Collective Implementations¶
动机:实现 AllReduce¶
现在我们已经定义了 7 个 collective,就可以开始思考如何在 network 中实现它们。要实现一个 collective,需要回答两个问题:我们用什么 topology 连接 node?为了高效完成 operation,node 之间必须交换哪些 data?
一旦决定使用什么 topology、交换什么 data,就可以分析设计的性能。我们总共使用了多少 network bandwidth?operation 完成需要多长时间?也可以关注其他 performance metric,但这份 notes 会聚焦这两个。
为了衡量性能,我们会定义一些变量。总共有 \(p\) 个 node。每个 vector 总共是 \(D\) bytes。这意味着每个 vector element(也就是图中的每个 box)是 \(D/p\) bytes。
在本节中,我们会设置 \(p=5\),让一些 demo 更有说明性。注意,这也意味着每个 vector 现在有 5 个 element,而不是 4 个 element。(旁注:记住,vector 表示任意 data,我们把每个 vector 划分成 \(p\) 个等大小 sub-vector,其中 \(p\) 是 node 总数。把 \(p\) 从 4 增加到 5 不一定意味着我们有更多 data。它可能只是意味着我们把相同 data 拆成 5 个 chunk,而不是 4 个 chunk。)
本节会聚焦实现 AllReduce collective,不过这些思想也可以应用到其他 collective。回忆一下,AllReduce 会计算 vector 的 element-wise sum,然后把 sum vector 发送给所有 node。

方法 1:Full Mesh¶
首先考虑的 topology 是 full-mesh,其中每个 node 都有一条 direct link 连到每个其他 node。
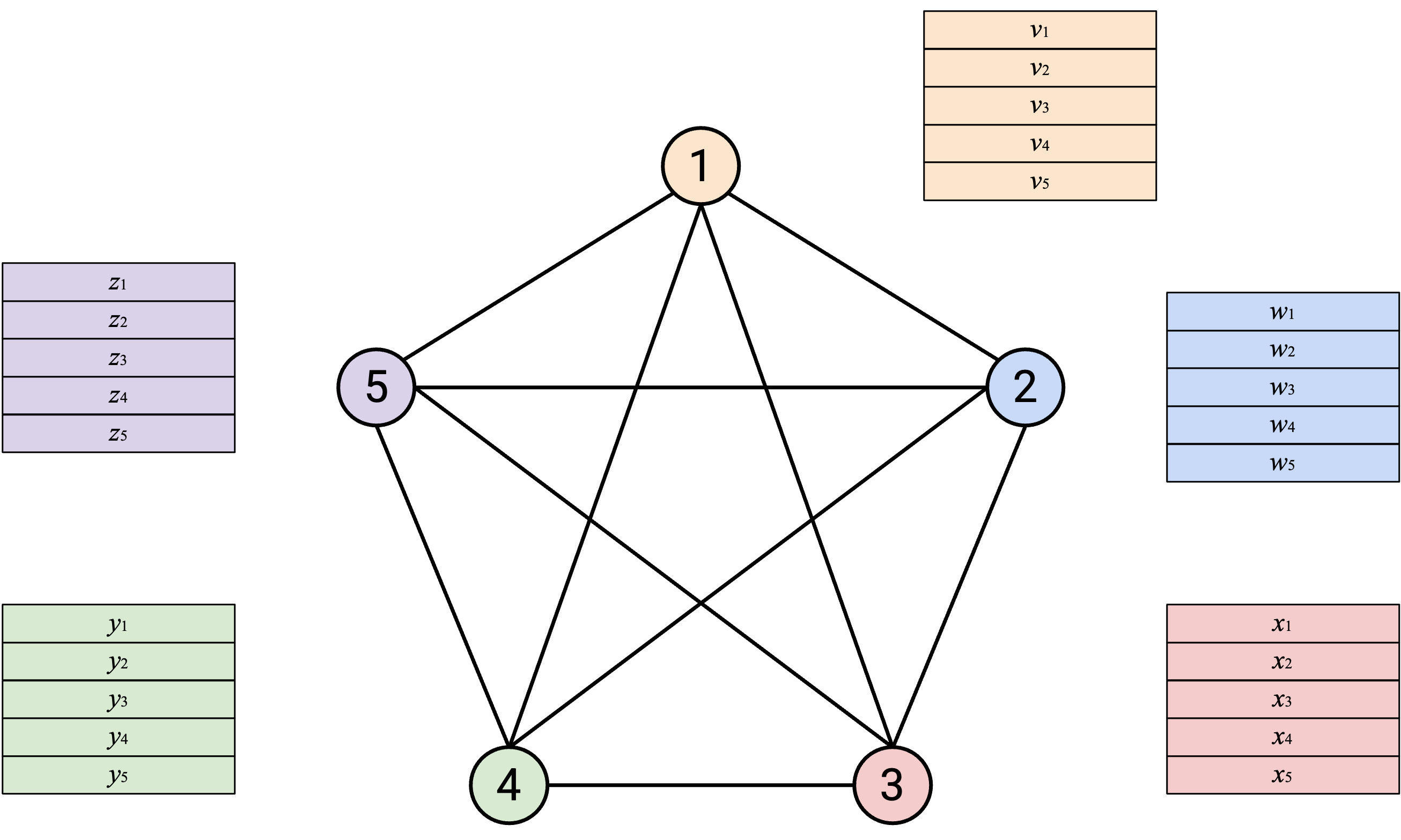
使用这个 topology,可以按以下步骤实现 AllReduce:首先,每个人把自己的整个 vector 直接发送给每个其他 node。
