HTTP¶
HTTP 简史¶
1989 年,Tim Berners-Lee 在 CERN(瑞士研究实验室)工作,需要在科学家之间交换信息。当时已经有 FTP 这样的 protocol 用于通过 Internet 传输文件。然而,一个文件经常会链接到 Internet 上的其他资源。他的目标是创建一种 protocol 和文件格式,允许页面彼此链接,并获取这些页面。
最初的 HTTP specification 被赋予版本号 HTTP/0.9,并于 1991 年发布。HTTP/1.0 于 1996 年标准化,HTTP/1.1 于 1997 年标准化。除非另有说明,本节讨论的是 HTTP/1.1,因为这是今天最常用的版本。更新的版本确实存在(见本节末尾),但这个 protocol 的基本思想已经保持了 20 多年不变。
HTTP 基础¶
HTTP 运行在 TCP 之上。两个想通过 HTTP 发送数据的人会先启动一个 TCP connection。然后,他们可以使用 TCP 的 bytestream 抽象,可靠地交换任意长度的数据。运行 HTTP 的 host 不必担心 packet 被重排序、丢弃等问题。

HTTP 是一个 client-server protocol。我们把一方指定为 client(例如你,end user),另一方指定为 server(例如 Google、银行网站等)。client 几乎总是在 web browser(例如 Firefox 或 Chrome)中运行 HTTP,不过 HTTP 也可以用其他方式运行(例如直接在终端中运行)。
建立 HTTP connection 时,server 必须在 well-known 且固定的 port number 80 上监听 connection request。(HTTPS 是更新的安全版本,使用 port 443。)client 可以选择任意随机 ephemeral port number 来启动 connection,而 server 可以把 reply 发送到这个 port number。
HTTP 是一个 request-response protocol。client 发送的每个 request,server 都会发送且只发送一个对应的 response。
HTTP Request¶
HTTP request message 使用人类可读的 plaintext 格式,这意味着你可以在终端中输入原始 HTTP request。request 包含三部分:method、URL、version,以及可选的 content。
message 以换行结束(严格来说是 CRLF,如果好奇可以查一下),你可以把它理解成用户在终端中输入 HTTP request 后按下 Enter 键。
version number 指定你正在使用的 HTTP 版本,例如 HTTP/0.9、HTTP/1.0、HTTP/1.1 等。
请求的 URL 标识 server 上的一个 resource。你可以把 URL 理解为你试图从 remote server 取回的内容的 filepath。例如,在 URL http://cs168.io/assets/lectures/lecture1.pdf 中,我们试图从 remote server cs168.io 上的 assets/lectures folder 中取回名为 lecture1.pdf 的文件。(server 并不必须这样工作,但这是一个有用的直觉。)
method 标识用户想执行什么 action。最初,HTTP 只有一种 method:GET,它允许 client 从 server 获取某个特定页面(由 URL 指示)。
后来,HTTP 被扩展并加入了其他 method。尤其是 POST method,它允许 client 同时向 server 提供信息。例如,如果用户填写表单并点击 Submit,这些数据会在 POST request 中发送给 server。
还有一些较少使用的 method。HEAD 获取 response 的 header(metadata),但不获取 response 的实际 content。PUT、CONNECT、DELETE、OPTIONS、PATCH 和 TRACE 等其他 method 把 HTTP 扩展成一个允许用户与 server 上的 content 交互的 protocol。用户现在可以修改 content,而不只是像原始设计那样只能获取 content。这些额外 method 让 HTTP 对各种不同 application 都非常灵活。
注意,使用 POST 这样的其他 method 时,我们仍然必须提供 URL,来指示如何解释我们发送的数据。在银行网站上,把一个 name 发送到 /send-money URL,可能和把同一个 name 发送到 /request-money URL 做完全不同的事情。
