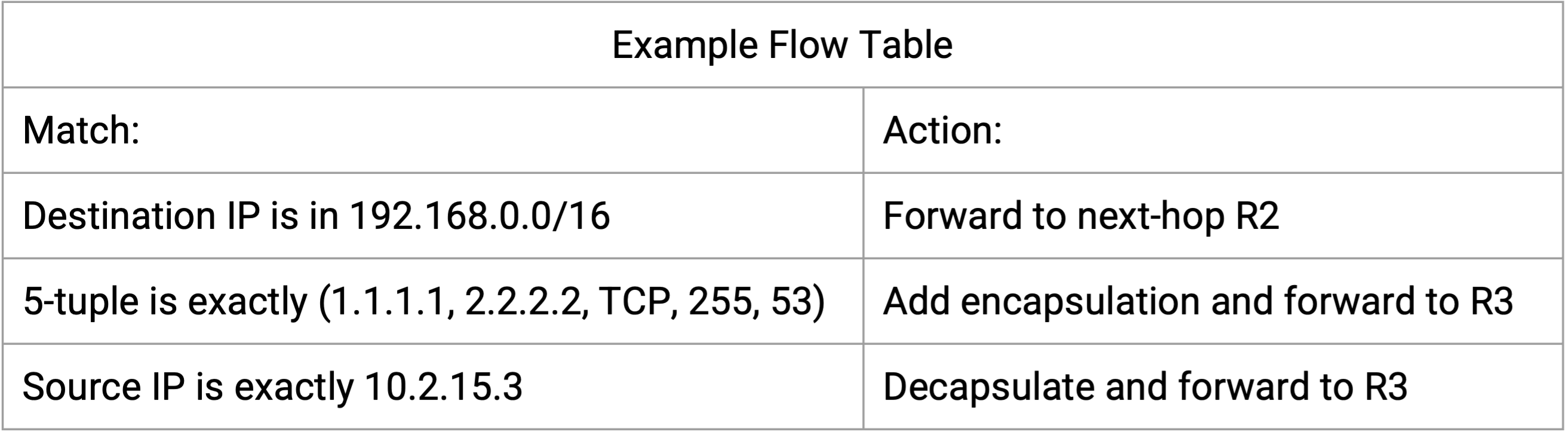
Operator 可以运行任意代码来生成 flow table,而 flow table 可以比 destination/next-hop forwarding table 更通用。不过,我们生成的 rule(match/action pair)仍然受专用 forwarding chip hardware 约束。Forwarding chip 为速度优化,可能无法处理复杂 match rule,例如“如果 TCP payload 是英文,就设置这个 action”。
因此,实践中我们看到的 flow table 最终看起来与已经见过的 table 很相似。常见 match rule 包括对 IP destination 做 longest prefix matching、用 5-tuple 标识 flow,以及对 encapsulation header(例如 MPLS)做 exact match。
如果 forwarding rule 没有那么不同,为什么还要使用 OpenFlow?记住,主要优势是它给 operator 在 control plane 上完全的自由。我们不再局限于 distance-vector 或 link-state protocol。
灵活 Control Plane 的好处¶
我们的新 architecture 让 operator 可以灵活地在 control plane 实现自己的新 routing protocol。这种方法有什么好处?
Operator 可以实现最适合自身特定需求的 custom routing protocol。Operator 不再受标准组织和 vendor 约束。
灵活性也给了我们简化的机会。例如,如果标准化 protocol 包含我们不需要的 feature,我们就不必在自己的 custom solution 中实现它们。更简单的 protocol 可以有更少代码和更简单代码,这可能让 protocol 更容易开发和维护。
最后,灵活的 control plane 允许在 control program 中集中计算 route,而不是分布在多个 router 上。Centralization 也带来几个好处。
Centralization 可以产生更智能的 routing decision,从而带来出色性能。在 2013 年一份来自 Google 的报告中,部署 SDN architecture 的工程师指出,“centralized traffic engineering service drives links to near 100% utilization, while splitting application flows among multiple paths to balance capacity against application priority/demands.” Microsoft 2013 年的一篇 paper 描述了使用 OpenFlow controller 来 “achieve high utilization with software-driven WAN.”