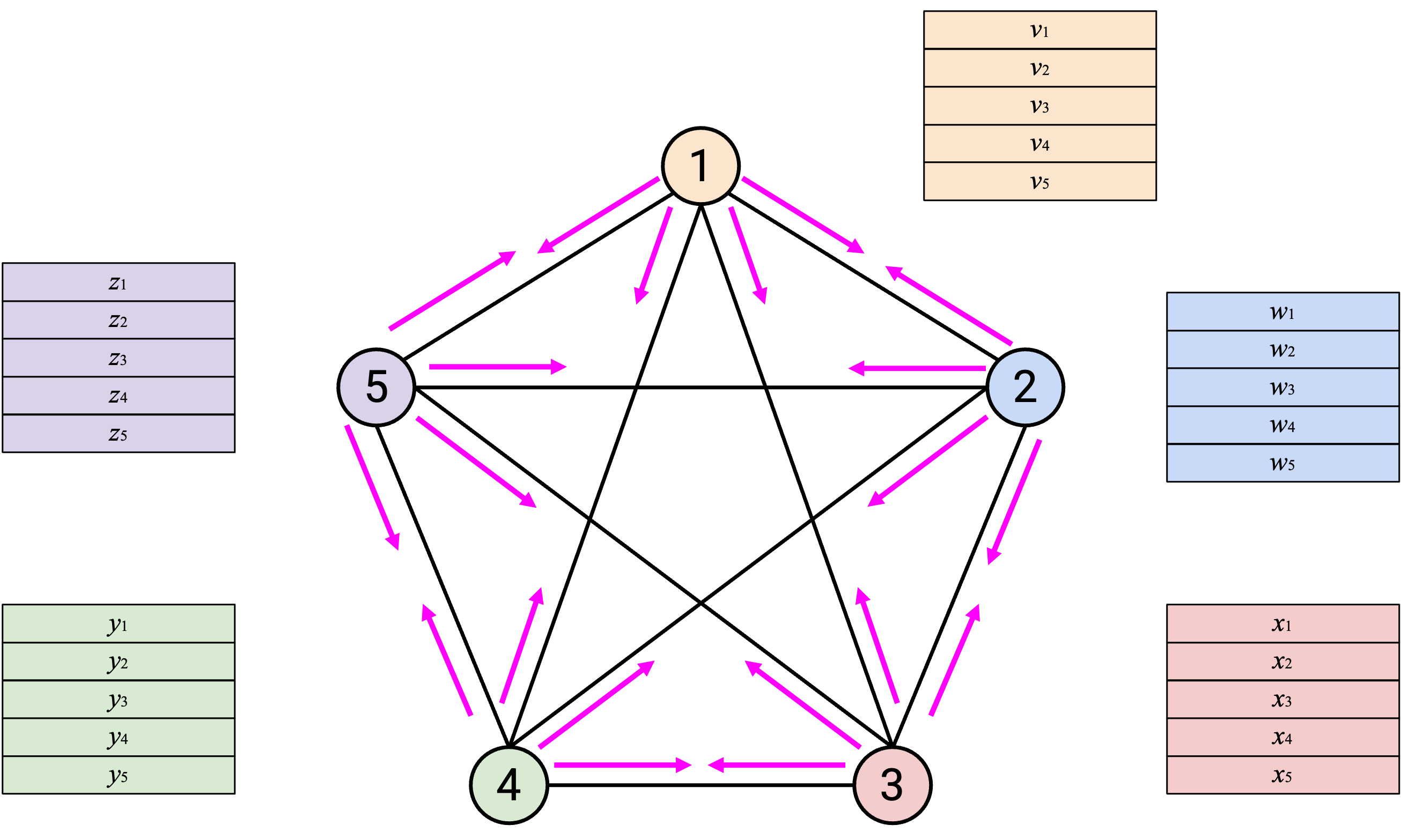
然后,每个 node 对自己收到的所有 vector 求和。
这种方法使用多少 bandwidth?每个 node 都需要把自己的整个 vector(\(D\) bytes)发送给另外 \(p-1\) 个 node,所以每个 node 发送 \(D(p-1)\) bytes。总共有 \(p\) 个 node,因此发送的总 data 是 \(Dp(p-1) = O(D \cdot p^2)\) bytes。
这种方法需要多少时间?这取决于 node 和 link 的具体 resource limit;但如果假设没有 resource limit,所有 vector 发送都可以同时发生,并在一个 time step 中完成。换句话说,Node 1 同时使用自己的 3 条 outgoing link,把 data 发送给所有其他 node。与此同时,Node 2 也可以同时使用自己的 3 条 outgoing link,把 data 发送给所有其他 node。假设没有 resource limit,这种方法只需要一个 time step 完成,其中每个 node 在每个 time step 需要发送和接收 \(2 \cdot D \cdot (p-1)\) bytes。(每个 node 发送 \(D \cdot (p-1)\) bytes,并接收 \(D \cdot (p-1)\) bytes,把两者相加就得到额外的 factor 2。)
方法 2:在一个 Node 上 Reduce¶
在下一个 topology 中,我们让一个单独 node 完成全部 computation work:
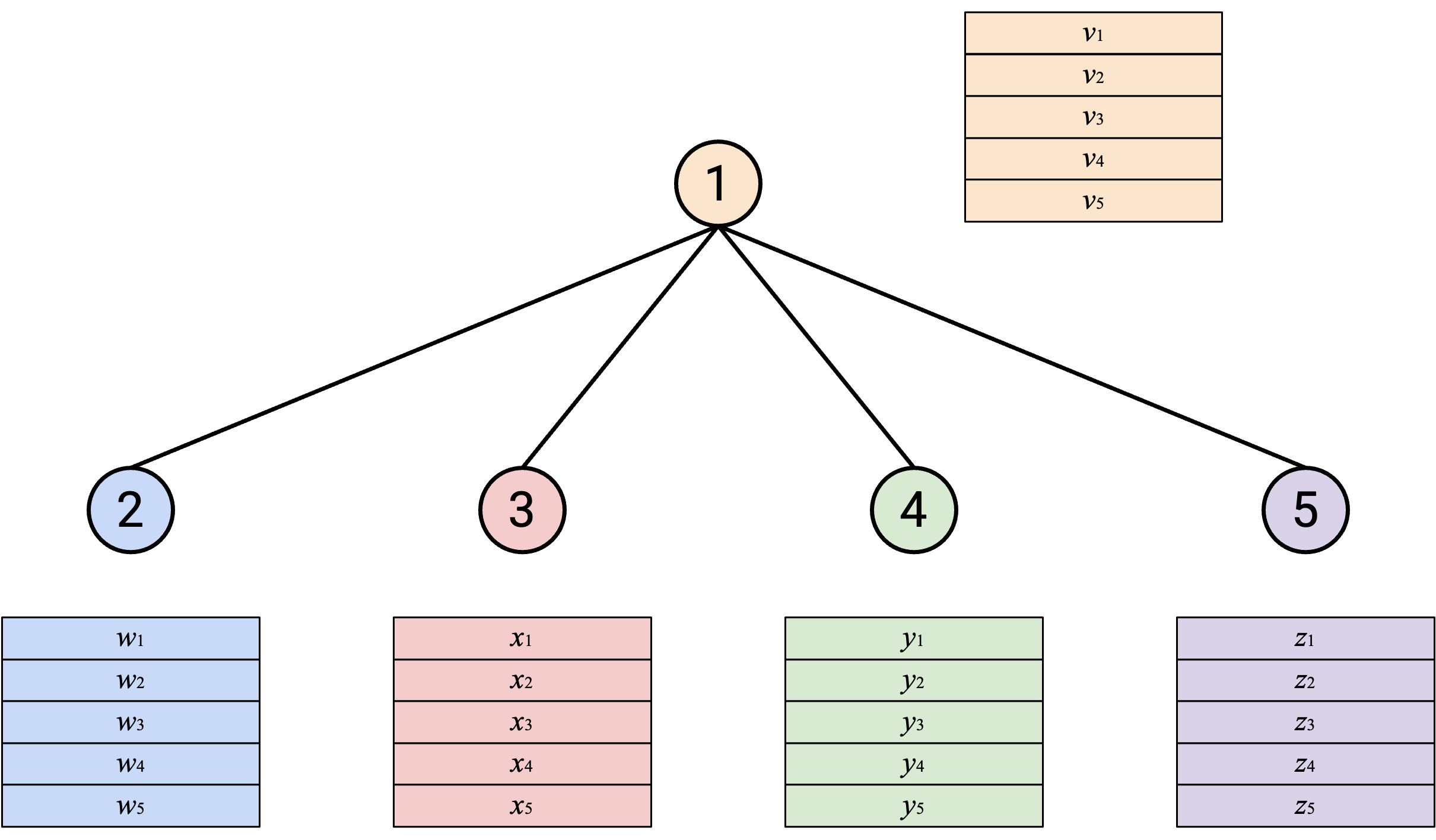
运行 AllReduce:首先,所有人(除了 Node 1)把自己的 vector 发送给 Node 1。
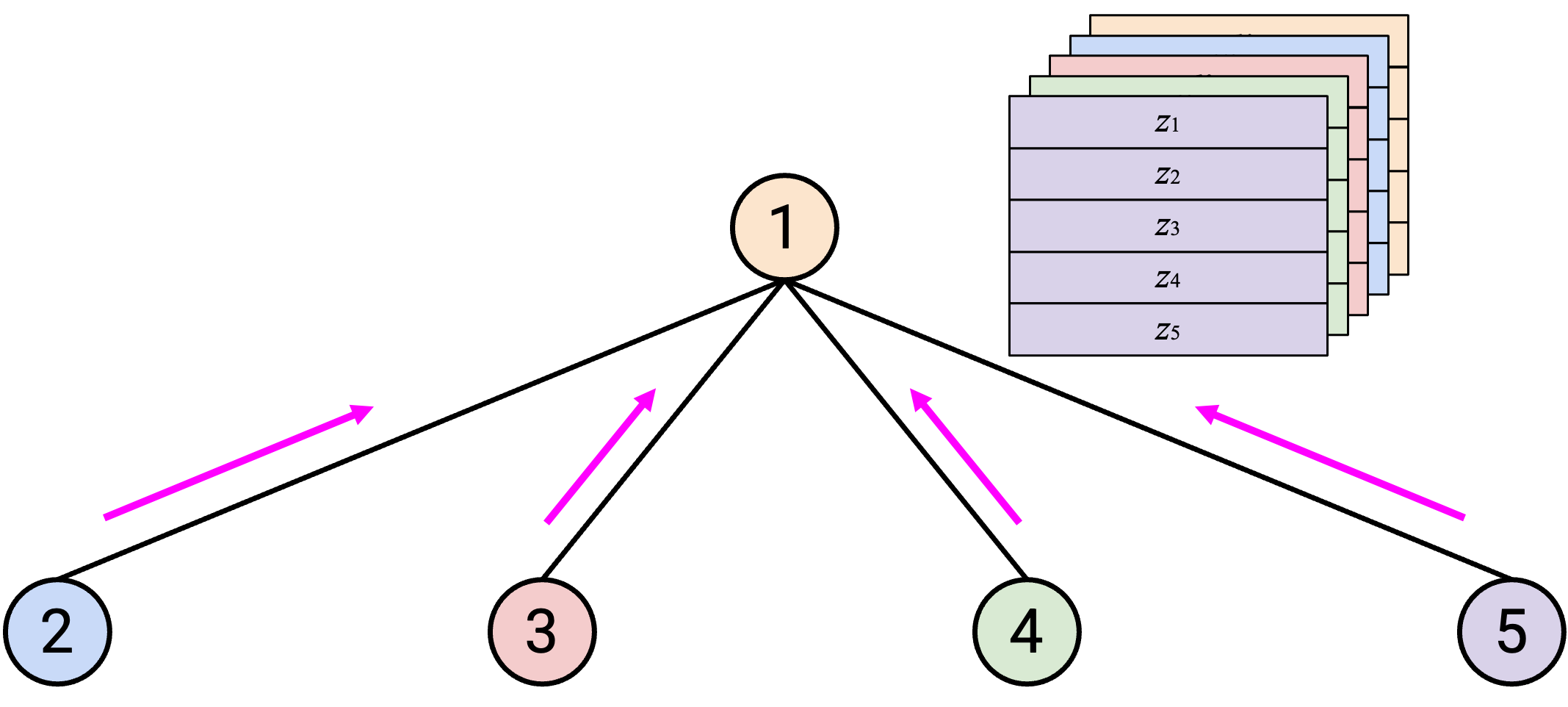
然后,Node 1 计算 sum,并把 sum 发送回所有人。
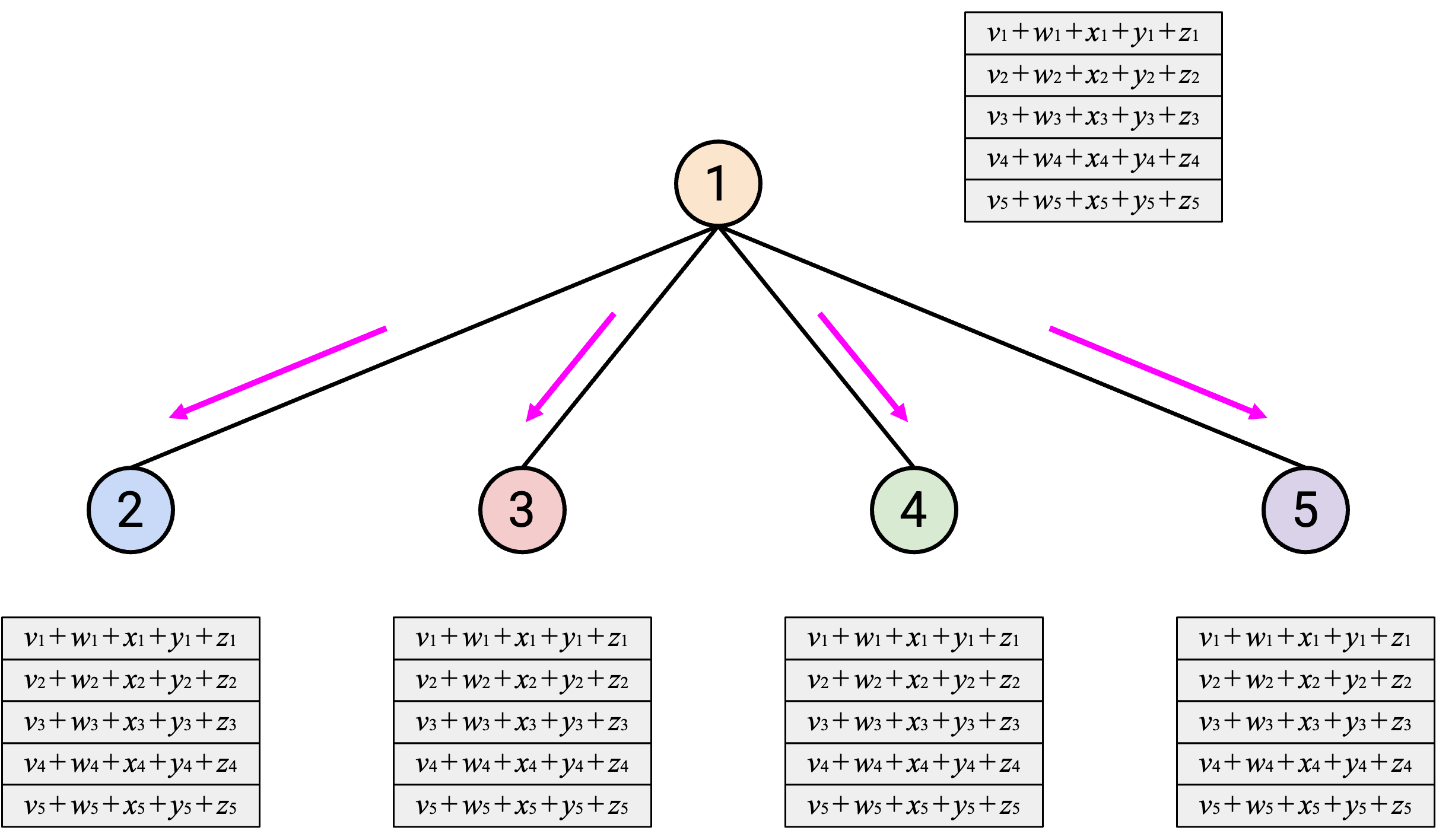