对于 GET request,request 的 content 通常为空,因为我们是在向 server 请求页面,而不是发送自己的信息。相比之下,对于 POST request,request 的 content 包含我们想发送给 server 的数据。
HTTP Response¶
每个 HTTP request 都对应一个 HTTP response。response 同样是人类可读的 plaintext,这意味着你可以在终端中读取原始 HTTP response。response 包含四部分:version、status code、可选 message,以及 content。
和之前一样,version 指定正在使用的 HTTP 版本。
content 是 server 放置内容的地方,例如用户在 GET request 中请求的页面。
status code 是一个数字,允许 server 指明 client request 的结果。每个 status code 都有对应的人类可读 message。
status code 按数值分为不同类别:
100 = Informational responses。
200 = Successful responses。200 OK 表示 request 成功,其中成功的定义取决于 request 的 method 以及使用 HTTP 的 application(记住,无论 request 使用什么 method,GET/POST 等,每个 response 中都有 status code)。201 Created 表示 request 成功,并创建了某个新 resource。这通常见于 POST 或 PUT request。
300 = Redirection messages。这些 message 允许 server 告诉 client,它应该去其他地方寻找这个 resource(由 URL 指定)。两个常见例子是 301 Moved Permanently 和 302 Found(这是 temporarily moved 的一个奇怪名字)。有时 status code 本身不能提供足够上下文(这些 redirect 就是例子)。因此,response 还会包含 resource 移动到哪里的额外信息(例如另一个 URL)。
使用更具体的 status code 允许 client 根据 code 决定未来行为。例如,301 Moved Permanently 告诉 client 不要再去原位置寻找,而 302 Found(temporarily moved)可能告诉 client 稍后再回来检查。
400 = 可归因于 client action 的 error。401 Unauthorized 表示 client 不允许访问这个 content,但如果它验证自己的身份(例如 log in),就可能能够访问这个 content。403 Forbidden 表示 client 已经 authenticated,server 知道它的身份,但它仍然不允许访问这个 content。
同样,使用更具体的 code 让 client 能决定未来行为。401 Unauthorized 可能使 client browser 显示 login window,而 403 Forbidden 可能使 client browser 显示 error message(因为用户已经登录)。
500 = 可归因于 server action 的 error。500 Internal Server Error 和 503 Service Unavailable 很常见。client 对这些 error 没有什么能做的,最多也许只能稍后再试。
一些 error code,比如 404(File Not Found)和 503(Service Unavailable),非常容易识别。
有时,应该使用哪个 status code 可能有歧义。例如,如果我们用 version 0.9 向 Google 发送 HTTP request,合适的 response 可能是 505(HTTP Version Not Supported)。但 Google 实际回复 400(Bad Request)。通常,目标是提供正确类别的 error(例如 400 和 500 表示 error),并让 client 产生正确行为。
HTTP Header¶
如果 client 有额外信息想发送给 server,可以包含称为 header 的额外 metadata。在 HTTP/1.1 中,没有任何 header 是 mandatory 的,因此不包含任何 header 是合法的(尽管 server/client 可能期待某个 header,并因此报错)。
例如,Location header 可以在 HTTP 300 response 中使用,用来指明 resource 已经移动到哪里。