更智能的 routing decision 可以帮助优化除性能之外的其他标准,而标准 routing protocol 很难优化这些标准。例如,美国政府网络可能实现一条 geofencing rule:不要通过位于 Canada 的 link 发送 traffic。又如,广播电视网络可能希望优化 path diversity 来提高 reliability。我们可以强制两个 flow 走不共享任何 link 的 path,这样如果某条 link down,只有其中一个 flow 受影响。两条 path 可以互为 backup。
Centralization 还可以让 routing protocol 更容易 convergence。在 distributed protocol 中,如果 network 发生变化,router 必须协同并 convergence 到新的 routing state。在这个集中式模型中,如果一条 link failure,那个 router 可以告诉 boss,boss 可以重新计算 route,并把新 route 安装到 router 上。
Traffic Engineering¶
灵活的 control plane 允许我们执行 traffic engineering,也就是用比标准 distributed routing protocol 更智能、更高效的方式 route traffic。
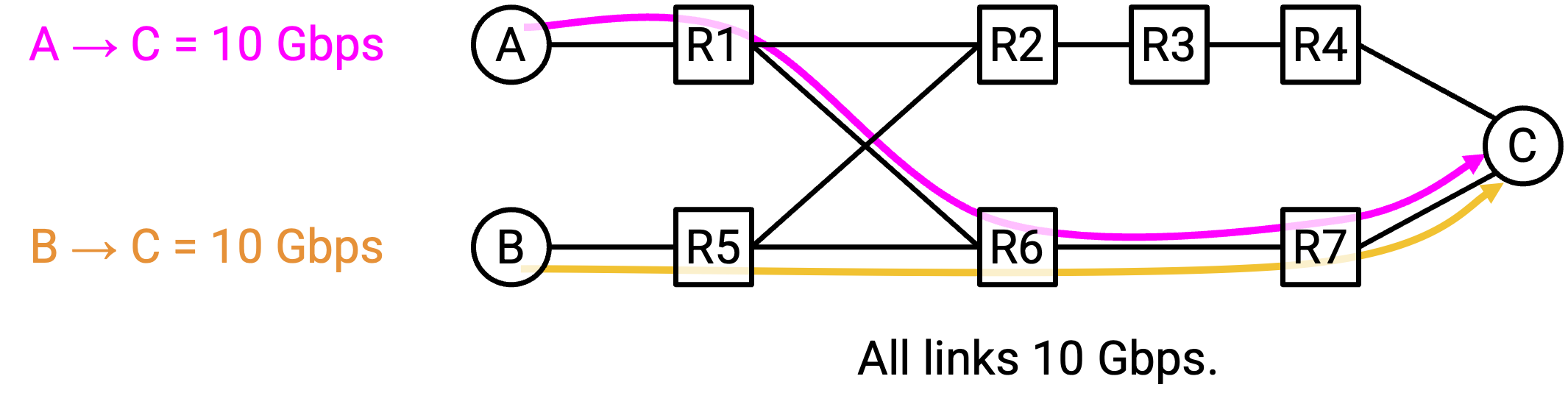
假设有两个 connection,S1-D 为 10 Gbps,S2-D 为 10 Gbps。如果只运行标准 least-cost routing,两个 flow 都会沿底部 path 发送 traffic。底部 path 会发生 congestion(在 10 Gbps link 上承载 20 Gbps),而顶部 path 的 bandwidth 却闲置。
使用更智能的 routing scheme,我们可以让 S1-D traffic 走顶部 path,让 S2-D traffic 走底部 path。通过 traffic engineering,我们强制一些 packet 走更长 route,以便更好利用 network 中的 bandwidth。
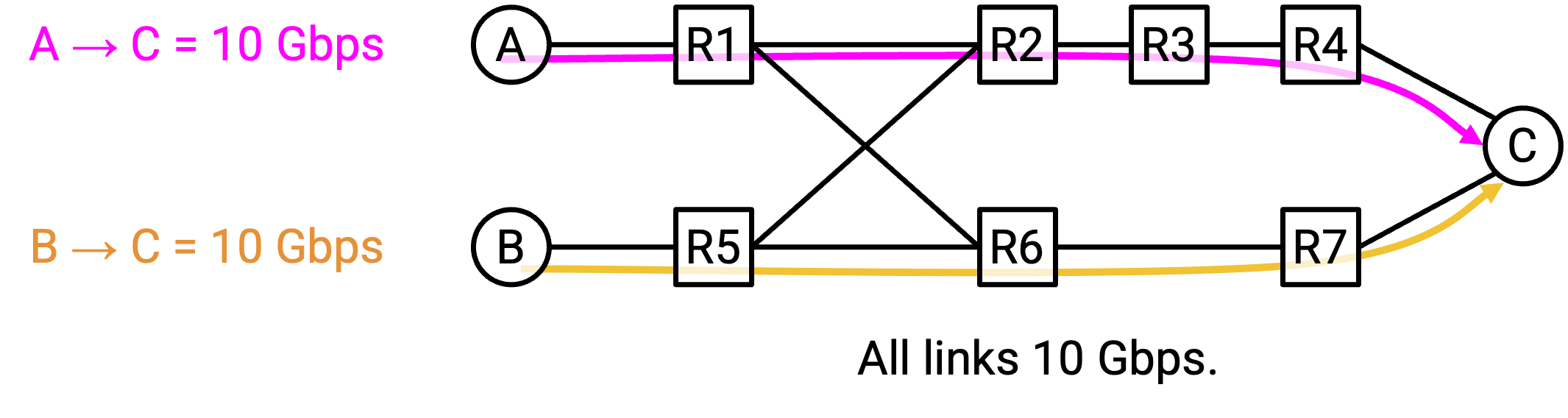