这种方法使用多少 bandwidth?每个 node(除了 Node 1)都需要把自己的整个 vector 发送给 Node 1,也就是发送 \(D\) bytes。有 \(p-1\) 个 node 需要发送 data,所以第一步发送的总 data 是 \(D(p-1)\) bytes。
然后在第二步中,Node 1 必须把 sum vector 发送给其他所有人。sum vector 是 \(D\) bytes,并且必须发送给另外 \(p-1\) 个 node,所以第二步发送的总 data 也是 \(D(p-1)\) bytes。
两步合计,我们发送了 \(2 \cdot D \cdot (p-1) = O(D \cdot p)\) bytes。注意,这比 full-mesh 方法发送的 \(O(D \cdot p^2)\) bytes 好了 \(p\) 倍。
这种方法需要多少时间?同样,它取决于具体 resource limit;但如果假设没有 resource limit,所有人可以同时把 vector 发送给 Node 1。然后,我们必须等待 Node 1 计算 sum。sum 计算完成后,Node 1 可以同时把 sum 发送回其他所有人。总计,这种方法需要 2 个 time step 完成,其中 Node 1 在每个 time step 必须发送或接收 \(D \cdot (p-1)\) bytes。
这里我们没有精确衡量一个「time step」到底有多长,但主要比较点是:在这种方法中,第一步的所有发送必须完成后,第二步的发送才能开始。相比之下,在第一种方法中,所有 data sending 都可以同时发生。
这种方法的一个缺点是 Node 1 是 single point of failure。实践中通常不会使用这种方法。
方法 3:Tree-Based¶
在下一个 topology 中,我们构建一棵 binary tree。记住,这里的 binary 意味着每个 node 最多有 2 个 child。
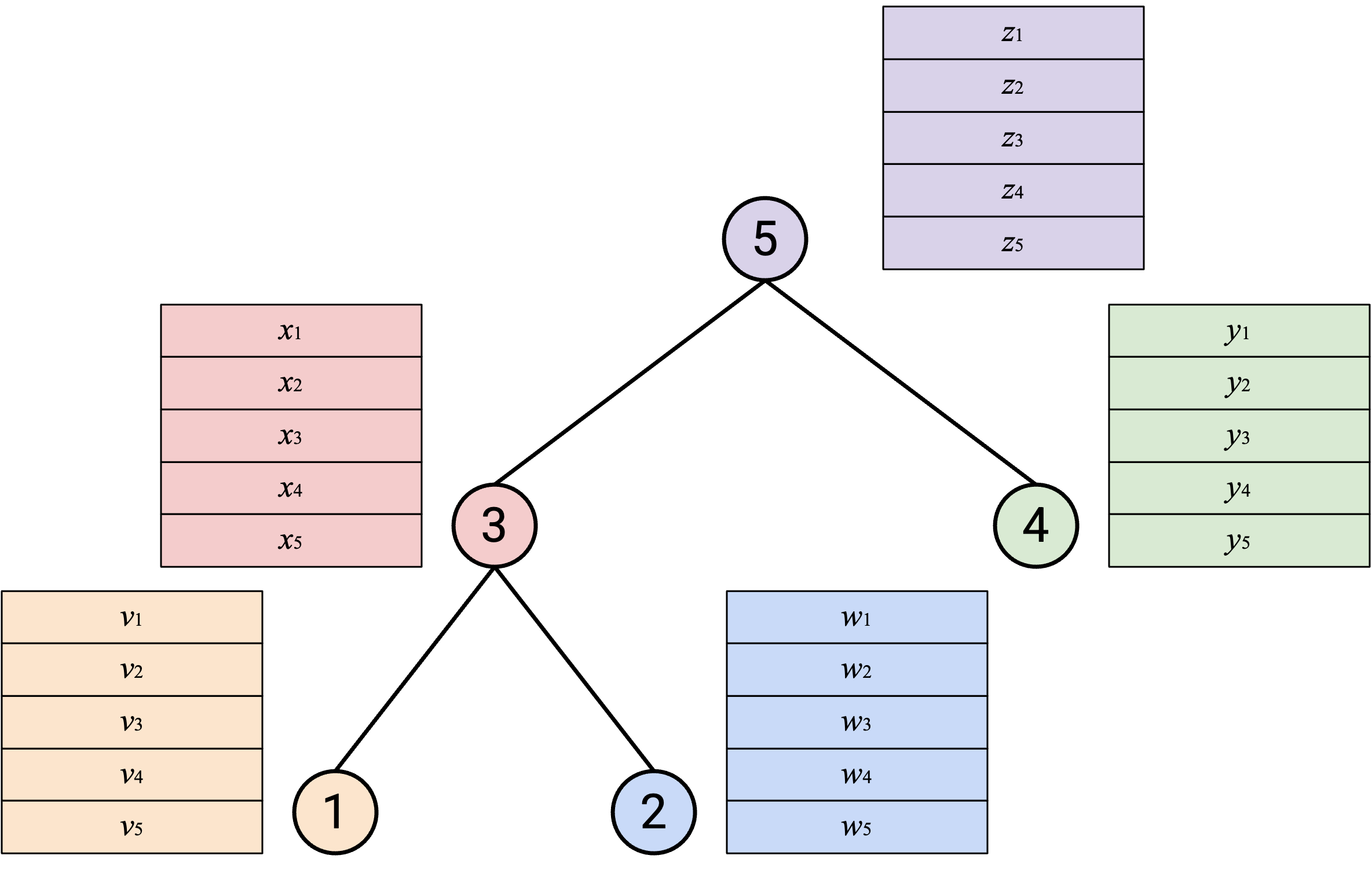
运行 AllReduce:从底部 leaf node 开始,每个 node 把自己的 vector 发送给 parent。