有时,header information 是可选的。例如,request 中的 User-Agent header 让 client 告诉 server 关于 client browser 或程序的信息(例如 Firefox 或 Chrome)。这可以允许 request 根据 header field 被不同处理(例如用户是在 Chrome 上还是在终端中)。
另一些时候,header information 更关键。例如,Content-Type 告诉我们 payload 是 HTML page、image、video 等。这告诉 browser 如何显示 HTTP response。如果一台 server 托管多个 website,request 中的 Host header 可以用来指定请求哪个 website。
有些 header 与 request 相关。它们允许 client 把信息传给 server。例如,Accept header 让 client 告诉 server,client 期望哪种 content type(例如面向人类可读页面的 HTML,或面向机器解析数据的 JSON)。User-Agent header 表示正在使用的 client 类型,Host header 表示正在访问的具体 host(用于一台 server 托管多个 website 的情况)。Referer header 表示 client 是如何发起 request 的(例如是否点击了 Facebook 上的链接来发起这个 request)。
其他 header 与 response 相关。记住,header 是关于 content 的 metadata,而不是 content 本身。例如,Content-Encoding 告诉我们 response 的 bit 应该如何解释(例如人类可读文本的 Unicode/ASCII,或压缩文件的 gzip)。Date header 告诉我们 server 何时生成 response。
有些 header 是 representation header,在 request 和 response 中都会使用,用来描述 content 是如何表示的。例如,Content-Type header 指定 document 的类型(例如 text、image),可以出现在 POST request 或 GET response 中。Representation header 让我们能通过 HTTP 携带不同类型的 content,这使得 protocol 可以泛化,并被各种 application 使用。
HTTP 示例¶
在终端中,你可以输入 telnet google.com 80 来连接 Google server 上的 Port 80(HTTP)。终端随后允许你输入带有 header 的原始 HTTP request,例如:
GET / HTTP/1.1
User-Agent: robjs
这是一个请求 server root page 的 GET request,运行在 HTTP version 1.1 上。User-Agent header 表明我们正在使用哪种 client。
类似地,response 也是人类可读的。
HTTP/1.1 200 OK
Date: Sat, 16 Mar 2024 18:33:08 GMT
Content-Type: text/html; charset=ISO-8859-1
<!doctype html><html lang="en"><head><meta content="Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for." name="description">...
HTTP/1.1 200 OK 告诉我们 version,以及 status code(200)和对应 message(OK)。这里附带了两个 header:response 的日期和 content type。然后,content 包含网页的原始 HTML。如果我们在 web browser 中打开这个 HTML,它会看起来像一个真实网页。
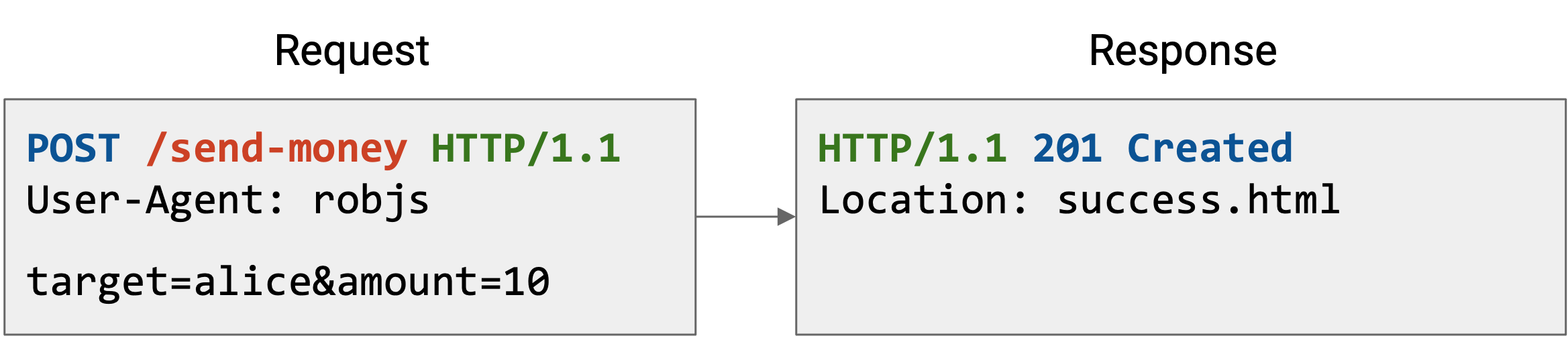
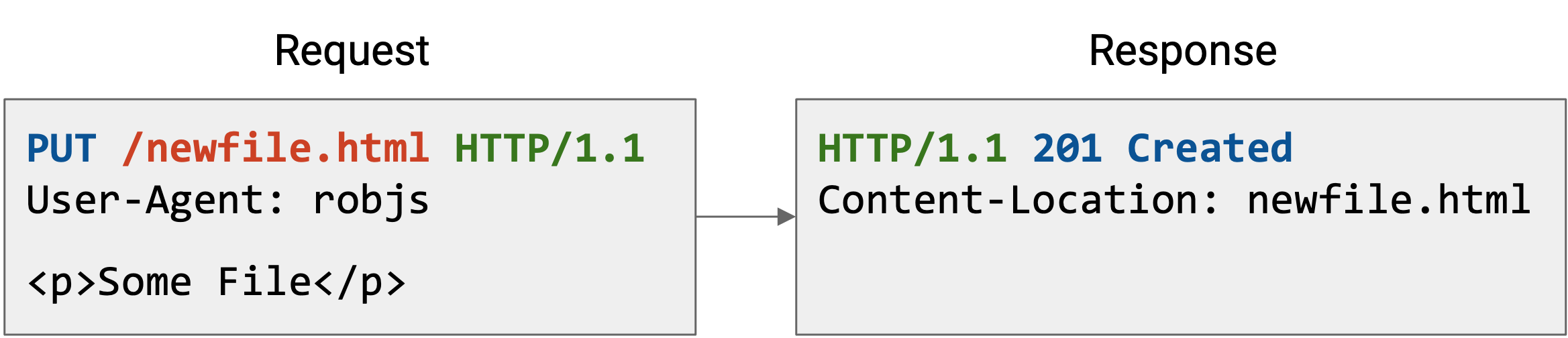
这里还有一些其他例子。注意,在 GET request 中 content section 为空,但在 POST 和 PUT request 中包含数据。反过来,POST 和 PUT response 没有 content,而 GET response 有。
status code 和 header 告诉我们关于 request 的有用 metadata。例如,status 201 Created 告诉我们发送的文件已经成功存储在 server 上。header 告诉我们这个文件存储在 server 的哪个位置(之后我们可能会用这个位置取回文件)。