为了计算这些 route,我们可以修改 least-cost routing,改为强制 traffic 走具有足够 capacity 的 shortest path。我们也可以强制其他 constraint,而不是 capacity,例如 latency。得到的 algorithm 称为 constrained Shortest Path First(cSPF)。
现在,假设 S1-D 需要 12 Gbps,而 S2-D 需要 8 Gbps。cSPF 会让这些 flow 走不同 path 来最大化 bandwidth,但 S1-D 正在通过一条 10 Gbps link 发送 12 Gbps。
为了解决这个问题,我们的 traffic engineering 可以更智能,把一个 flow 中的 traffic 分到不同 path 上。S1-D 可以把 10 Gbps traffic 沿顶部 path 发送,剩下 2 Gbps 沿底部 path 发送。
同样,我们的 traffic engineering 让我们实现 custom logic,从而更好地利用 network capacity。
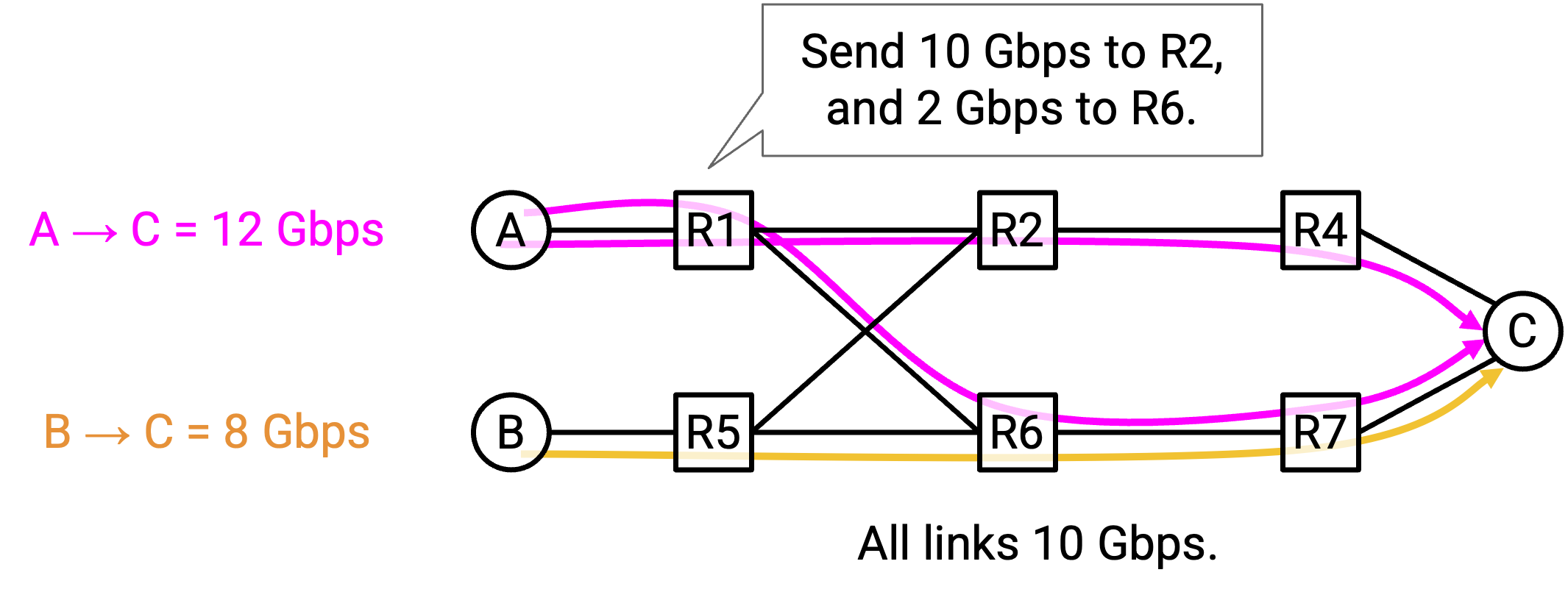
我们如何使用前面的 OpenFlow API,在 network 中实际实现 split path?记住,我们的 routing decision 仍然应该遵循 forwarding table 能理解的简单 rule。
一种方法是使用 encapsulation。在 sender 处,我们可以添加 rule 来加入额外 header,其中一些 packet 获得 label 0,其余获得 label 1。这个 label 告诉我们应该沿哪条 path 发送 traffic。
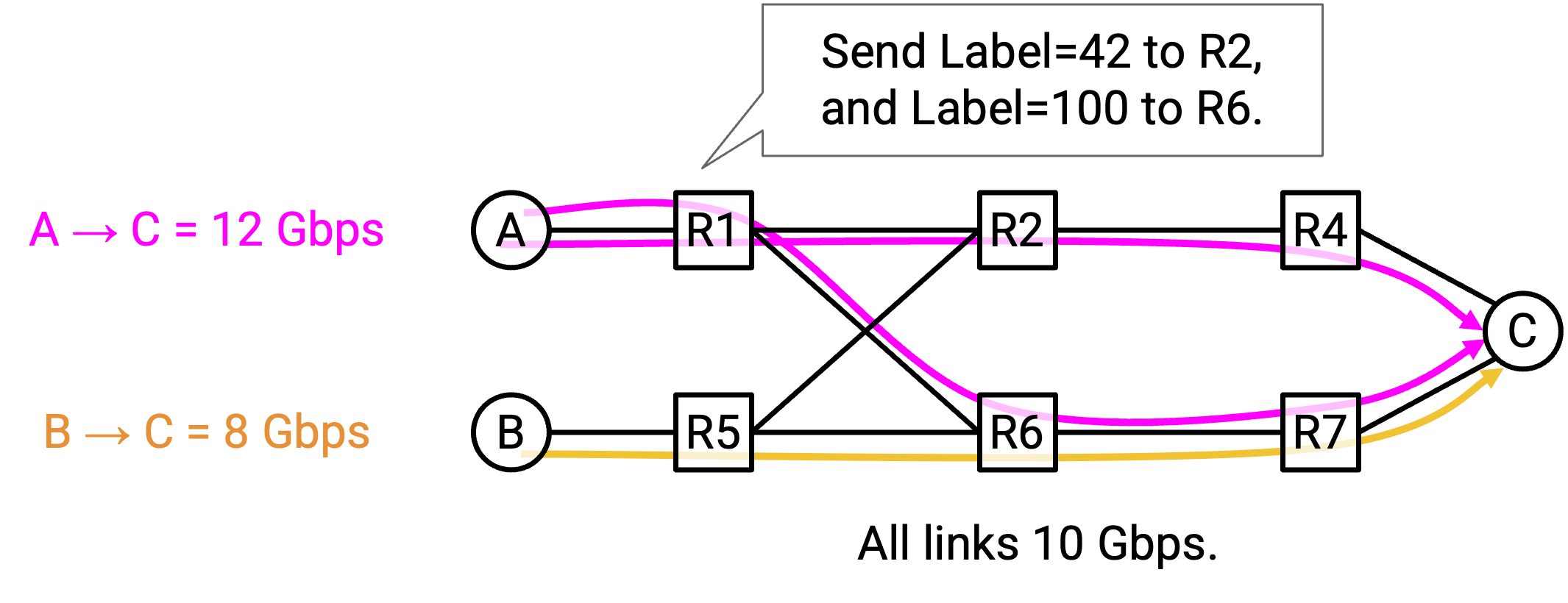
现在,在 R1 处,我们可以添加简单 rule,把 label 0 packet 向上 route 到 R2,把 label 1 packet 向下 route 到 R3。这个想法可以和 constrained least-cost routing 的其他 rule 一起使用(例如 flow table 可能还有其他 destination 或其他 flow 的 entry)。
Centralized Traffic Engineering 和全局最优决策¶