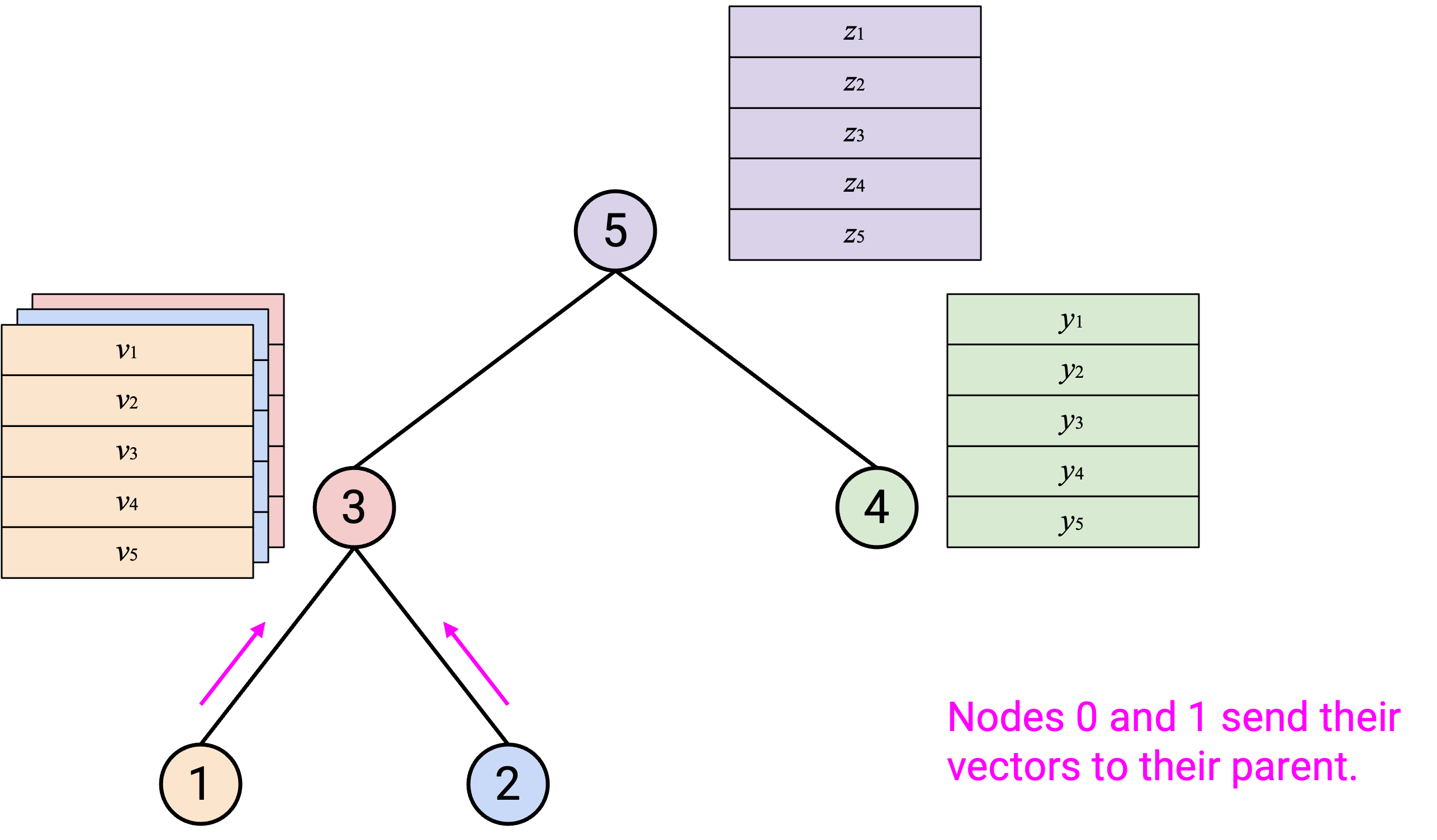
当你收到所有 child 的 vector 后,应该把它们和自己的 vector 求和。
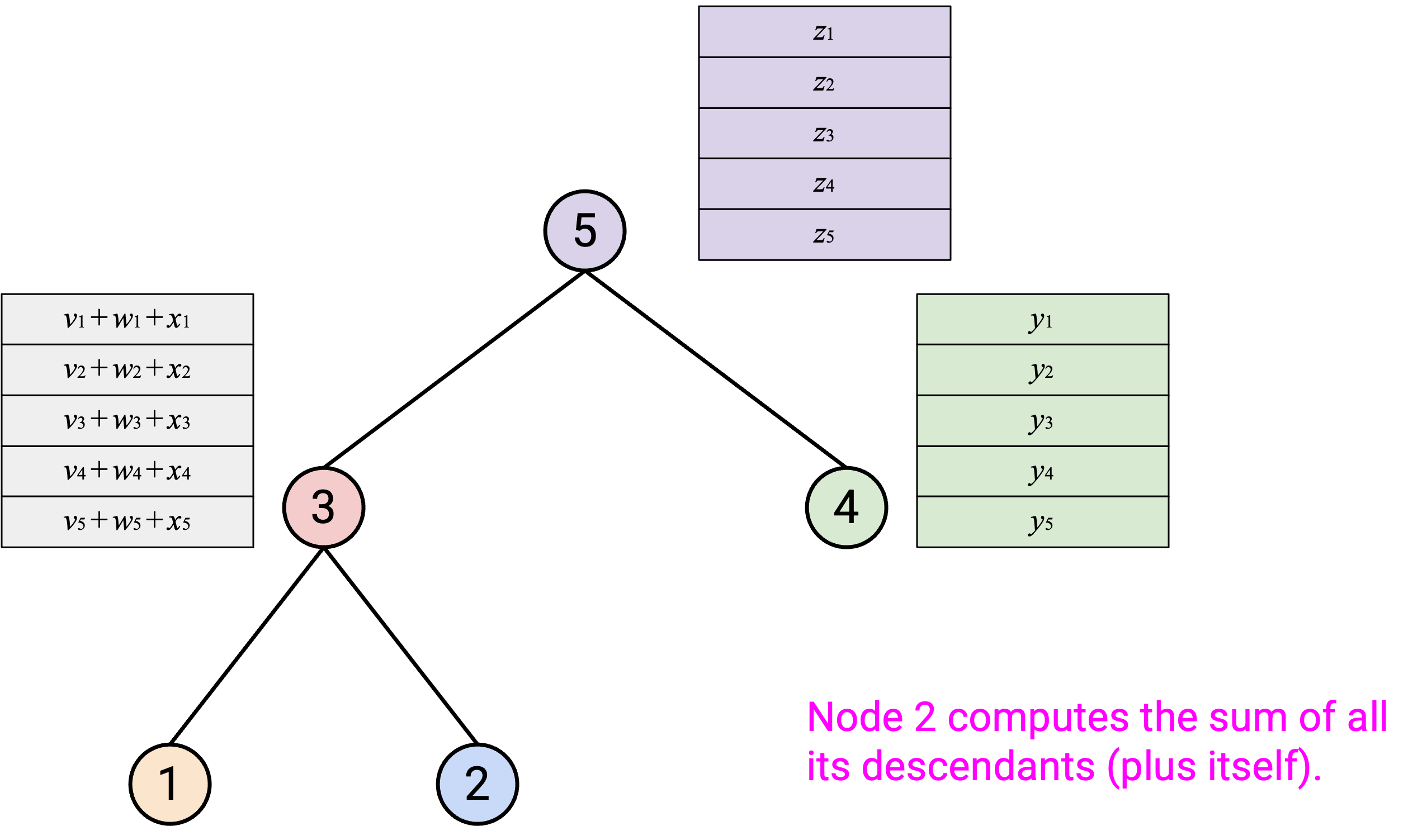
然后,你应该把得到的 sum vector 发送给 parent。
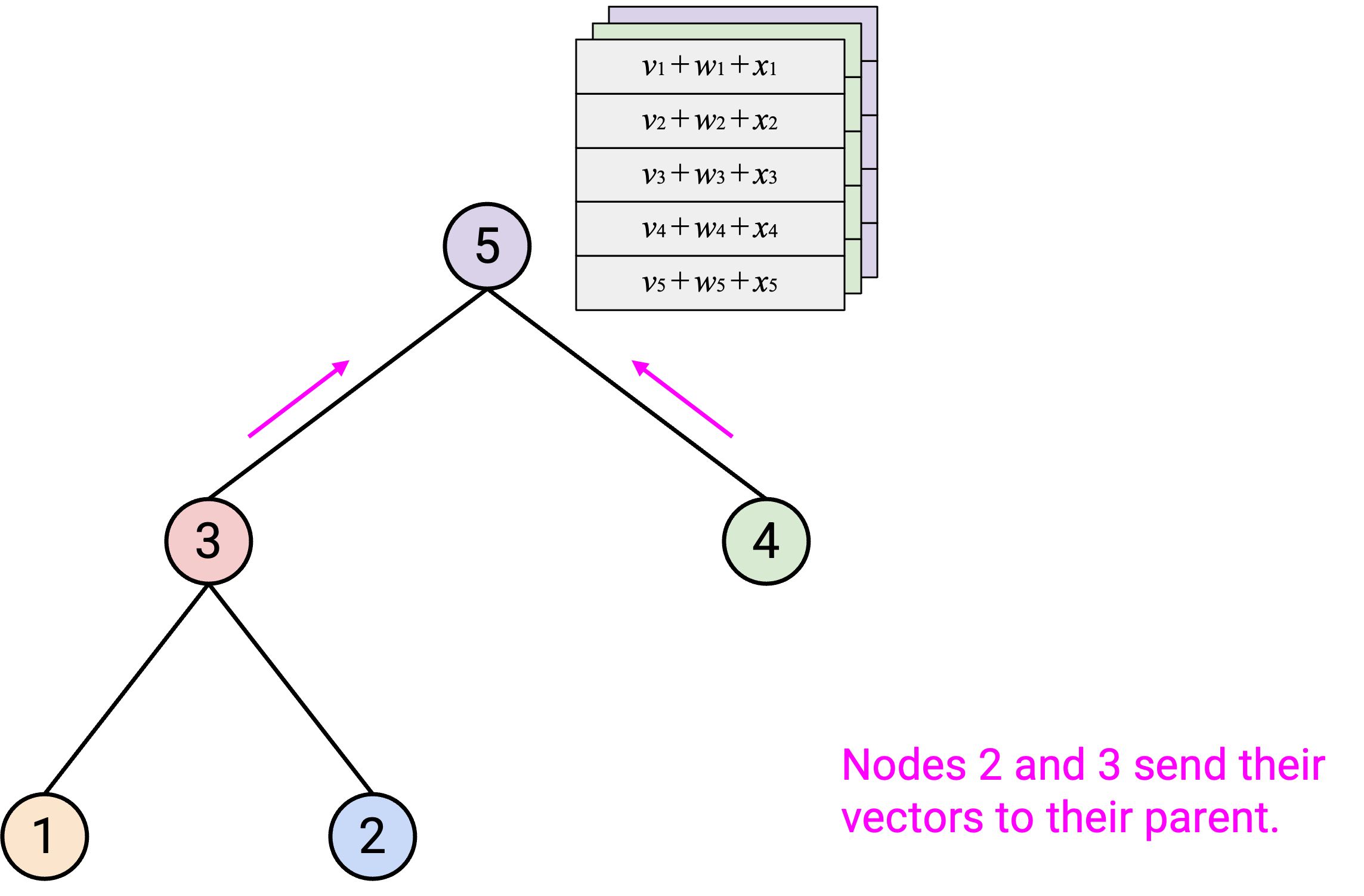
沿着 tree 的所有 layer 重复这个步骤后,root 应该已经计算出了 overall sum。
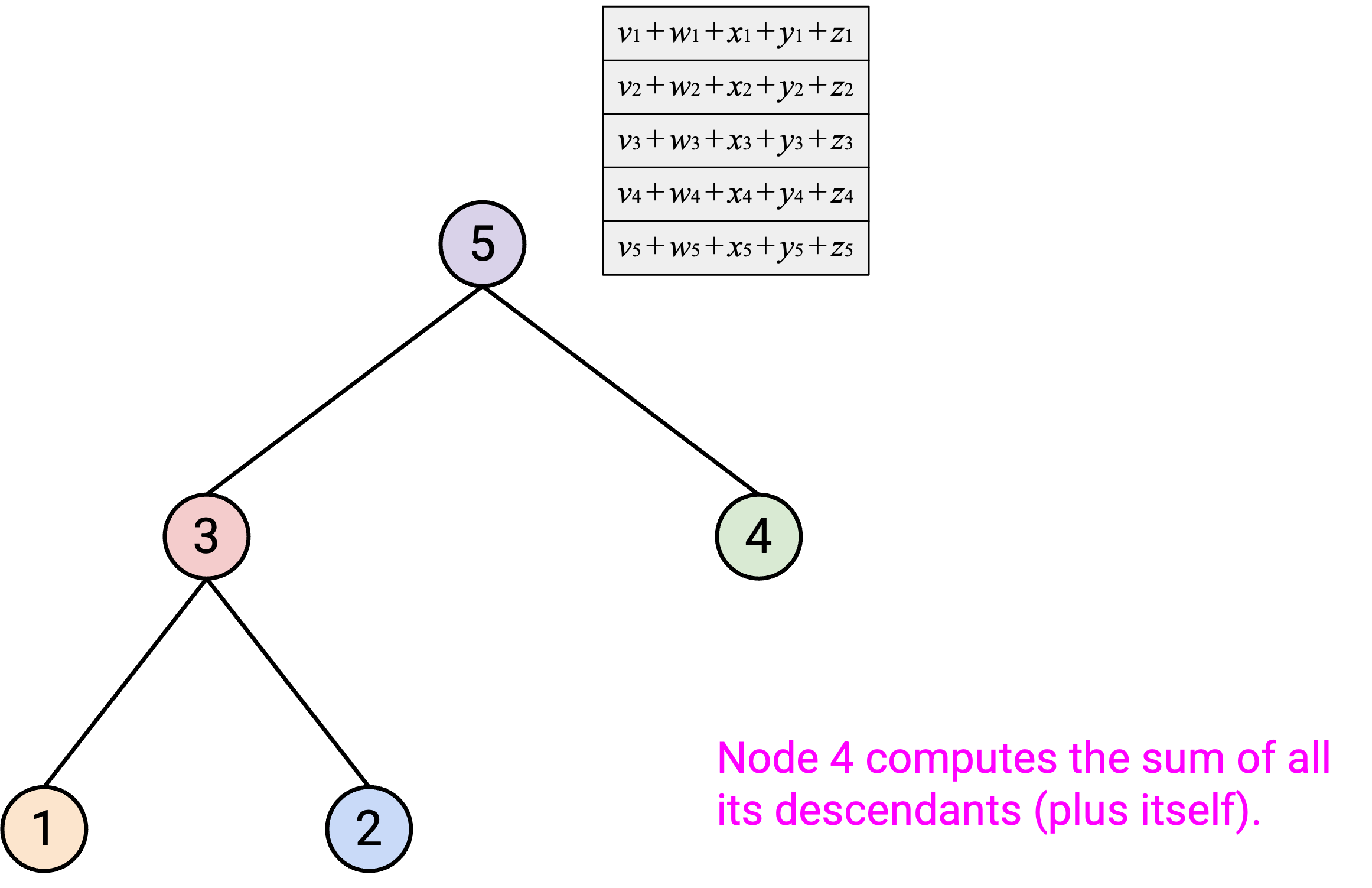
然后,在第二步中,root 把 overall sum vector 沿 tree 向下发送给自己的 child。当你从 parent 收到 sum vector 后,应该把这个 sum vector 的副本发送给所有 child。
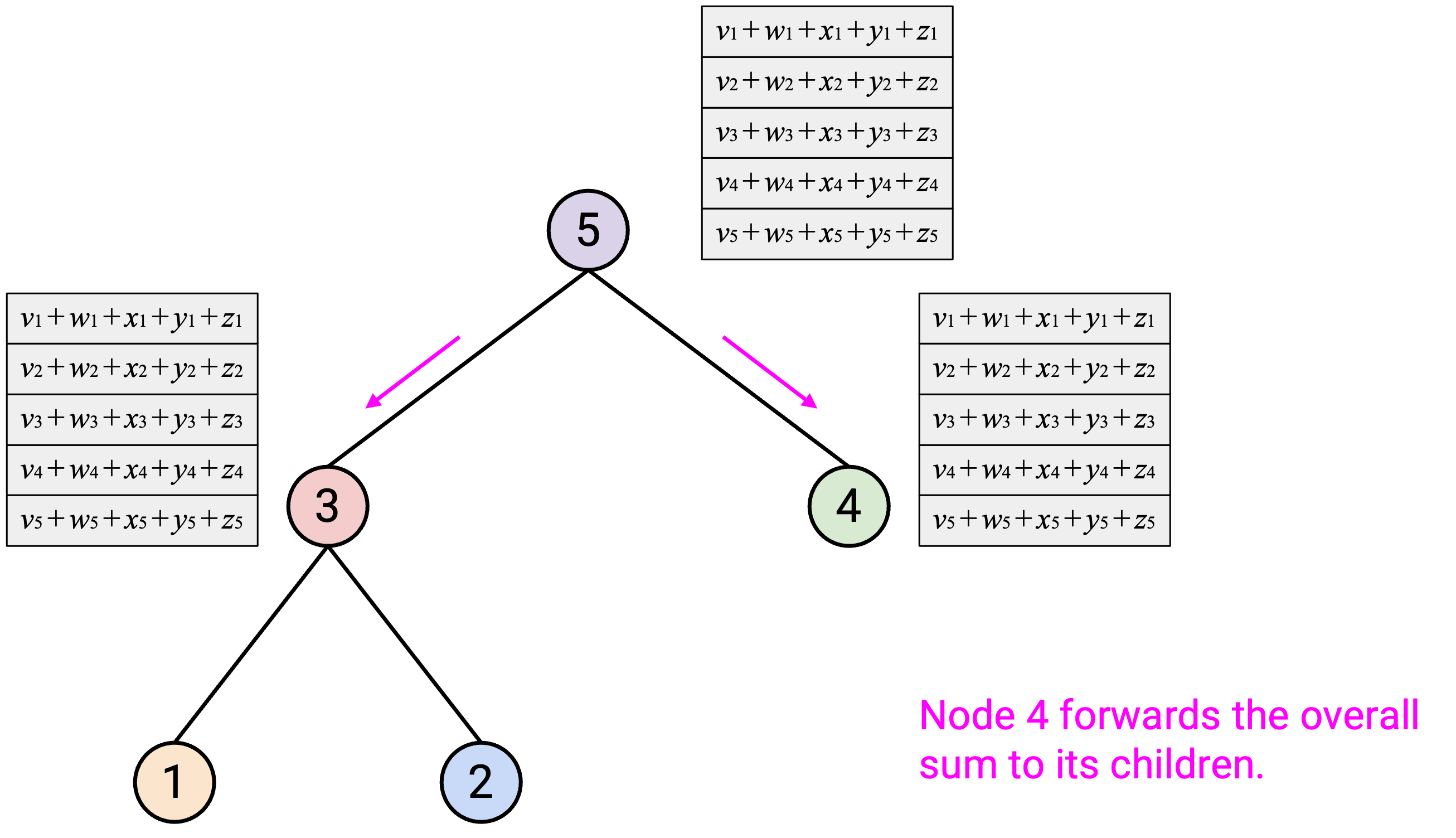
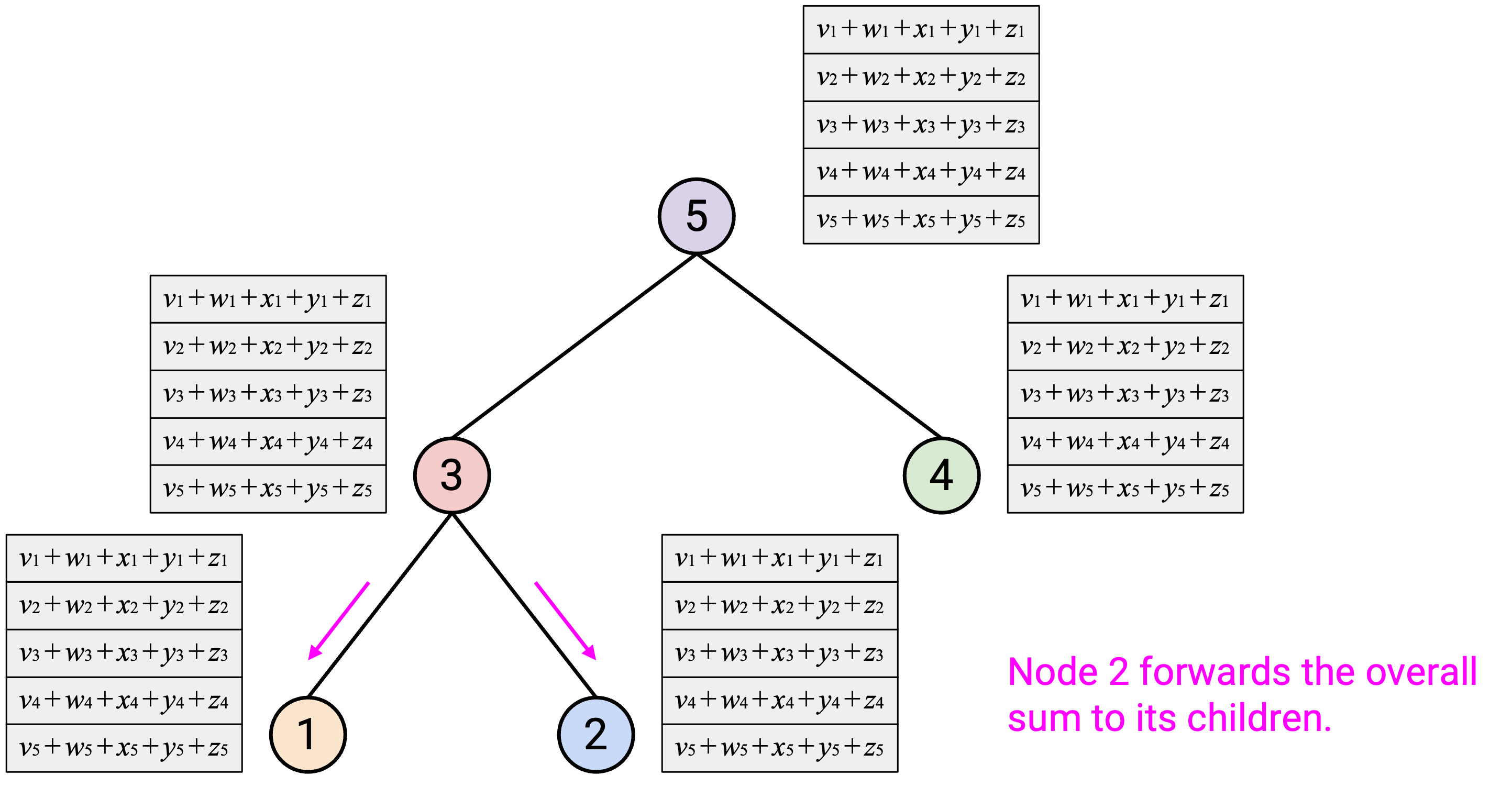
这种方法使用多少 bandwidth?在 Step 1 中,每个 node 最多从 child 接收 2 个 vector(回忆一下:tree 是 binary 的),并向 parent 发送 1 个 vector。这给出每个 node \(3D\) bytes 的 upper-bound,因此 Step 1 总共是 \(3D \cdot p\) bytes。
然后在第二步中,每个 node 从 parent 接收 1 个 vector,并最多向 child 发送 2 个 vector。同样,我们得到每个 node \(3D\) bytes 的 upper-bound,因此 Step 2 总共是 \(3D \cdot p\) bytes。
两步合计,我们发送了 \(6 \cdot D \cdot p = O(D \cdot p)\) bytes。这比 full-mesh 好 \(p\) 倍,并且和 reduce-at-one-node 方法相同。