用 Pipelining 加速 HTTP¶
在 web browser 中加载单个页面可能需要多个 HTTP request。当你请求一个 YouTube video 时,browser 必须分别请求 video 本身、包含网页其他文字的 HTML(例如 video title、comments)、相关 video 的 thumbnail 等等。这些 request 中许多可能会发往同一台 server(例如这里的 YouTube server)。
回忆一下,HTTP 运行在 TCP 之上。在朴素情况下,每个单独 request 都需要通过 3-way handshake 启动一个新的 TCP connection。request 之后,我们关闭 connection,然后立刻为下一个 request 重新执行 handshake。
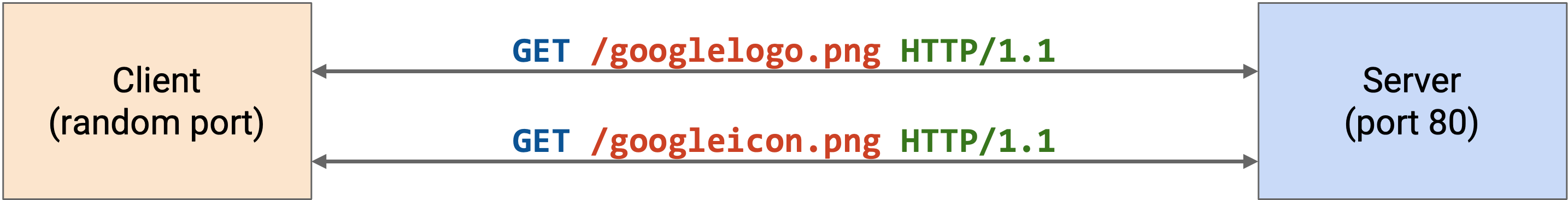
HTTP 1.1 通过允许多个 HTTP request 和 response 在同一个 connection 上 pipelined 来优化这一点。现在,我们不再需要为每个 request 建立单独的 TCP connection(带有单独 handshake)。
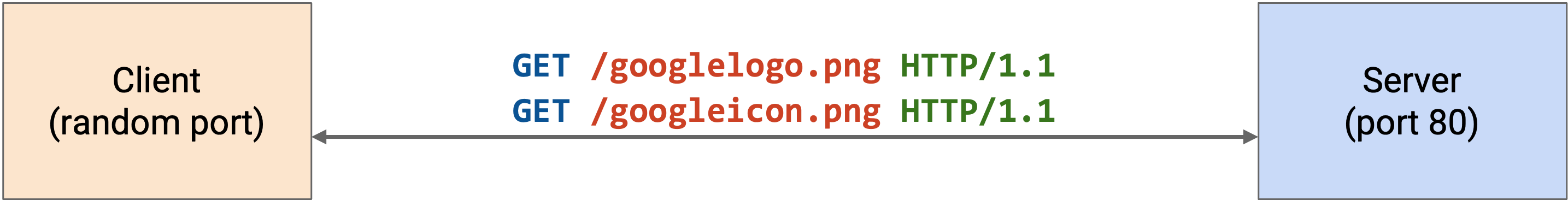
这个优化的一个缺点是,server 现在必须保持更多同时打开的 connection。server 需要有某种方式让 connection timeout。如果 server 被大量 open connection 压垮,client 可能收到类似 503 Service Unavailable 的 error。攻击者可以在 denial-of-service attack 中利用这一点。
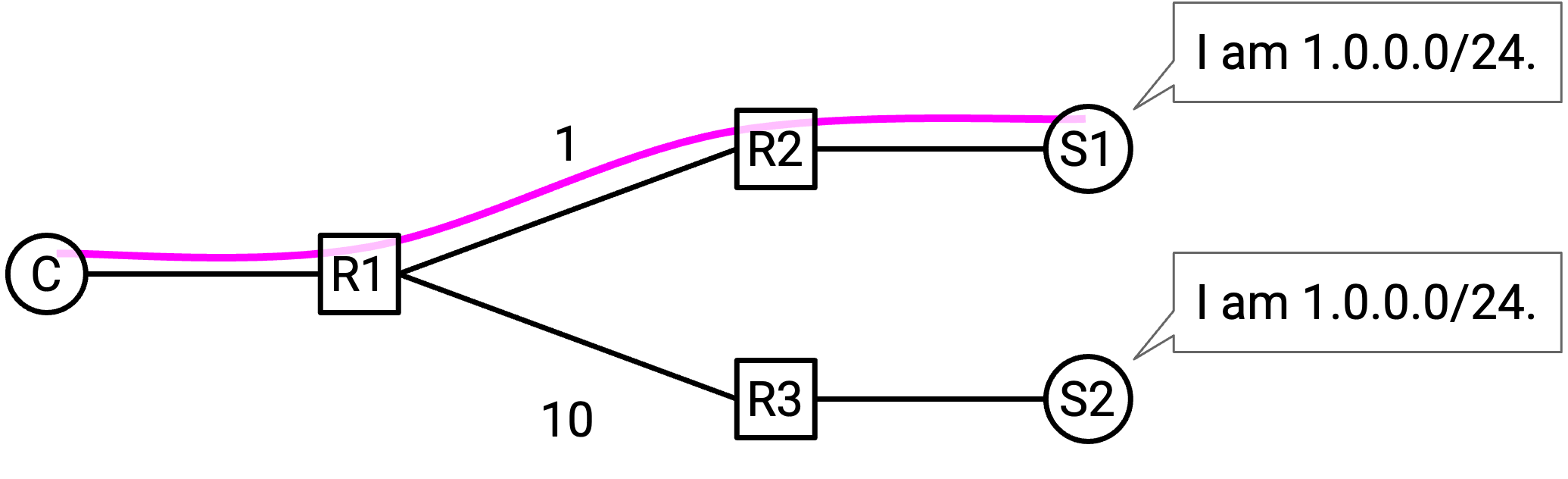
用 Caching 加速 HTTP:类型¶
另一种加速 HTTP 的策略是 cache response,避免对同一份数据发起重复 request。
如果不 cache,每个 request 都必须到达 server。
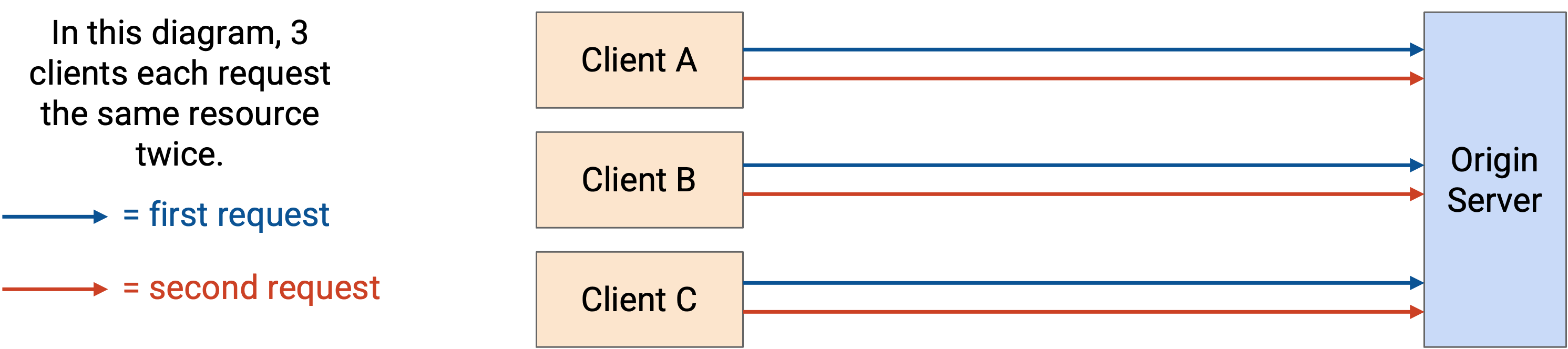
HTTP cache 有三种类型:
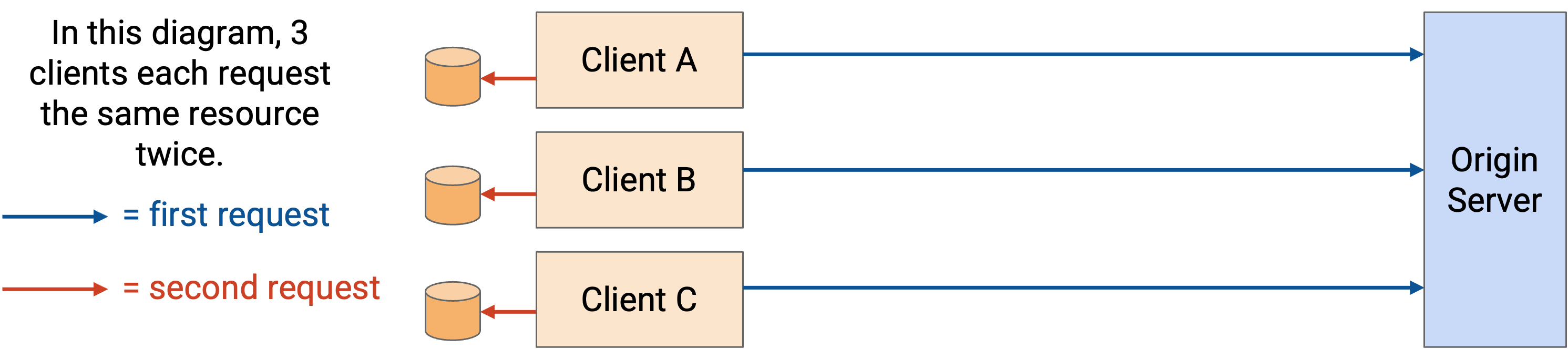
Private cache 与连接到 server 的某个具体 end client 相关(例如你自己 browser 中的 cache)。现在,如果同一用户第二次请求同一个 resource,就可以从本地 cache 获取这个 resource。不过,private cache 不在用户之间共享。
Proxy cache 位于网络中(不在 end host 上),由 network operator 控制,而不是由 application provider 控制。这些 cache 可以在许多用户之间共享,因此用户第一次请求某个 resource 时,可能会从 proxy cache 而不是 origin server 获取数据。
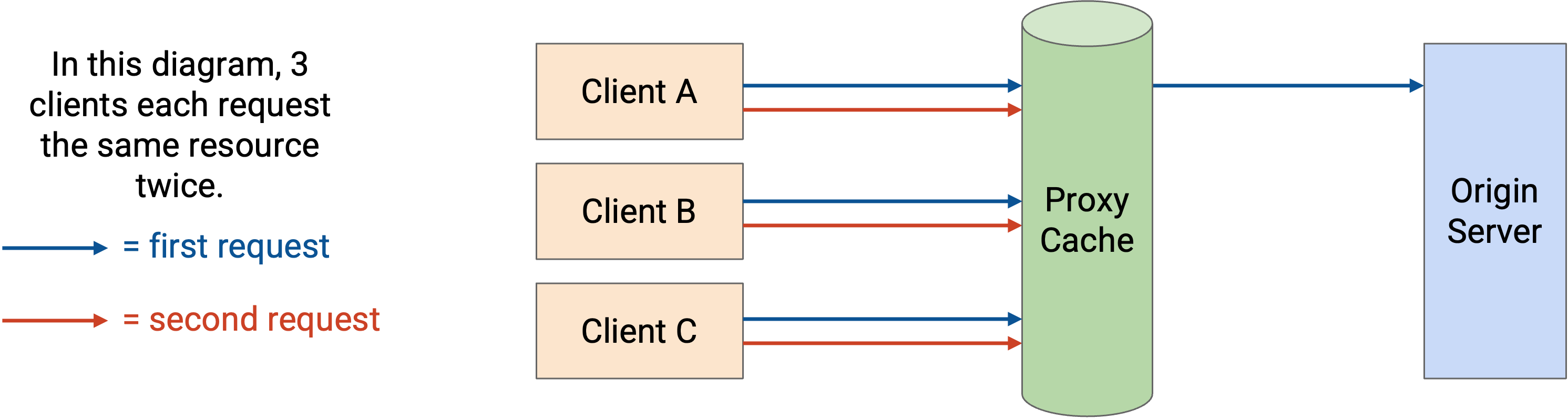
proxy cache 的一个问题是,client 需要某种方式被重定向到 proxy cache。application 并不运行这个 proxy cache,因此 origin server 不一定知道 proxy cache 的存在。network operator 需要某种方式控制 end client,告知它们 proxy cache。
一种常见方法是在 DNS response 中说谎。如果 network operator 同时控制 proxy cache 和 recursive resolver,就可以做到这一点。当 client 向 origin server 发起 request 时,它必须查找 origin server 的 IP 地址。recursive resolver 可以撒谎并说:「origin server 的 IP 地址是 1.2.3.4(proxy cache 的 IP 地址)。」现在,发往 origin server 的 request 会改为发往 proxy cache,由 proxy cache 提供 cached response。或者,如果请求的 resource 不在 proxy cache 中,proxy cache 可以向 origin server 发起 request,然后 cache 再把 request 服务给用户。
proxy cache 的另一个问题是,application 并不管理 proxy cache。origin server 必须相信 proxy cache 在做正确的事情(例如尊重 cache expiry date,提供正确数据)。