在 custom routing protocol 的 SDN 模型中,一个主要区别是 centralization。在原始模型中,每个 router 都运行自己的 routing protocol。现在,我们可以让 router 外部的一台单独 computer 计算所有 route,然后使用 flow table API 把这些 route 安装到 router 上。
Centralization 允许我们做出 globally optimal decisions(全局最优决策)。在 distributed protocol 中,每个 router 都在为自己做最佳决策,但这可能不是对其他 router 的最佳决策。在 centralized model 中,boss 可以利用自己对 network 的全局视图,决定什么对所有人最好,并告诉 router 遵循这个决策。
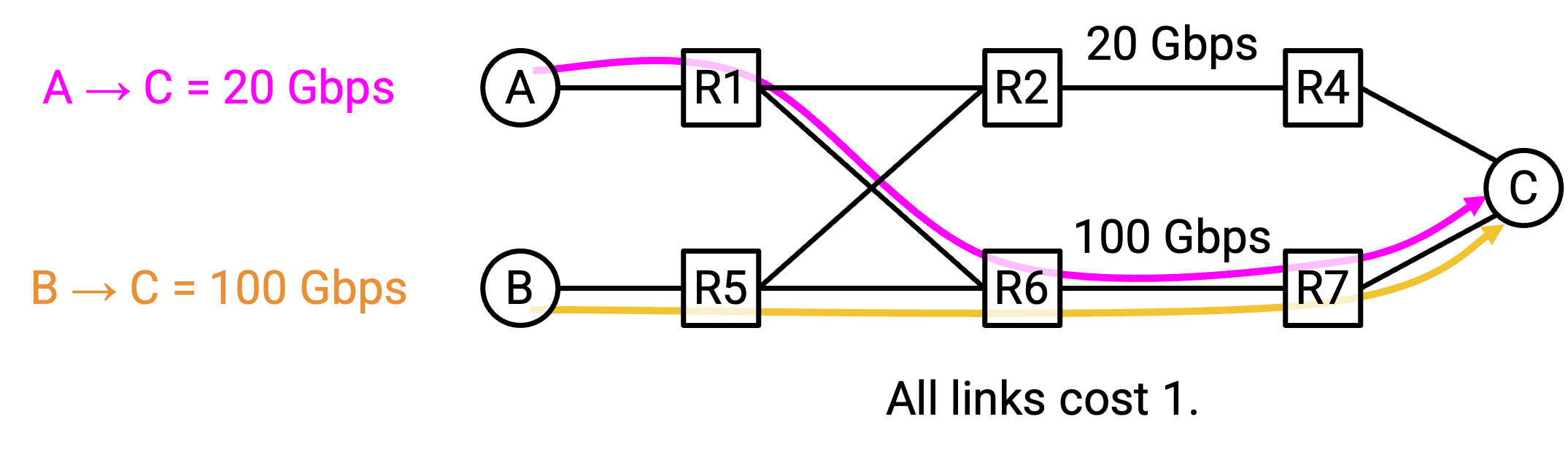
考虑这个 network,其中有两个 flow:S1-D 为 20 Gbps,S2-D 为 100 Gbps。假设我们还没有实现把一个 flow 分到多条 path 上的支持。
假设 20 Gbps 的 S1-D flow 先开始。使用 constrained shortest path first,S1 可以选择使用底部 path。从 S1 的视角看,这是一个 locally optimal decision(顶部和底部 path 同样好)。
稍后,100 Gbps 的 S2-D flow 开始。现在,使用 constrained shortest path first,S2-D 没有任何一条单独 path 能满足需求。顶部 path(20 Gbps)和底部 path(80 Gbps)的 capacity 都不足。
这里的核心问题是,每个单独 router 都独立做出了自己的决策,没有协调。
通过引入 centralized controller,controller 可以查看整体 network structure 和每个 flow 的 demand,并更智能地为每个 flow 分配 path。最终决策是 globally optimal 的,并提高了 network efficiency。
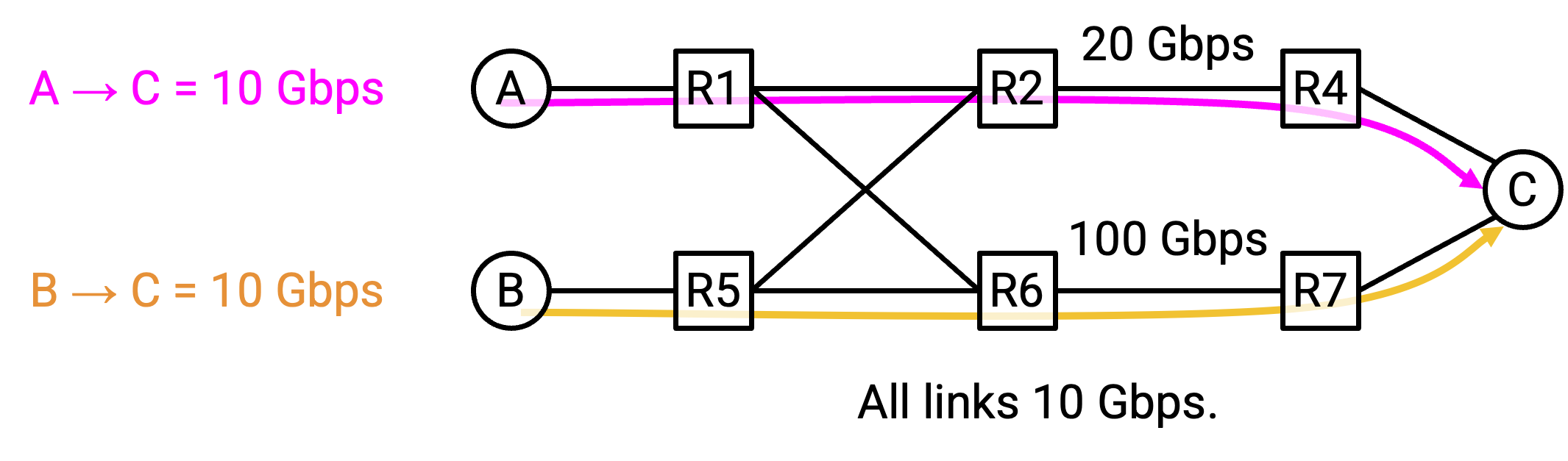