这种方法需要多少时间?你必须先等待从 child 收到 vector,然后才能把 sum(也就是你自己的 vector 和 child 的 vector 之和)发送给 parent。总计,这种方法需要 \(O(\log p)\) 个 time step 把 vector 沿 tree 向上发送,再需要 \(O(\log p)\) 个 time step 把 overall sum 沿 tree 向下发送,总共是 \(O(\log p)\) 个 time step。每个 node 在每个 time step 必须发送或接收 \(3D\) bytes(注意,这比其他方法每个 time step 的 bytes 更少)。精确的时间比较需要代入 \(D\) 和 network 中的 resource limit;但粗略地说,这种方法需要更多 time step,不过每个 time step 可能完成得更快,因为每个 time step 要传输的 data 更少。
注意,在这个实现中,我们利用了 reduction operation。每个 node 会把自己的 vector 和 child 的 vector 求和,因此只需要向 parent 发送一个 sum vector。在更 naive 的方法中,每个 node 会向 parent 发送 3 个 vector(自己的 vector 和两个 child 的 vector),但我们利用 reduction 节省了 bandwidth。
更一般地说,consolidation collective(Reduce、ReduceScatter、AllReduce)给了我们优化实现的机会。在 Reduce 和 ReduceScatter 中,接收到的 data 总量实际上少于发送的 data 总量,我们可以在实现中利用这一点。例如,如果知道 output 是所有 vector 的 sum,并且我们收到了两个 vector,就可以把这两个 vector 相加并转发单个 summed vector,而不是分别转发两个 vector。
方法 4:Ring-Based(Naive)¶
最后两种方法中,我们会构建一个 ring-shaped topology。注意,Node 1 到 Node 5 的 wrap-around link 和其他 link 没有什么特别之处(也就是说,这条 link 更长并不代表任何特殊含义)。