Managed cache 位于网络中,并由 application provider 控制。注意,managed cache server 是单独部署的,不是生成 content 的原始 server。由于这些 cache 由 application provider 控制,这给了 application 更多控制权。
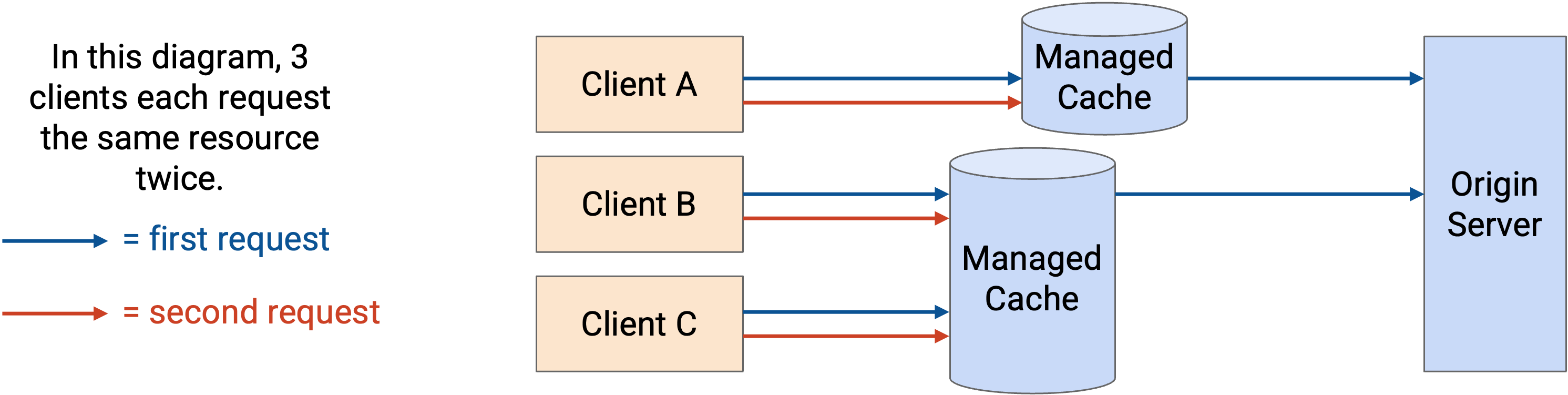
因为 application 同时控制 origin server 和 cache,它们可以自己把用户重定向到 cache。例如,如果你从 origin server 请求 YouTube video page,reply 可能包含 HTML(video title、comments)。这个 HTML 随后可能包含专门从 proxy cache 获取 video 和 image 的 link(例如从 static.youtube.com 而不是 www.youtube.com 加载)。
用 Caching 加速 HTTP:收益和缺点¶
Caching 对所有人都有好处。client 可以更快加载页面,因为它们可以避免重复 request,并使用附近的 proxy。ISP 受益,因为网络中发送的 HTTP request/response 更少,因此它们可以建设更少的 bandwidth。server 受益,因为用户发起的 request 更少,它们不需要处理那么多 request。
client、ISP 和 server 都关心给 client 提供良好性能。client 想以高质量观看视频,而 ISP 和 application 会通过提供良好性能获得更多客户。Caching 帮助所有人达成这一点,因为 client 可以从更近的 cache(本地或网络中)更高效地获得 request 服务,latency 更低。另外,回忆一下,TCP throughput 和 RTT 成反比,因此到更近 server 的更短 RTT 意味着我们获得更高 throughput。这对 video 这样的大内容尤其有帮助。
思考 caching 时,我们必须考虑 content 在未来 request 中是否会变化。有些 HTTP resource 是 static 的。如果你请求 Google logo,它在多次 request 之间保持不变。
其他 HTTP resource 是 dynamic 的。如果你发起 Google search request,response 可能会根据谁询问、何时询问而变化。server 需要为每个 request 动态生成不同 response。
有些 resource 是 static 的,可以被 cache 并由 proxy 或 managed cache 提供;而其他 resource 必须动态生成。例如,如果你发起 Google search,HTML response 很可能需要由 origin server 动态生成。不过,这个 HTML 可以包含一个 link,用来从某个 managed cache server 获取 Google logo 这个 static resource。
方便的是,image 和 video 这类较大的 resource 是 static 的,可以积极 cache。dynamic content,比如定制化 HTML page,往往更小。client 可以从 origin server(远处)请求 dynamic content,并使用 cache 和 proxy(更近)获取所有 static content。
用 Caching 加速 HTTP:实现¶
要实现 caching,我们需要使用 header 携带一些关于 caching 的 metadata(例如数据可以 cache 多久)。这也是 header 允许原始 protocol(最初并不支持 caching)扩展的另一个例子。
HTTP/1.0 中原始的 legacy caching 功能使用 Expires header,它只是指定数据可以 cache 多久。在 HTTP/1.1 中,引入了更复杂的 Cache-Control header。为了支持 compatibility,一些 web server 会同时返回这两个 header。HTTP/1.0 client 不理解较新的 Cache-Control header,会忽略它。HTTP/1.1 client 会优先使用较新的 Cache-Control header,而不是较旧的 Expires header。
Cache-Control header 指定哪些类型的 cache 可以 cache 数据,以及数据可以 cache 多久。例如,如果 resource 是 dynamic 且因用户而异,但对某个特定用户随时间保持相同,那么 server 可以回复:Cache-Control: private, max-age:86400。这表示这个 content 只应该存储在用户本地 cache 中(不在共享 proxy/managed cache 中),并且可以存储一天(86400 秒)。