Centralized traffic engineering 可以根据 operator 想优化的目标做出更智能的 routing decision。例如,我们可以把 flow 分类为 high-priority 或 low-priority,并做出同时优化 network utilization 和不同 application 需求的决策。
Datacenter Overlay 中的 SDN¶
在上一节中,我们看到 virtual switch 可以应用 encapsulation 来连接 overlay 和 underlay network。给定一个 virtual address,我们可以添加一个带有对应 physical address 的 header,让 packet 沿 underlay network 发送。但是,我们如何知道 virtual address 和 physical address 之间的 mapping?
我们还看到,encapsulation 可以用来支持单个 datacenter 中的多个 tenant,每个 tenant 运行自己的 private network。Switch 可以添加带有 virtual network ID 的 header。但是,我们如何知道应该使用哪个 virtual network ID?
Centralized SDN controller 可以在 datacenter 中用来解决这些问题。每个 tenant 可以运行自己的 controller。当新 VM 被创建时,SDN 会得知它的 virtual address 和 physical address。然后,SDN 可以更新其他 virtual switch 中的 forwarding table,添加带有新的 virtual/physical address mapping 的 encapsulation rule。
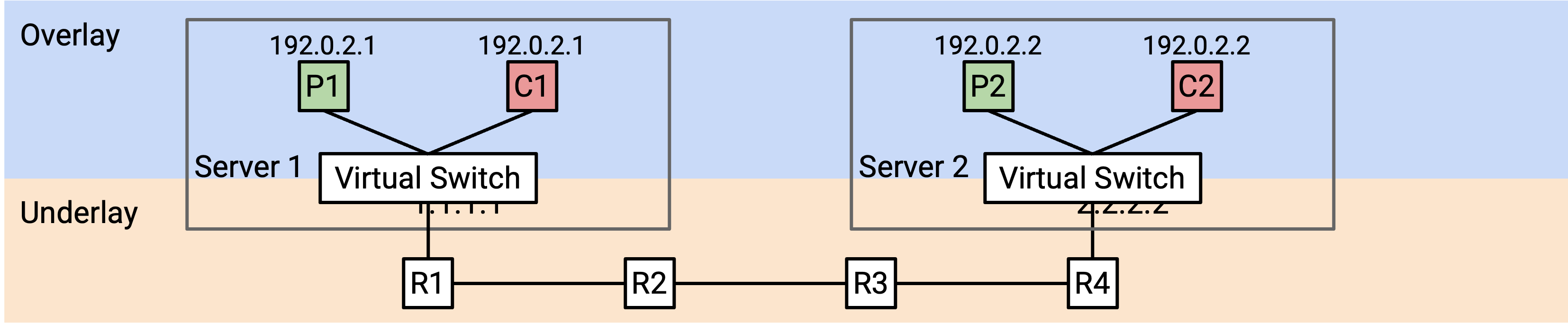
例如,假设 Coke VM 2 被创建,virtual IP 是 192.0.2.1,physical IP 是 2.2.2.2。SDN 知道 Coke VM 1 位于 physical server 1.1.1.1 上,因此它可以访问 1.1.1.1 上的 virtual switch,并为新的 Coke VM 2 添加一条 encapsulation rule。