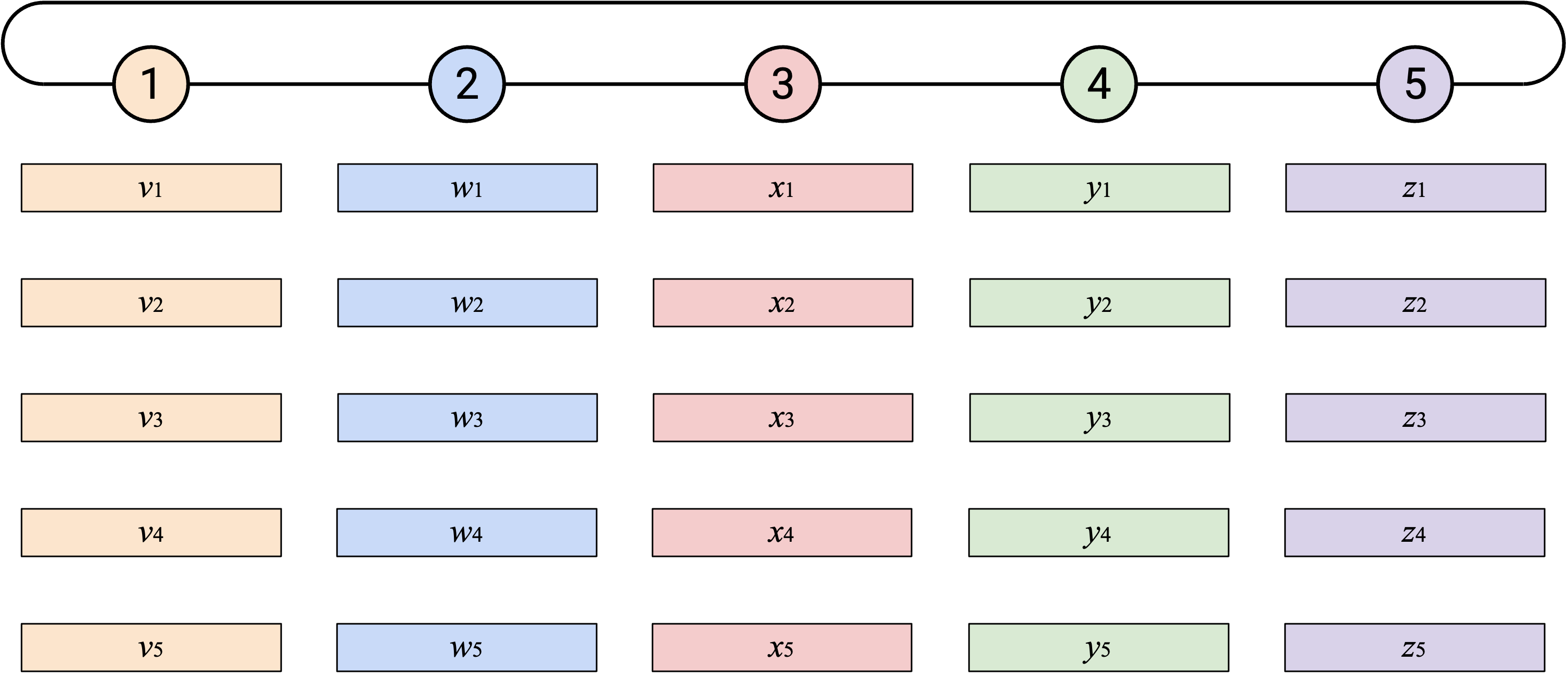
naive 地运行 AllReduce:Node 5 首先把自己的 vector 向左发送。
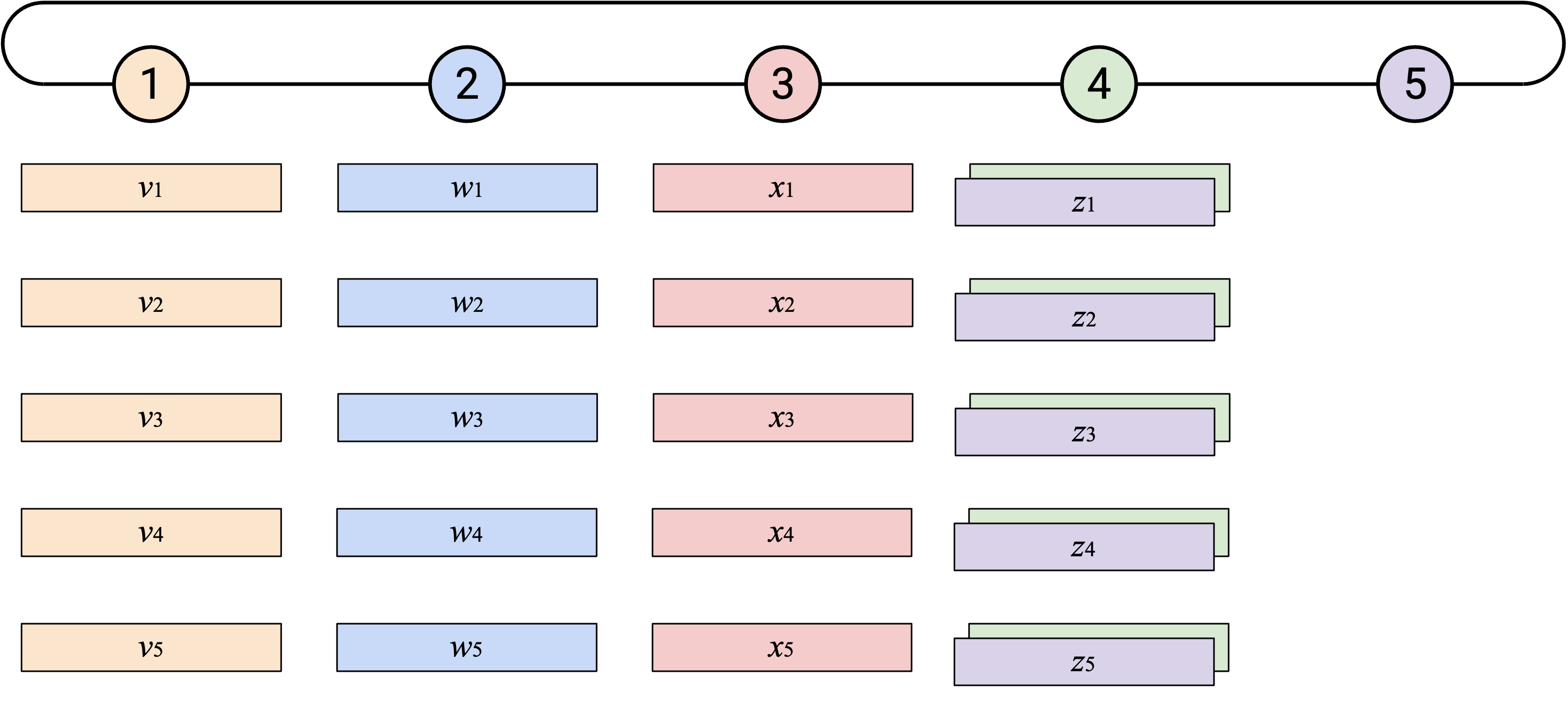
当你从右侧 neighbor 收到一个 vector 时,应该把它和自己的 vector 求和。
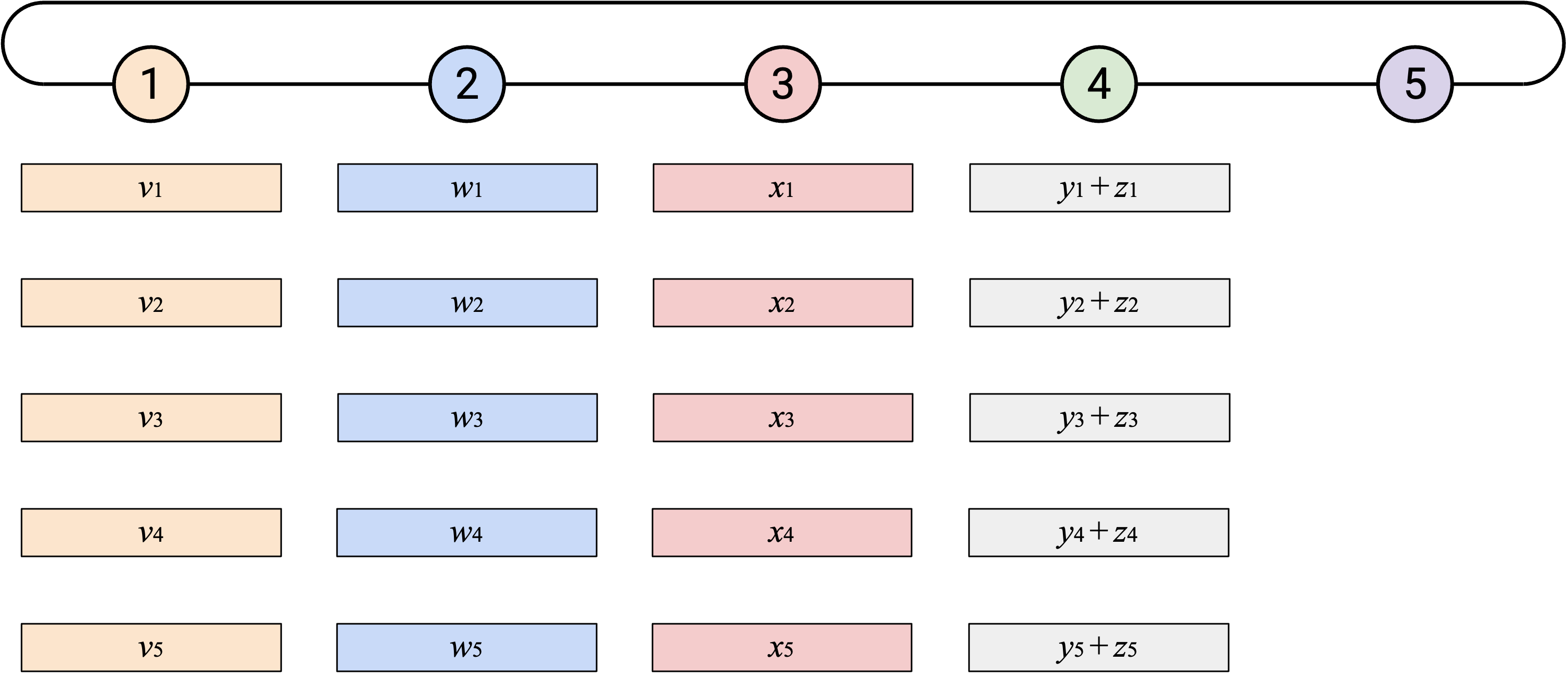
然后,你应该把得到的 sum vector 发送给左侧 neighbor。
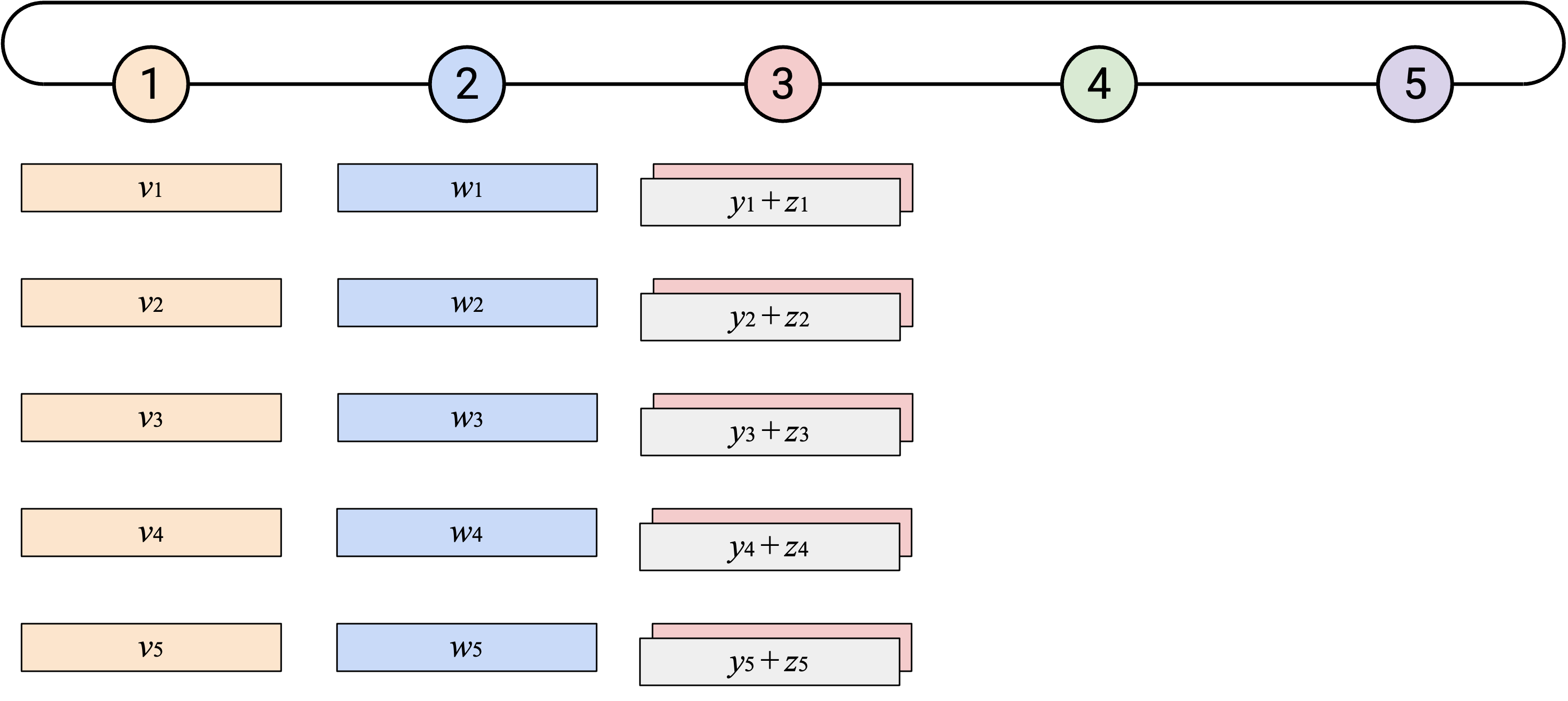
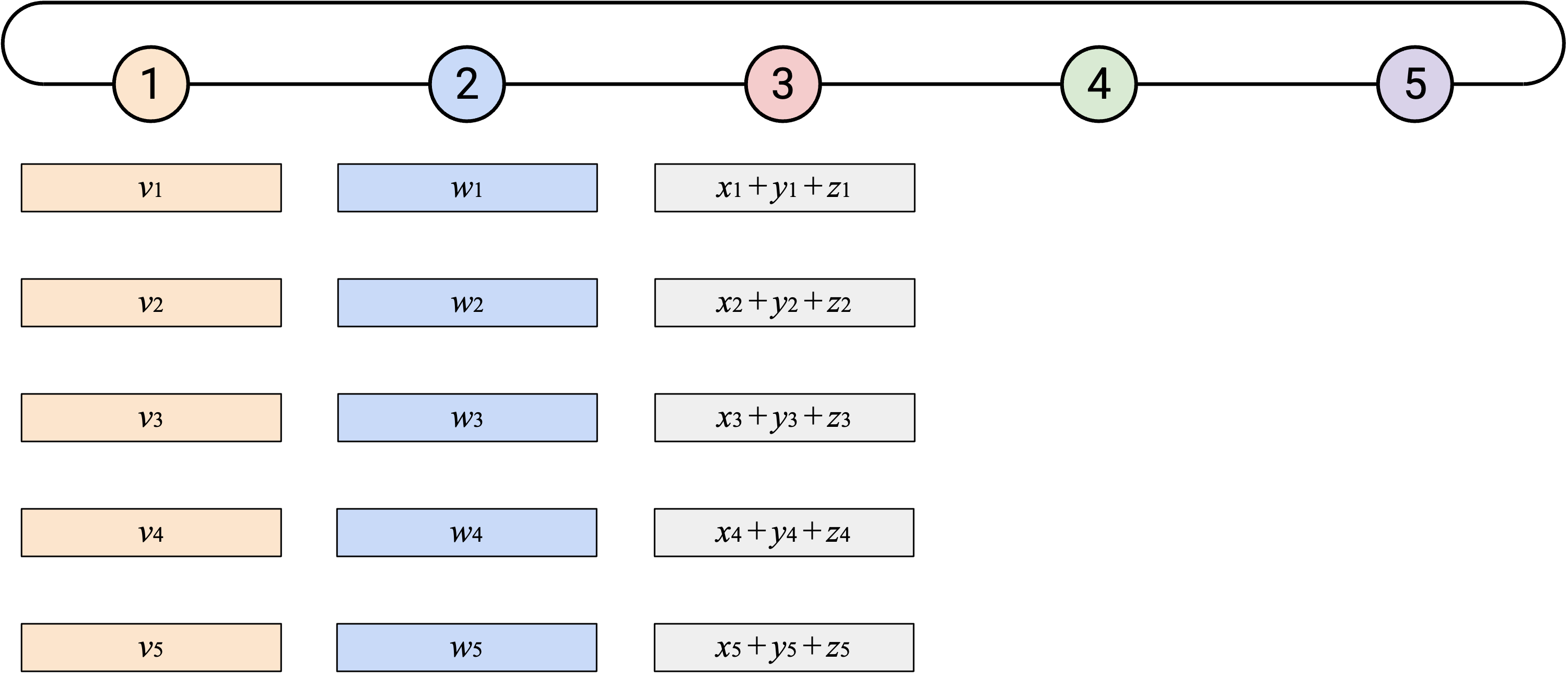
最终,这个过程会绕完整个 loop。
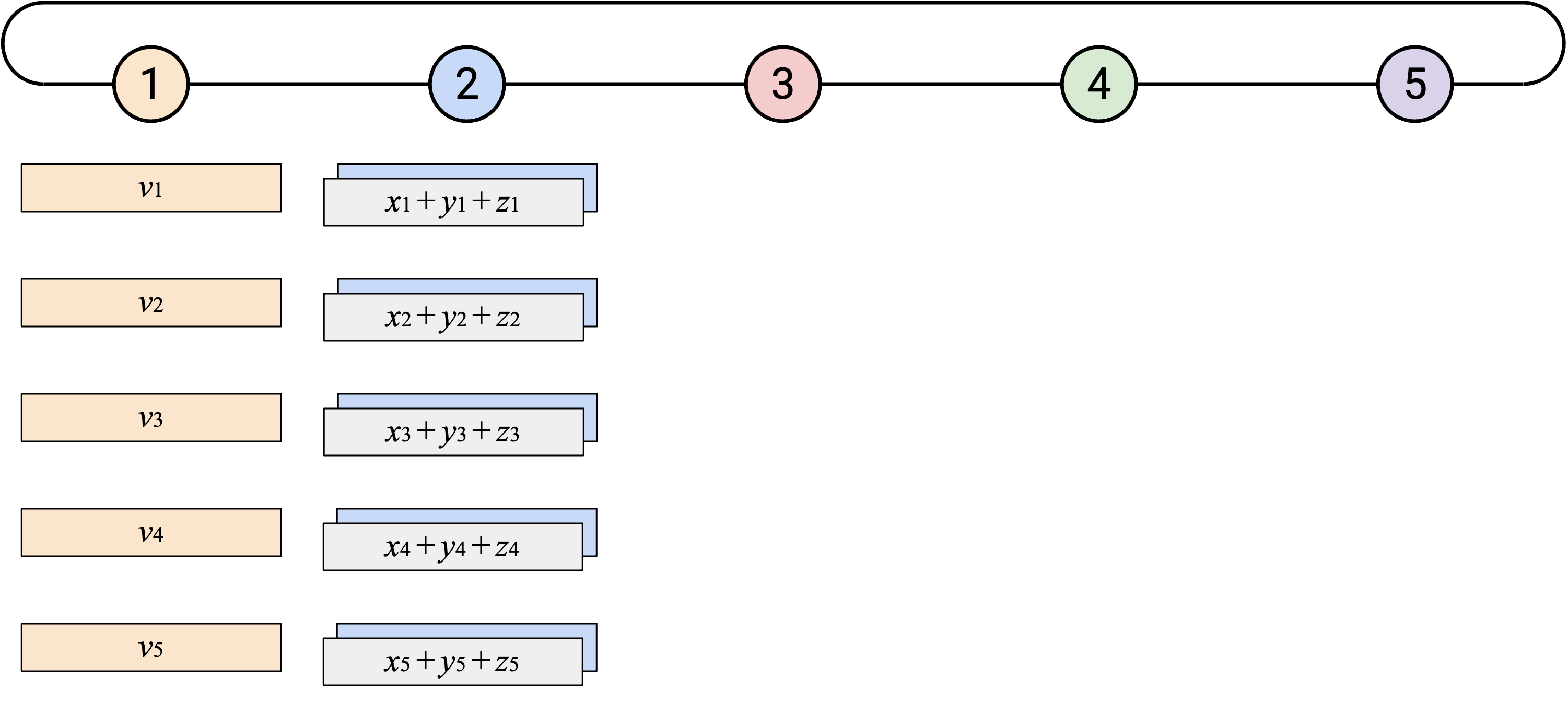

为了完成第一步,Node 1 会计算 overall sum。
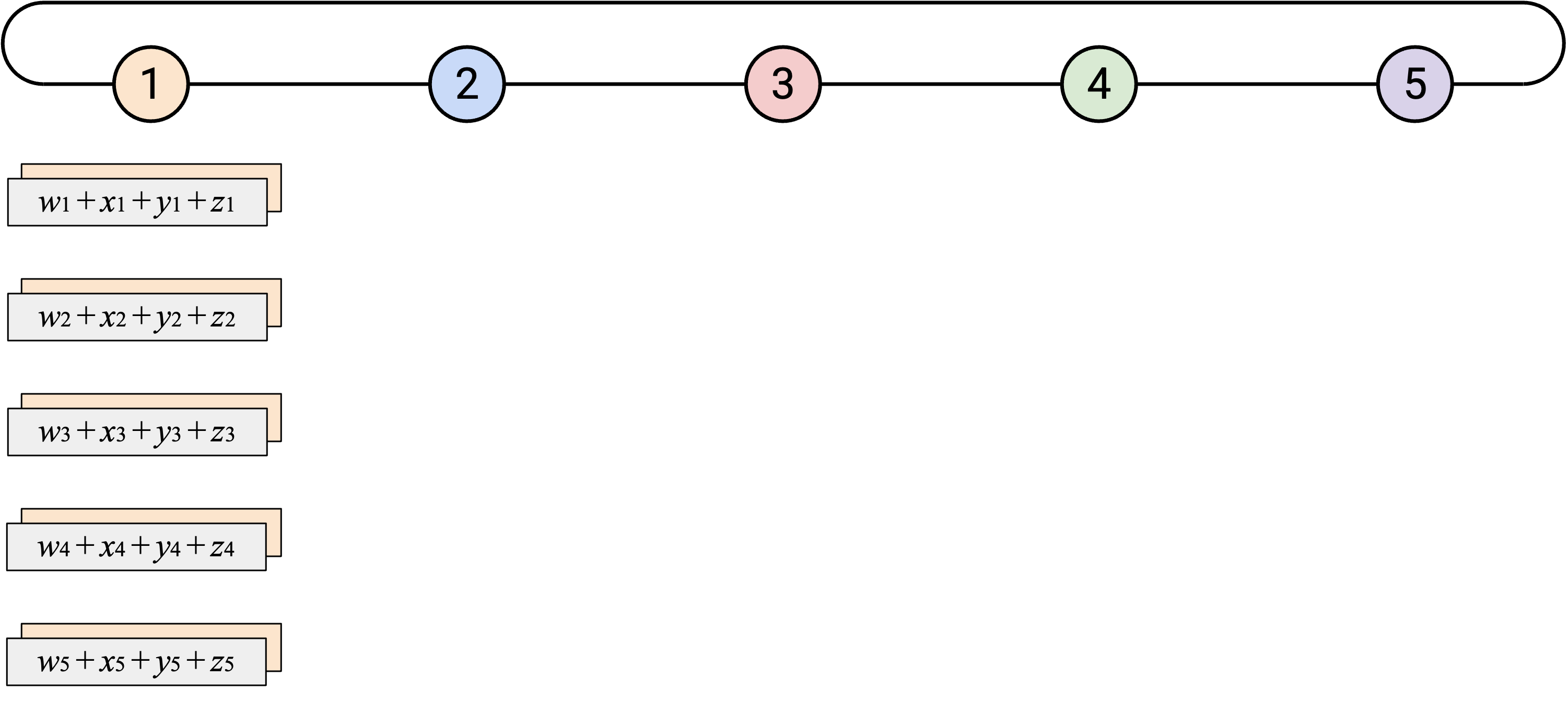
然后,在第二步中,我们会把 overall sum 沿着 loop 发送一圈,让每个人都有一份 copy。Node 5 首先把 overall sum 向左发送。当你从右侧 neighbor 收到 overall sum vector 时,应该把 sum vector 的副本发送给左侧 neighbor。最终,这个过程会绕完整个 loop,所有人都会收到 overall sum 的副本。

这种方法使用多少 bandwidth?在 Step 1 中,每个 node 从右侧 neighbor 接收一个 vector,并向左侧 neighbor 发送一个 vector。这给出每个 node \(2D\) bytes 的 upper-bound,因此 Step 1 总共是 \(2D \cdot p\) bytes。
在第二步中,每个 node 同样接收 1 个 vector 并发送 1 个 vector。同样,我们得到每个 node \(2D\) bytes 的 upper-bound,因此 Step 2 总共是 \(2D \cdot p\) bytes。