有些数据不能被 cache(例如频繁变化的 dynamic content)。在这种情况下,server 可以设置 Cache-Control: no-store,表示 client 和 proxy 不能 cache 这个 content。
Cache-Control header 是可选的,因此不能保证 client 会读取或遵守这个 header。你可以把这个 header 理解为 server 请求 cache 某些内容。对不由 application provider 运营的 proxy cache 来说,这尤其值得担心。相比之下,private cache 由 client(也就是它们的 browser)运行,违反规则只会影响 client 自己。managed cache 由同一个 application provider 运行,因此它们可以强制 managed cache 遵守 origin server 的规则。
这个 header 也可以用于更复杂的 policy。例如,server 可能说:你可以 cache 这份数据,但在使用 cached data 之前,请先发一个 HTTP HEAD request 重新请求 header,并重新验证数据。如果 header 表明数据已经改变,就让 cache 失效。
Content Delivery Network(CDN)¶
前面我们看到,managed cache 是一种很好的 caching 和提升用户性能的策略。与 private cache 不同,它们在用户之间共享(例如,用户第一次请求某个内容时也可以由 cache 服务)。另外,与 proxy cache 不同,它们由 application provider 控制,这给了 application 更多控制权。application 可以确保 cache 遵守 origin server 设置的规则,而 origin server 可以控制用户被重定向到哪些 cache。
在网络中部署 managed cache 引出了 content delivery networks(CDNs) 的思想:CDN 是网络中一组提供 content(例如 HTTP resource)的 server。
为了获得良好性能,我们会尝试把 CDN 放在靠近 end user 的地方。这里的近既意味着地理上近,也意味着从网络角度看近(hop 更少)。
CDN 给我们带来 caching 的所有好处。由于 server 更近,用户能以更高性能获取 content。我们可以减少所需的 network bandwidth 和 infrastructure,因为用户的大多数 request 会发往附近 server,而不是单个(可能很远的)origin server。
CDN 允许 provider 更容易扩展 server infrastructure。使用单个 origin server 时,我们必须通过让这台 server 极其强大、拥有极高 bandwidth 来扩展它。相比之下,使用 CDN 时,我们只需要在 Internet 各处添加更多小型 server,就能扩展。
CDN 也为 provider 提供更好的 redundancy。如果单个 origin server 宕机,服务可能不可用。相比之下,使用 CDN 时,如果一台 server 宕机,用户仍然可以被重定向到其他 server。
CDN 部署¶
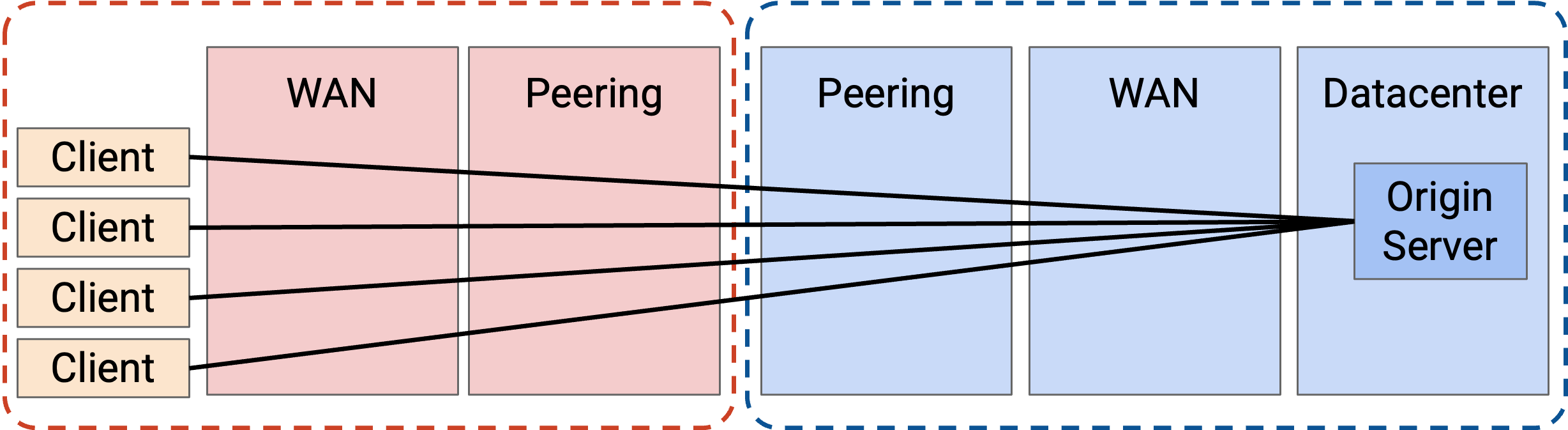
回忆一下我们的 Internet 模型:client 的 request 会通过 ISP 拥有的 WAN router 转发,直到到达 peering location。然后,request 进入 application provider 网络中的 peering location。request 通过 application 的 WAN network,直到到达 datacenter network,origin server 就在那里。
如果我们不部署任何 CDN,每个 request 都必须到达 origin server。这会带来最大 latency(相对于后面使用 CDN 的选项),导致最低性能。另外,这需要穿越最多 bandwidth,也就是说我们必须建设更多 bandwidth。最后,这要求 origin server 扩展到能处理每个 request。
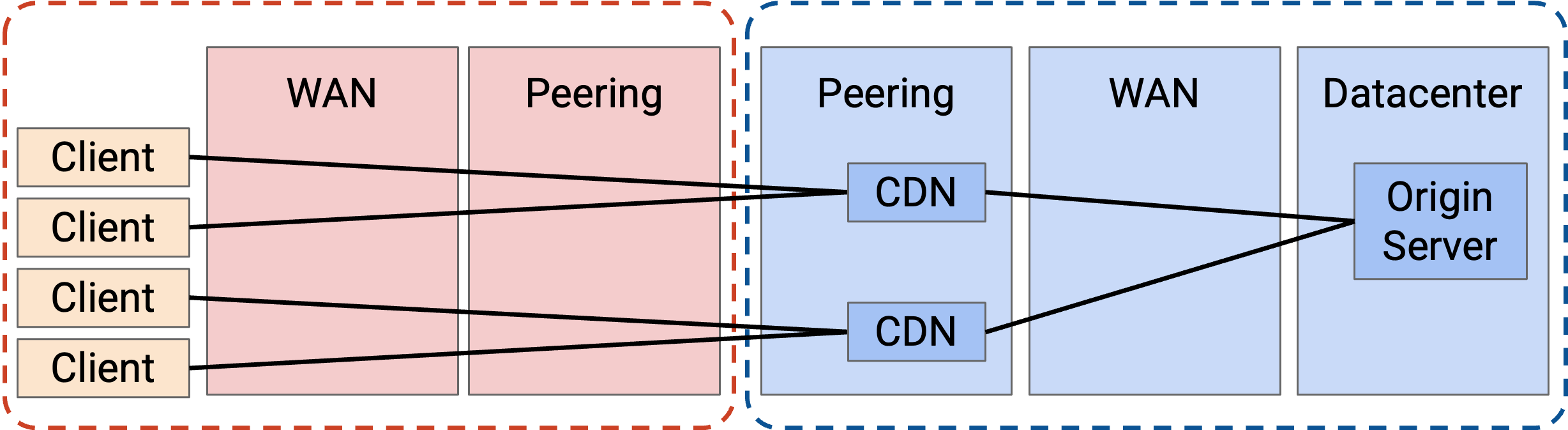
更好的选择是在 application provider network 的 edge 部署一些 CDN server。例如,如果 Google 的 network 在 New York 与 ISP network peering,我们可以在那里放一些 CDN。