1.1.1.1 上的 flow table 可能会说:如果收到 destination 为 192.0.2.1 的 packet,就添加一个 header,其中包含 Coke 的 virtual network ID 42。另外,添加一个 header,其中包含对应 physical address 2.2.2.2。然后,沿 underlay network 发送这个 packet。
Datacenter Overlay 中 SDN 的好处¶
为什么我们可能会使用 centralized SDN architecture 来支持 datacenter 中的 virtualization 和 multi-tenancy,而不是使用更标准的 routing protocol?
Centralized SDN architecture 允许我们把 overlay 和 underlay network 干净地拆成两个可扩展 layer。在传统 architecture 中,underlay network 中的 router 必须处理 custom encapsulation header(例如 virtual network ID)。SDN 允许 underlay network 保持简单,不必思考 virtualization 或 multi-tenancy。
Centralization 给了我们一种简单方法,在 end host 上实现 control plane,而不需要复杂的 routing protocol。Controller 得知一个新 host,并相应更新其他 host。没有 centralized controller 时,我们可能需要某种复杂的 distributed scheme 来确定应该添加哪些 encapsulation header。
这种 SDN architecture 还说明了为什么 overlay network 可以很好地扩展。某个 tenant 的 SDN controller 只需要知道属于这个特定 tenant 的 VM。相比之下,如果使用传统 architecture,一个新的 Coke VM 可能必须被 advertisement 给所有其他 VM,甚至包括 Pepsi VM。
Datacenter Underlay 中的 SDN¶