两步合计,我们发送了 \(4 \cdot D \cdot p = O(D \cdot p)\) bytes。
这种方法需要多少时间?你必须先接收一个 vector(来自左侧),才能发送一个 vector(到右侧)。总计,这种方法第一步需要 \(p\) 个 time step 绕 loop 一圈,第二步又需要 \(p\) 个 time step 把 overall sum 沿 loop 发送一圈,总共是 \(2p = O(p)\) 个 time step。每个 node 在每个 time step 最多必须发送或接收 \(2D\) bytes。
和 tree-based topology 一样,精确的时间比较需要代入 \(D\) 和 network 中的 resource limit。粗略地说,与前两种方法相比,这种方法需要更多 time step,但每个 time step 可能完成得更快,因为每个 time step 要传输的 data 更少。
注意:我们选择 Node 5 作为 starting point,但其他 starting point 也可以。同样,我们也可以在 loop 中从左到右移动,而不是从右到左。
方法 5:Ring-Based(Optimized)¶
目前看到的方法都能给出正确答案,但它们会产生 bursty workload。在 naive ring-based 方法中,每个 node 大部分时间都在 idle,什么也不做。在某个时刻,你突然收到一个完整 vector,必须立刻把这个 vector 加到自己的 vector 上,并把结果发送给左侧。其他所有人都必须等你完成这个 operation。
为了创建更不 bursty、更均衡的 workload,我们可以错开 naive ring-based AllReduce 的步骤。一次性把整个 vector 向左发送,会给左侧 neighbor 带来一阵突发 work。相反,你可以增量地向左发送 vector:每个 time step 发送一个 element。
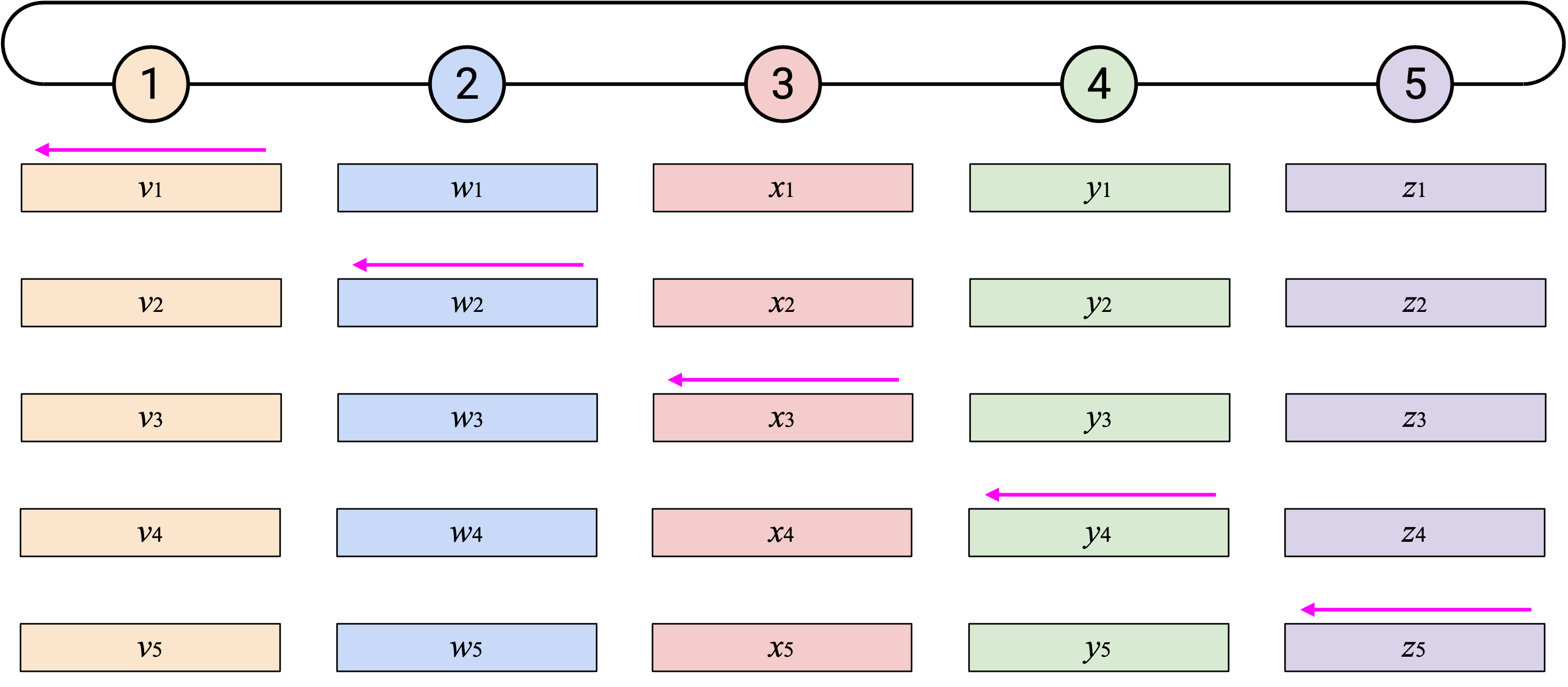