现在,通过 application provider network 发送的 bandwidth 大大降低。origin server 把 video 发给 CDN 一次,CDN 就可以把这个 video 提供给许多用户。application network 不再需要扩展它的 WAN network。
另外,正如之前看到的,我们现在可以通过添加更多 CDN 来扩展,而不是升级单个 origin server。我们也有更多 redundancy。
我们还可以做得更好,把 caching 推到网络更深处。现在,application 会在 ISP 的 network 内部署 server。
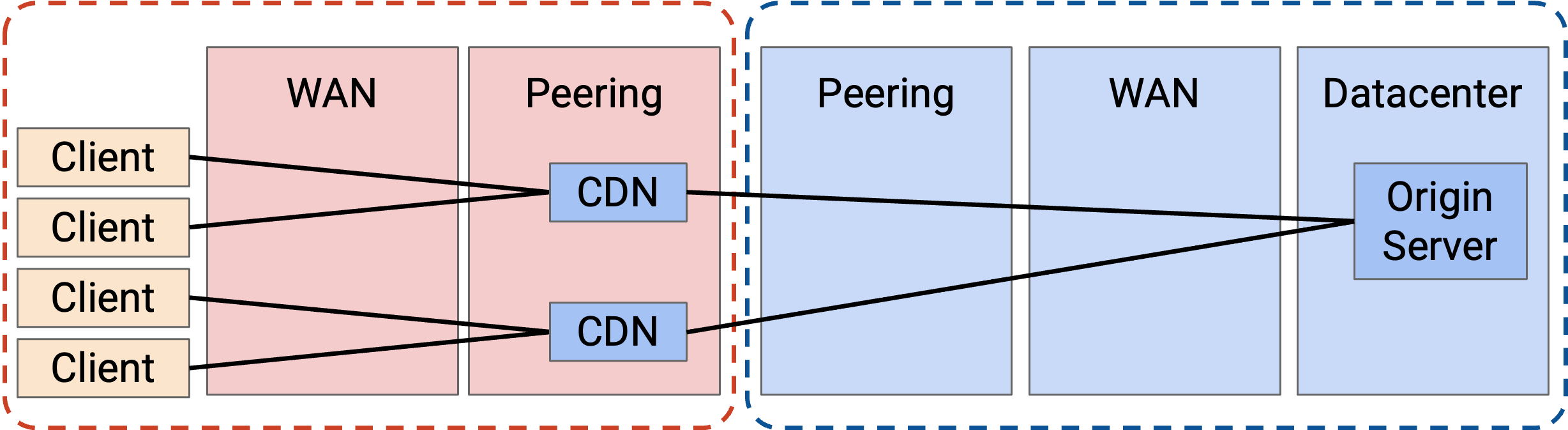
为什么 ISP 会同意让 application 在自己的 network 中部署 CDN?事实证明,这对所有人都是互利的。ISP 的客户会获得更好性能,因为他们可以使用这个新的、更近的 CDN。另外,用户和 CDN 之间的 heavy traffic 现在都包含在 ISP 的 network 内部。这意味着 ISP 在 ISP 与 application 之间的 peering connection 上需要更少 bandwidth(因为 content 只需要通过这个 peering connection 发送一次)。
实践中,ISP 和 CDN 经常合作部署 server。例如,application 免费提供 server,ISP 免费把 server 接入网络。在某些情况下,ISP 和 CDN 需要就某些付款进行协商(CDN 给 ISP,或 ISP 给 CDN),这取决于 server 在网络中的部署位置,以及 server 和 connectivity 的成本。不过,双方都有部署这些 server 的利益。
我们可以尝试更进一步,但最终会遇到 cost-benefit trade-off。在最极端的情况下,我们可以在每个人家里部署一个 CDN,但成本大概会超过收益。尤其是,当多个用户共同使用 CDN 时,CDN 效果最好。collective cache 更大,而且一次部署可以覆盖许多用户。
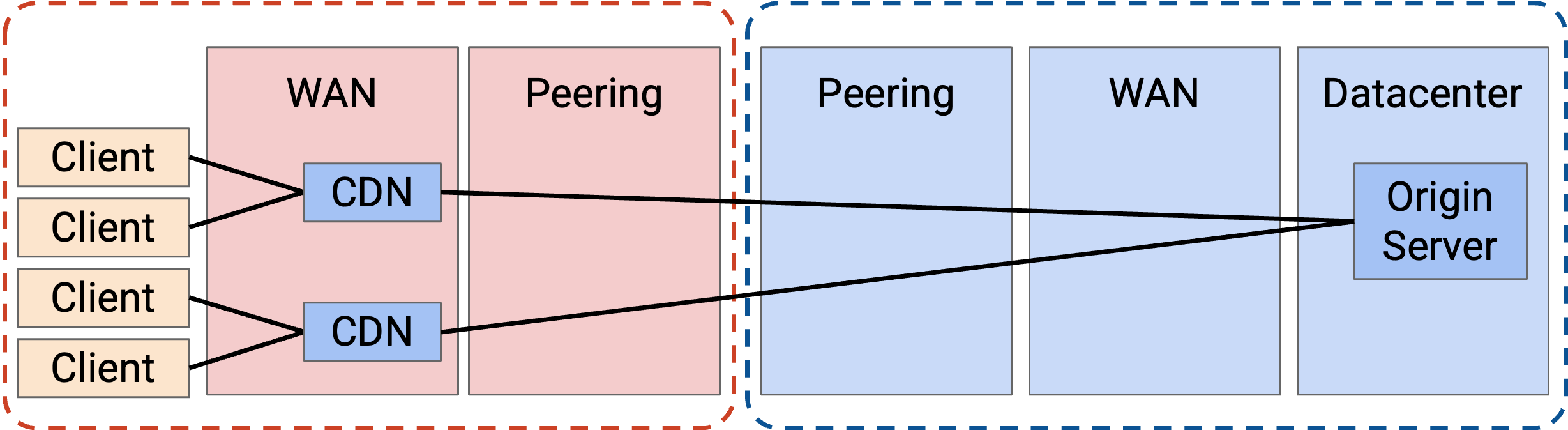
更一般地说,添加新 CDN 的成本,与因为建设更少 bandwidth 而节省的钱之间存在 trade-off。实践中,CDN 确实存在于 ISP network 中,因为在那里安装它们仍然有利可图。
2023 年 Sandvine(一家 packet inspection 公司)的报告显示,所有 Internet traffic 中有 15% 来自 Netflix,11.4% 来自 YouTube,4.5% 来自 Disney+。如果 ISP 只为这三个 application 在自己的 network 中安装 server,就可能少建设 25% 的 network capacity。
Google、Netflix、Amazon、Facebook 等主要 application provider 会在自己的 network 和 ISP network 中都部署 CDN。
如果你是 application provider,你可能不是 Google 或 Amazon 这样的科技巨头,但仍然希望自己的 content 能通过 CDN 提供,以获得良好性能。这些较小的 application 可能负担不起安装自己的 CDN。然而,Cloudflare、Akamai 和 Edgio 等公司已经部署了 CDN,你可以付费让这些公司把你的 content 部署到它们现有的 CDN 上。这些 CDN provider 也会在自己的 network 和 ISP network 中部署 infrastructure。
CDN 也可以由 ISP 使用,因为 ISP 自身也可能有提供 content 的 application。当你为 Internet service 付费时,ISP 可能也会提供 TV service(live TV 或 video on demand)。这些 ISP 会安装自己的 CDN,高效地向你提供 TV content。
从根本上说,CDN 中的 server 和 Internet 上任何其他提供 content 的 server 是一样的,只是它们通常经过高度优化,用于存储和交付大量 content。有些 server 可能更擅长存储并提供大量 content,而另一些 server 可能更擅长快速向大量客户提供较小内容。
把 Client 引导到 Cache¶
在 CDN 中,Internet 各处的许多不同 server 都在提供相同 content。client 如何知道应该联系哪台 server?