Datacenter underlay 是一个物理 network,就像其他任何 network 一样,只是具有特殊 topology。许多通用 network challenge(例如实现高 link utilization)也适用于 datacenter underlay network。这意味着我们也可以把 SDN 应用到 underlay network。
Underlay network 中的 SDN 可以帮助我们高效地 route packet 穿过 datacenter。例如,operator 可能希望把 mice flow 发送到 delay 较小的 link 上,把 elephant flow 发送到 bandwidth 较高的 link 上。
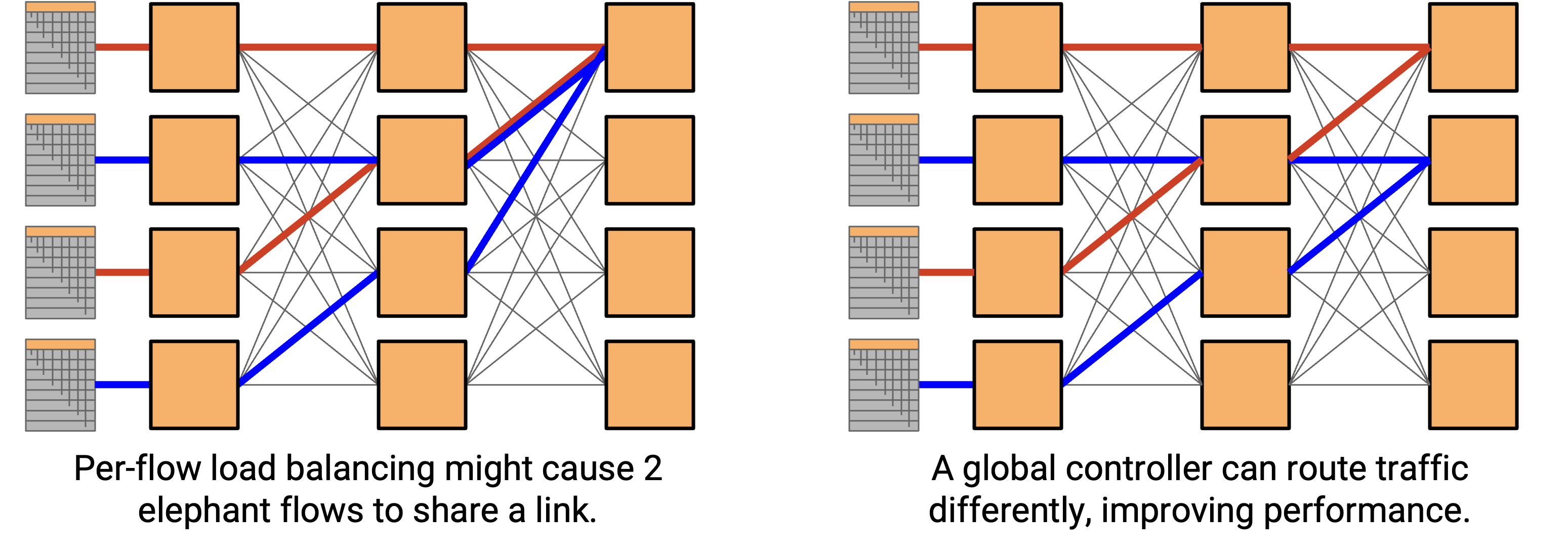
在我们的 underlay Clos network 中,per-flow load balancing(hash 5-tuple 来选择 path)仍然可能把多个 elephant flow 发送到同一条 path 上。即使两个 elephant flow 使用了不同 path,这些 path 也可能共享 link,而这些 link 可能变得 congested。SDN controller 可以通过协调 flow 并把它们放到不重叠的 path 上来解决这个问题。
这篇 2022 年 Google paper 描述了如何使用 SDN 更智能地 route traffic,从而消除 Clos network 中的一些 layer(更少 link、更便宜的 datacenter)。
Hyperscale datacenter 通常在 overlay 和 underlay network 中都使用 SDN。它们通常实现为解耦的 system。一个 SDN 负责思考 underlay,另一个独立 SDN 负责思考 overlay。
Wide Area Network 中的 SDN¶
除了 datacenter,SDN 在通用 wide-area network 中也很有用,特别是在高效利用 bandwidth 至关重要时。例如,在前面的 traffic engineering 例子中,想象一下,如果我们的 10 Gbps link 是海底光缆。增加额外 bandwidth 并不便宜,因此优化必须转向高效利用已有 bandwidth。
Centralized Control 的缺点¶
Centralization 并不是免费的,它有一些缺点。
一个缺点是 reliability。在传统 network 中,如果一个 router failure,routing protocol 会围绕 failure convergence。其他 router 可以沿其他 path reroute traffic。相比之下,如果 central controller failure,我们就没有办法再更新 network,router 也不知道如何适应变化。
注意:我们把 centralized controller 画成单个实体,但它不需要运行在单台 server 上。Control plane computation 可以跨多台 server 发生,这些 server 彼此协调,以逻辑集中方式运行。这不同于原始模型,在原始模型中,router 彼此协调,但仍然做自己的 distributed decision。这有助于避免硬件上的单点故障,不过 controller 作为逻辑单元仍然可能 failure(例如代码中的 bug)。
Centralization 还会引入 scalability problem。Controller 必须为所有人做决策,对于大型 network 来说,这可能很昂贵。相比之下,在传统 network 中,每个 router 只需要为自己执行计算。
Centralization 还可能引入不同类型的 complexity。在传统 network 中,我们可以买一台 router 并连接上,它或多或少会立刻开始工作。有了 central controller,我们会有额外的基础设施挑战。这个 controller 应该放在哪里?如何以可靠方式把它连接到单个 router?
这是一个活跃的研究领域,其中包括 Sylvia Ratnasamy 和 Rob Shakir(Berkeley CS 168 讲师)的一个项目。
Management Plane 和 Data Plane 中的 SDN¶
我们已经看到,SDN 是实现 control plane 的一种新方式。但是,最初导致 SDN 发展的挫败感来自 management plane。
事实证明,SDN 在 control plane 使用的许多设计范式,也可以应用到 management plane。例如,我们看到 SDN 依赖定义良好的、程序化的 API(例如 OpenFlow)。
TODO:SP24 时间不够,未完成。