DNS 中的一些技巧也可以应用到 CDN。我们可以使用 anycast,让多台 server advertise 同一个 IP prefix。这允许 routing algorithm 找到到任意一台 server 的最佳路径。
anycast 的一个问题与 long-running connection 有关。假设 client 与其中一台 server 有一个持续中的 TCP connection。在这个 connection 期间,网络中的某条 intermediate link 发生故障。由于所有 server 都有相同 IP 地址,从 intermediate router 的角度看,把 packet 转发到任意一台 server 都是有效的。intermediate router 现在可能开始把 packet 转发到另一台 server(具有相同 IP 地址)。然而,这个 TCP connection 是和原始 server 建立的,这台新 server 没有办法继续原来的 connection。
注意,当我们在 DNS 中使用 anycast 时,这个问题并不存在,因为 DNS connection 非常短(通常只有一个 UDP packet)。
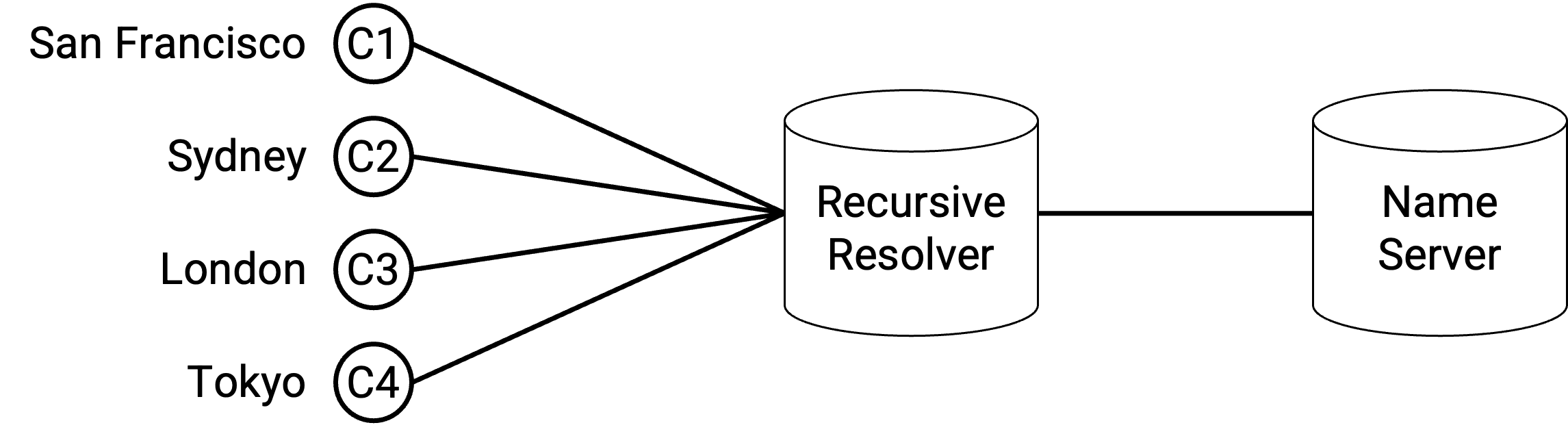
我们也可以用 DNS 做 load-balance。与 anycast 不同,现在 server 拥有不同 IP 地址,尽管它们仍然都有相同 domain。当 client 查询 domain-to-IP mapping 时,DNS name server 可以根据 client 的位置提供不同 IP 地址。
这种基于 DNS 的方法没有 anycast 在 long-lived connection 上的问题,因为 server 现在有不同地址。router 不会突然开始把 packet 转发到另一台 server。
基于 DNS 的方法有一个问题:granularity 不足。举一个极端例子,假设 Comcast 的 ISP 中所有人都使用同一个 recursive resolver。这意味着所有人都把 DNS query 发送给 resolver,再由 resolver 向 application name server 发起 query。application name server 只能看到 DNS request 来自 Comcast,并且必须给 Comcast 返回单个 IP 地址。现在,Comcast network 中的每个用户都会使用同一台 server,即使这些用户分布在全世界各地。
比 anycast 或 DNS 更 robust 的方法是 application-level mapping。当 origin server 收到 HTTP request 时,response 中的 link 可以根据 request 来自哪里,指向不同 server(例如 static1.google.com 或 static2.google.com,两台位于不同地点的 server)。或者,origin server 可以用 HTTP 300-level status code 回复,把用户重定向到合适的 server。
这种 application-level 方法没有 DNS 的 granularity 问题,因为 application 可以在 HTTP request 中看到 client 的 address。它也没有 anycast 的问题,因为不同 server 可以拥有不同 IP 地址。
不过,就像 DNS load-balancing 一样,application 仍然需要某种方法来猜测离 client 最近的 server(这里的近可能是地理上近,也可能是基于 network topology 的近)。
application-level mapping 的一个好处是可以根据 content 获得额外 granularity。例如,热门 video 可以部署到许多 server 上,让每个 client 都能从附近 server 获取 video。相比之下,很少访问的冷门 video 可以部署到较少 server 上,并要求用户去更远的地方获取 content。
更新版本的 HTTP¶
随着 Internet 增长,HTTP 开始被越来越多 application 使用,因为它是一个非常容易泛化的 protocol。
最终,HTTP security 变成越来越重要的问题。运行 HTTP 的银行 server 大概不希望信息以人类可读 plaintext 的形式在网络上传输,因为 intermediate router 或恶意攻击者都可以读取它。
HTTPS 是 HTTP 的扩展,引入了额外安全性。名为 TLS(Transport Layer Security)的 protocol 构建在 TCP 之上,用户会交换 secret key,并在通过 bytestream 发送 message 之前对其加密。HTTPS 拥有相同的基础 protocol,但现在运行在 TLS 之上(TLS 本身位于 TCP 之上),而不是直接运行在原始的不安全 TCP 之上。近年来,网站一直在推动升级到 HTTPS,截至 2024 年,超过 85% 的网站现在默认使用 HTTPS。
HTTP/2.0 于 2015 年引入,是自 1997 年以来这个 protocol 的第一次重大修订。这次修订的主要目标是通过降低 latency、提升 page load speed 来改善性能。
HTTP/2.0 引入了 server-side pushing,即即使 client 没有发出 request,server 也可以发送 response。这允许 server 预测并提前提供用户可能需要的内容,而不必等待用户发起 request。例如,如果我们进行一次 Google search,结果的 HTML 会返回。然后,用户的 browser 解析 HTML,发现它需要 Google logo,并发起另一个 HTTP request。使用 HTTP/2.0 时,server 可以在等待用户 request 之前,提前把 Google logo 给用户。
HTTP/2.0 还有其他性能改进。Header 可以被压缩以节省空间。Request 和 response 可以设置 priority,使高优先级 content(例如搜索结果的文本)先于低优先级 content(例如 Google logo)交付。并发 request 可以被更高效地 multiplex。如果第一个 request 有 4 GB response,而第二个 request 有 1 KB response,朴素实现可能导致第二个 response 卡住,等待第一个完成。HTTP/2.0 允许更智能地管理这些 response。
HTTP/2.0 已被 client(例如现代 browser)和 server(例如 CDN)广泛采用。
HTTP/3.0 于 2022 年引入(与 HTTP/2.0 相比并不久,尤其是与 1.1 到 2.0 的间隔相比)。它的语义和 HTTP/2.0 相同,但替换了底层 transport layer protocol。HTTP/3.0 不再运行在 TCP bytestream 上,而是运行在一个名为 QUIC 的新 transport protocol 上;QUIC 是专门为配合 HTTP/3.0 良好工作而定制构建的。QUIC = Quick UDP Connections,由 Google 设计,并在 IETF 标准化。
HTTP/3.0 是一个例子:我们有意放弃一个核心网络范式(layering),以换取更高效率。通过给设计者自由,让他们同时定制 transport layer(QUIC)和 application layer(HTTP/3.0)protocol,我们可以设计出彼此协同良好的两个 protocol。