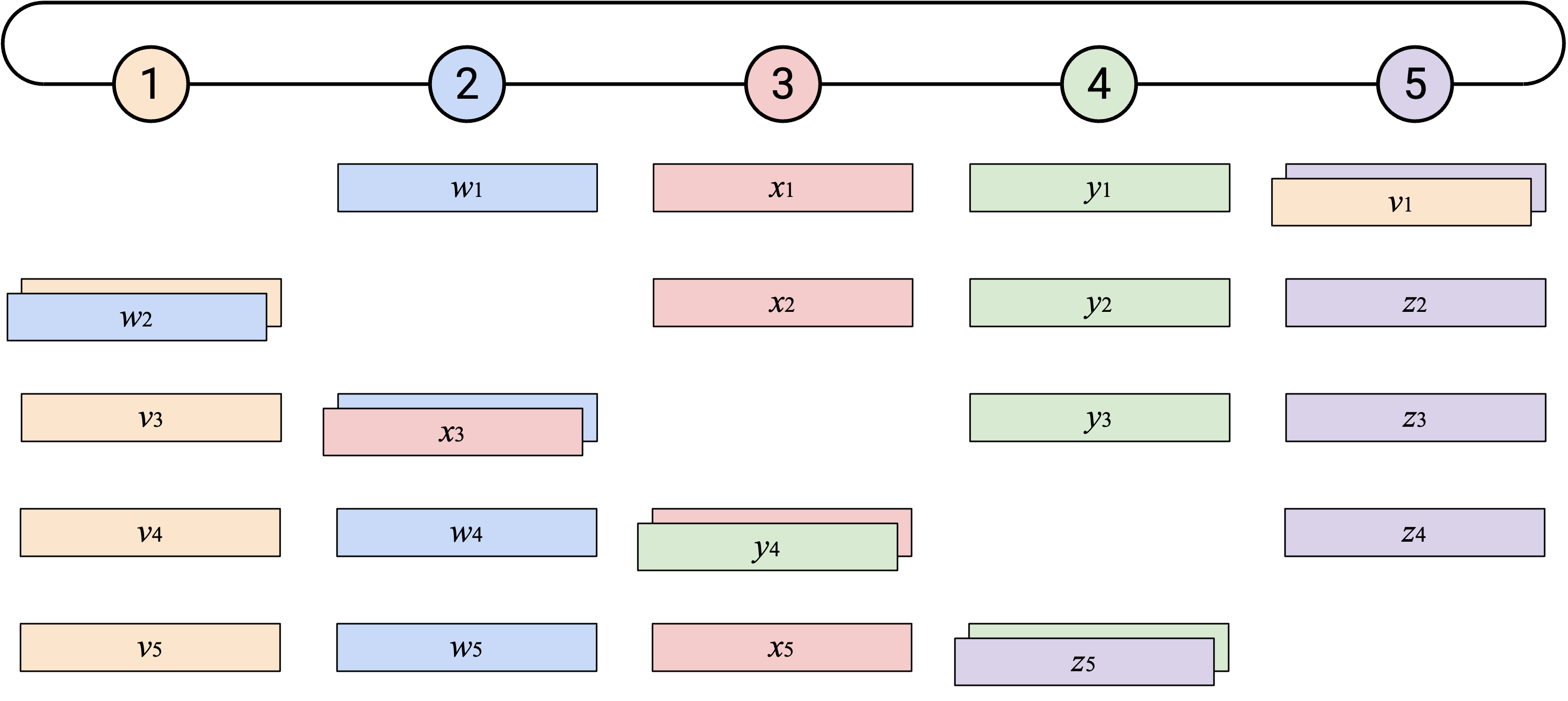
当你收到一个 single element(来自左侧)时,可以把这个 element 加到自己对应的 element 上。然后,你可以把得到的 sum(仍然是一个 single element)向左发送。
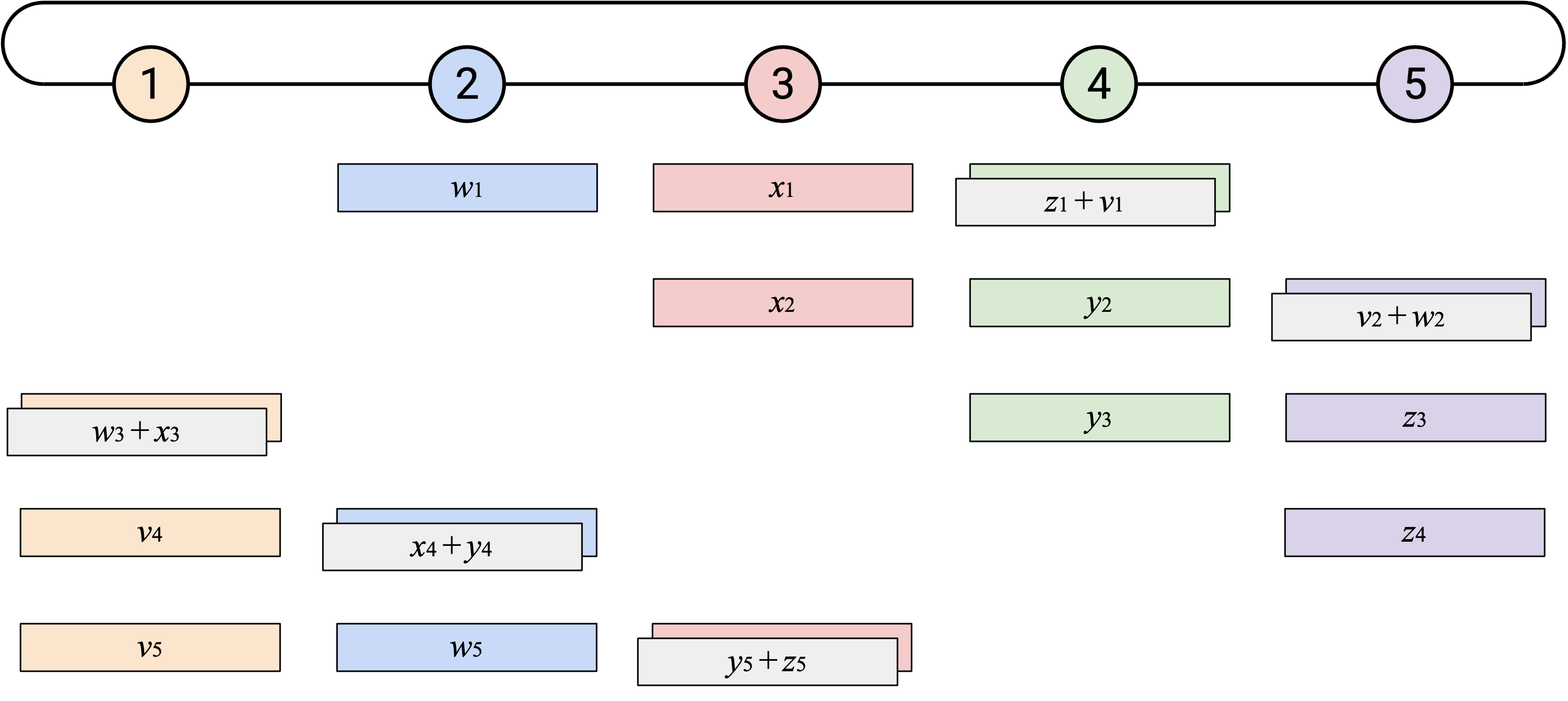
除了错开每个 vector 的发送,注意 starting point 也被错开了。之前的 starting point 是 Node 5 发送它的所有 element;现在改为让第 \(i\) 个 node 先发送自己的第 \(i\) 个 element。
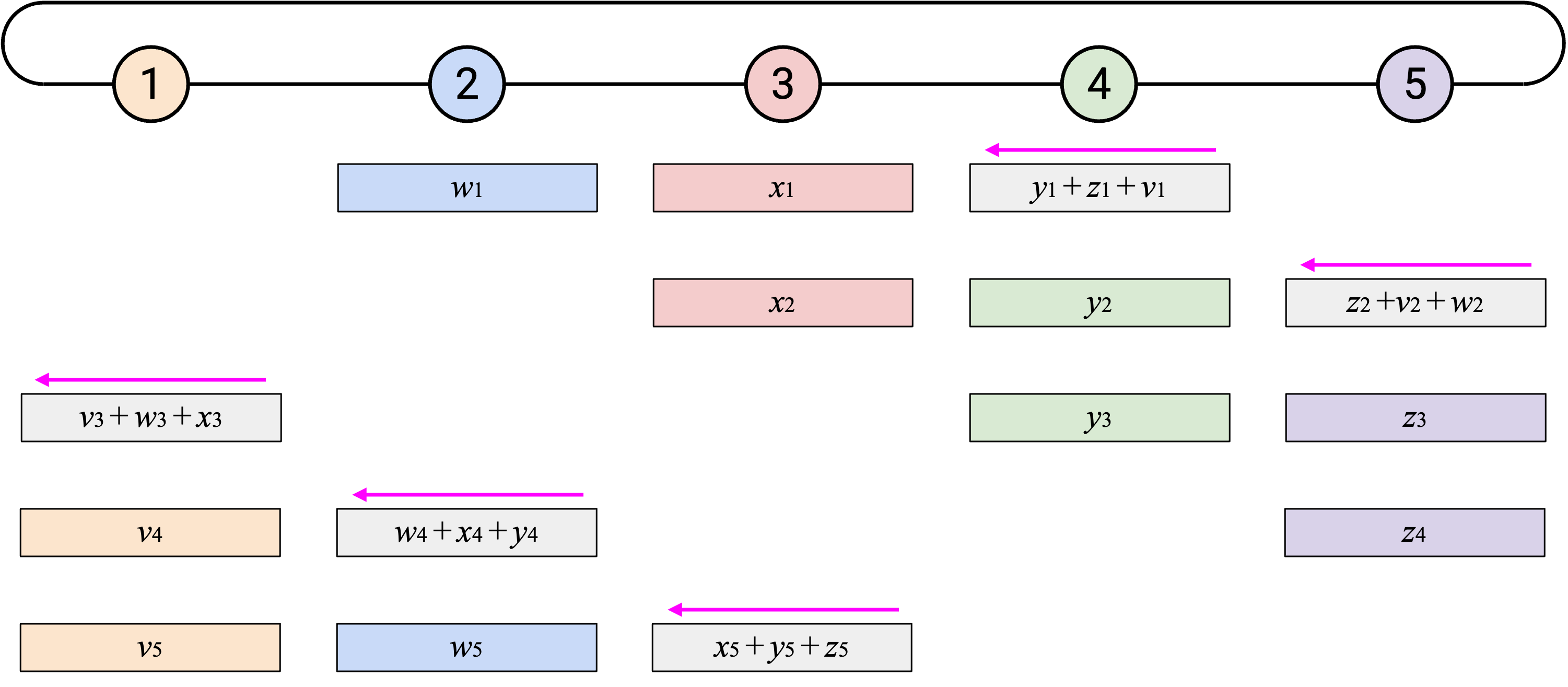
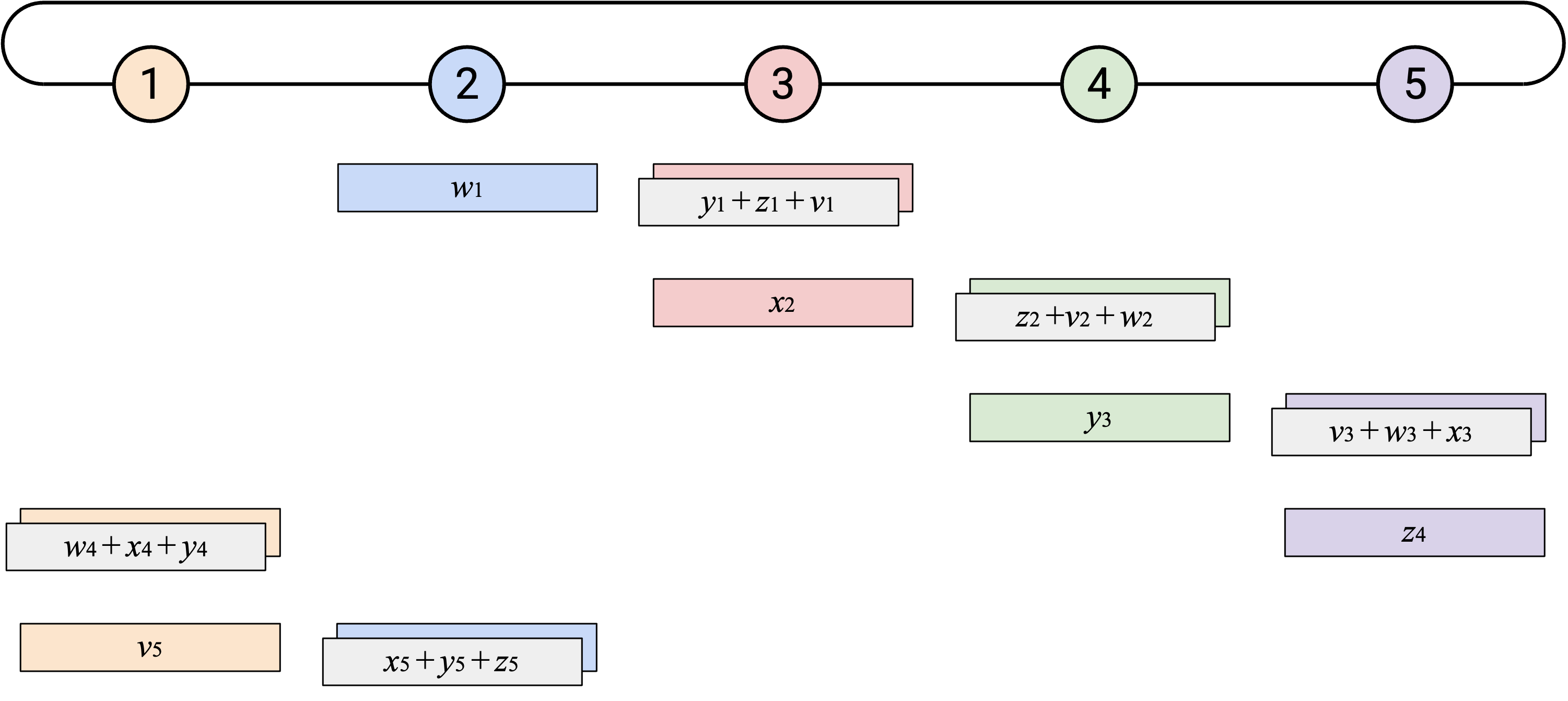
通过沿这两个维度错开 operation(每个 node 一次发送一个 element,并且每个 node 从不同 element 开始),我们可以创建更均衡的 workload。在每个 time step,每个 node 都会从右侧收到恰好一个 element,计算一次 sum,并向左侧发送恰好一个 element。
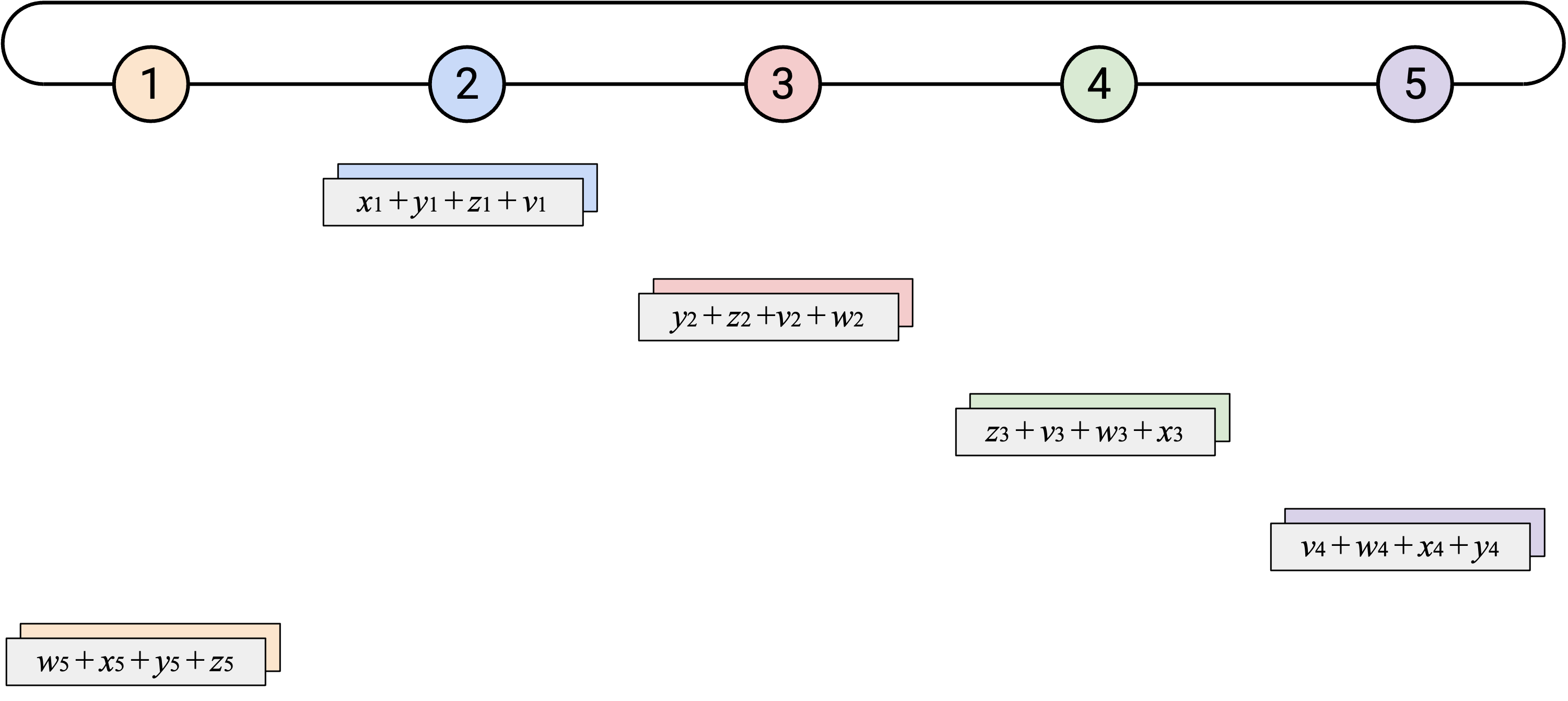
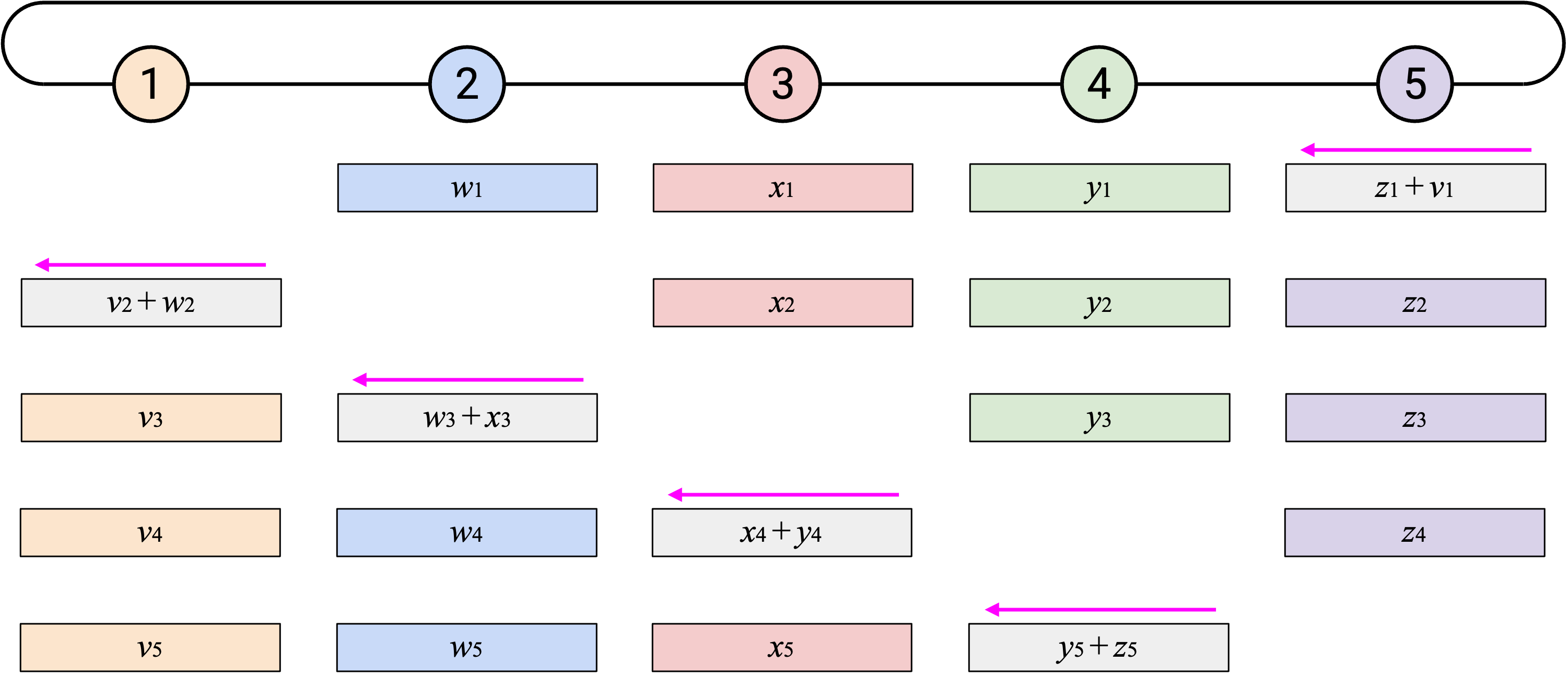
如果重复这个过程 \(p\) 次,那么每个 element 都会绕 ring 走完整整一圈。
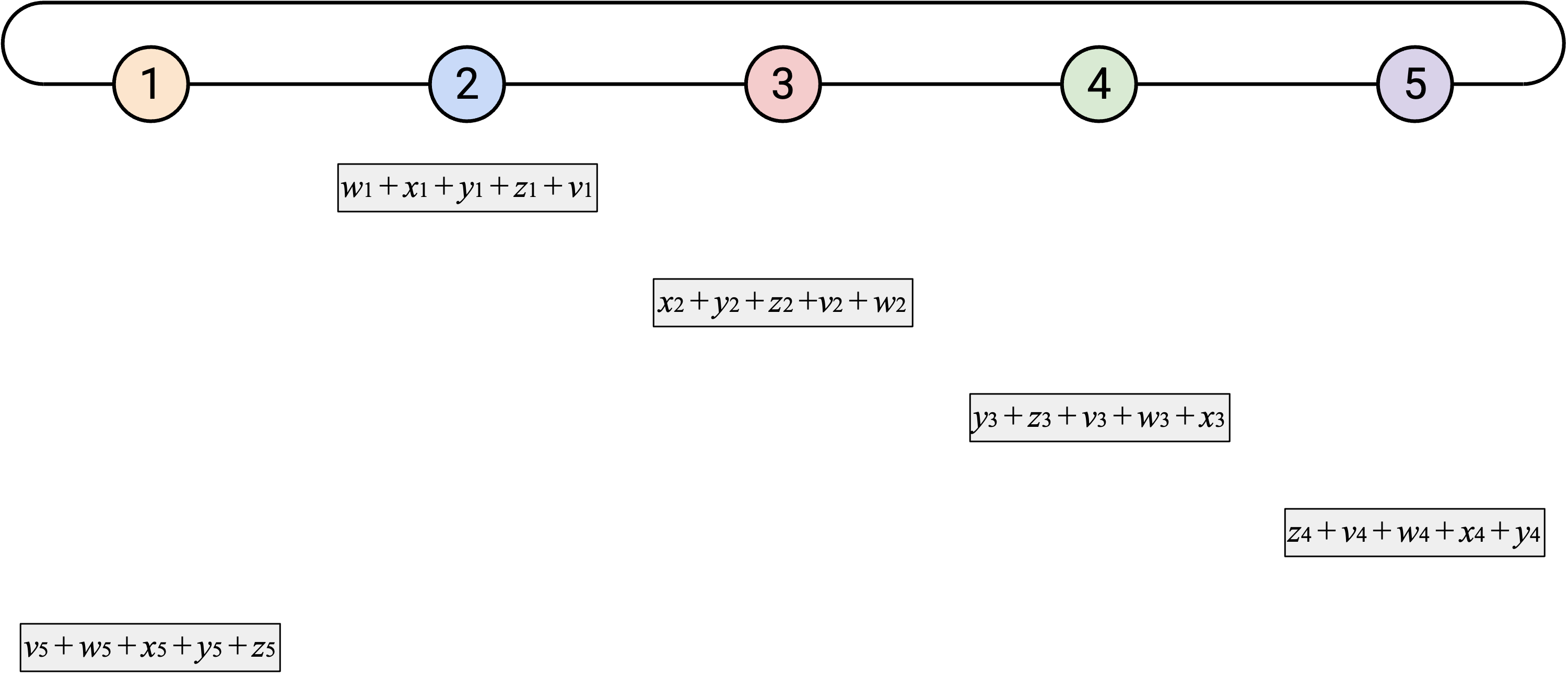
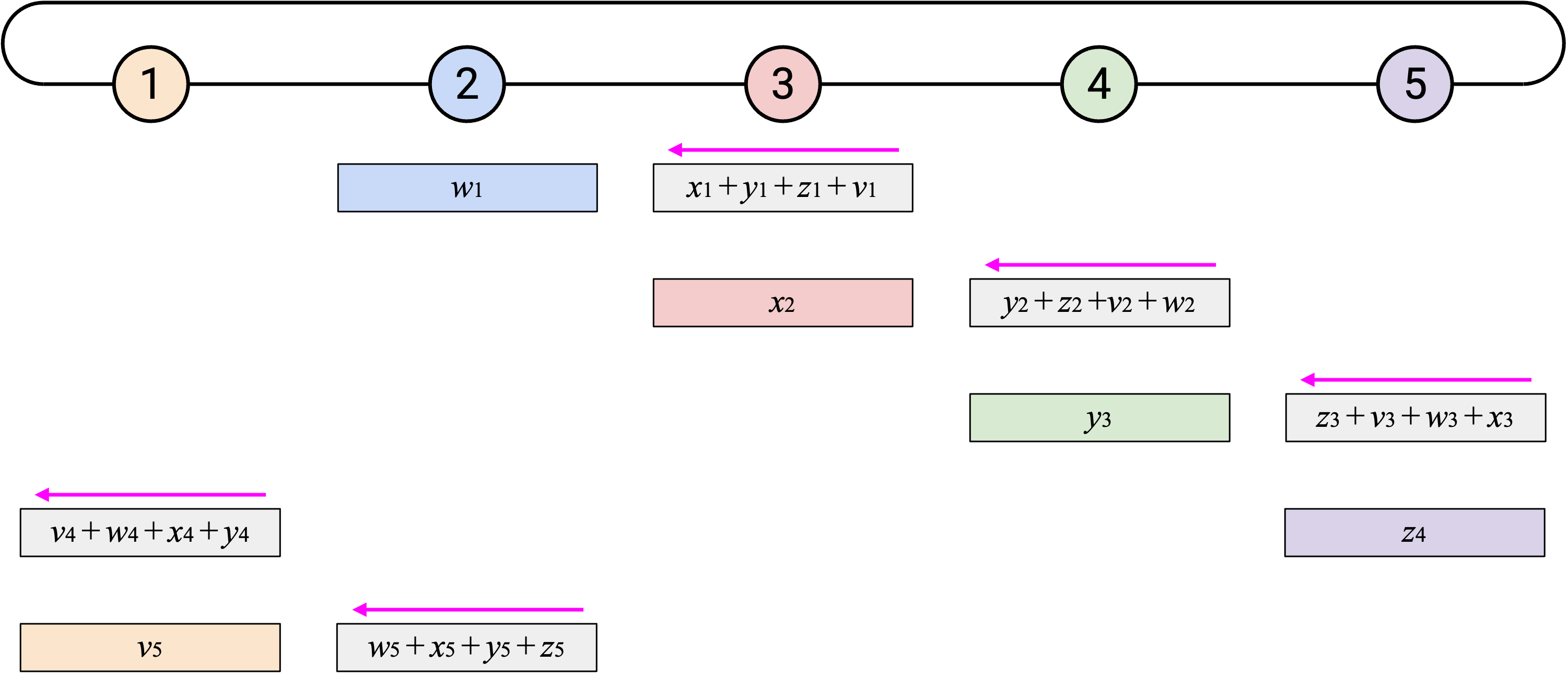
然而,并不是每个人都知道 sum vector 的所有 element,所以我们必须再绕 ring 一圈。就像 naive 方法一样,在第二圈中,当你收到 overall sum 的某个 element 时,只需要把它的副本发送给右侧。
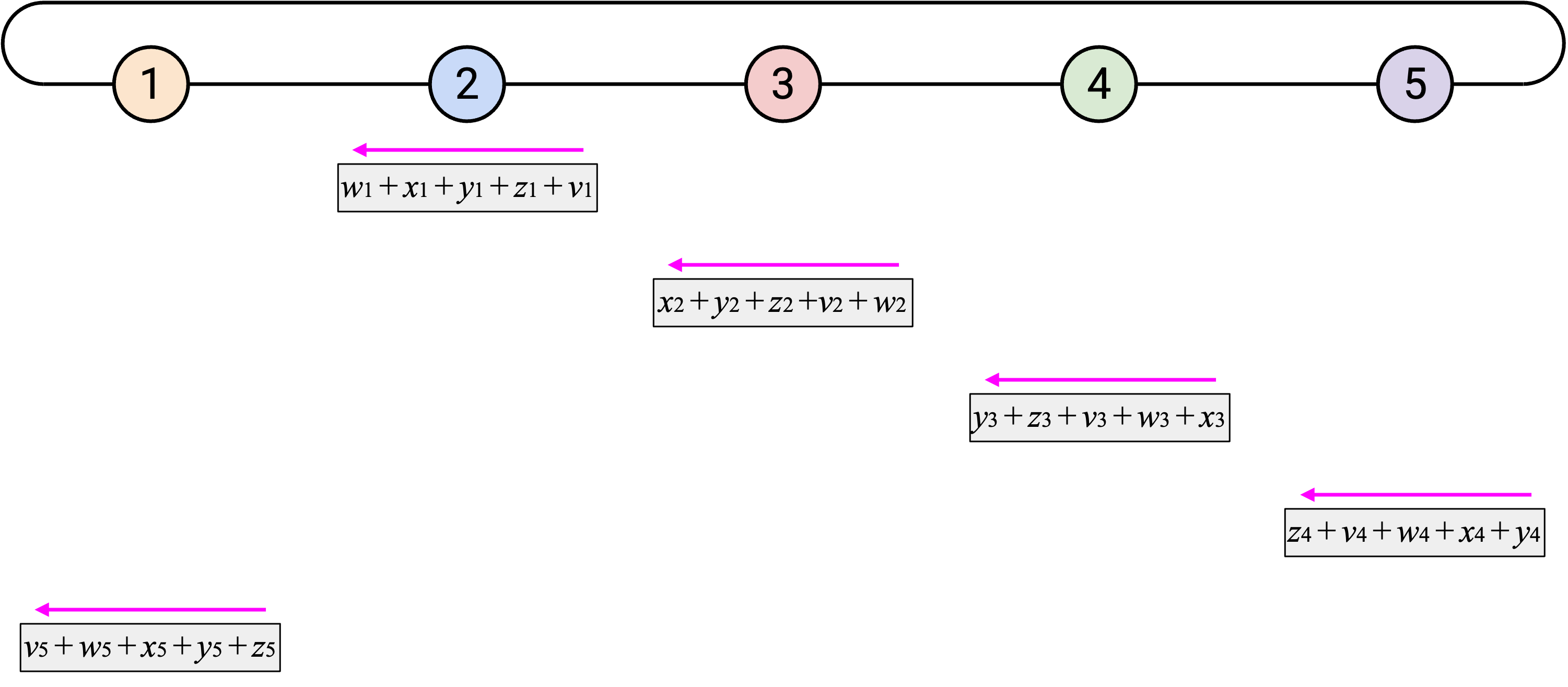
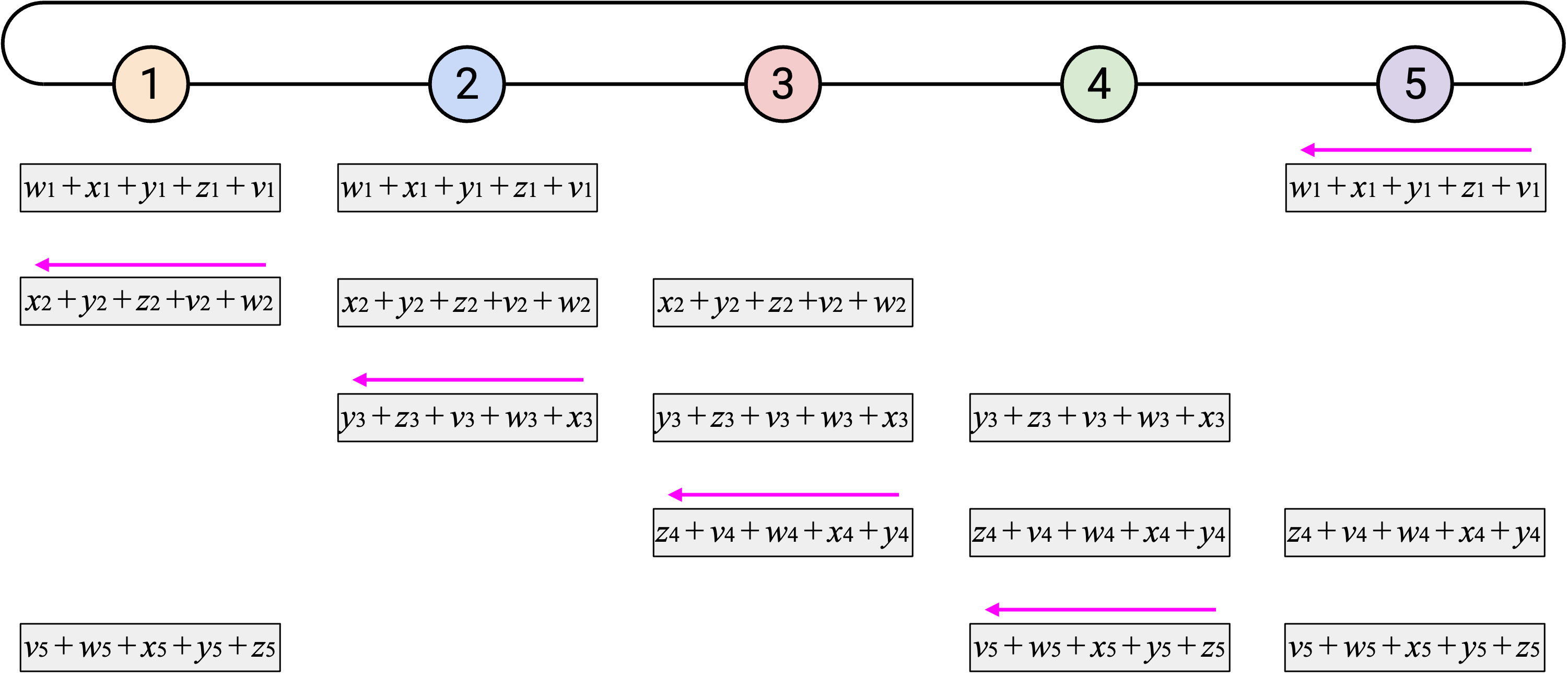
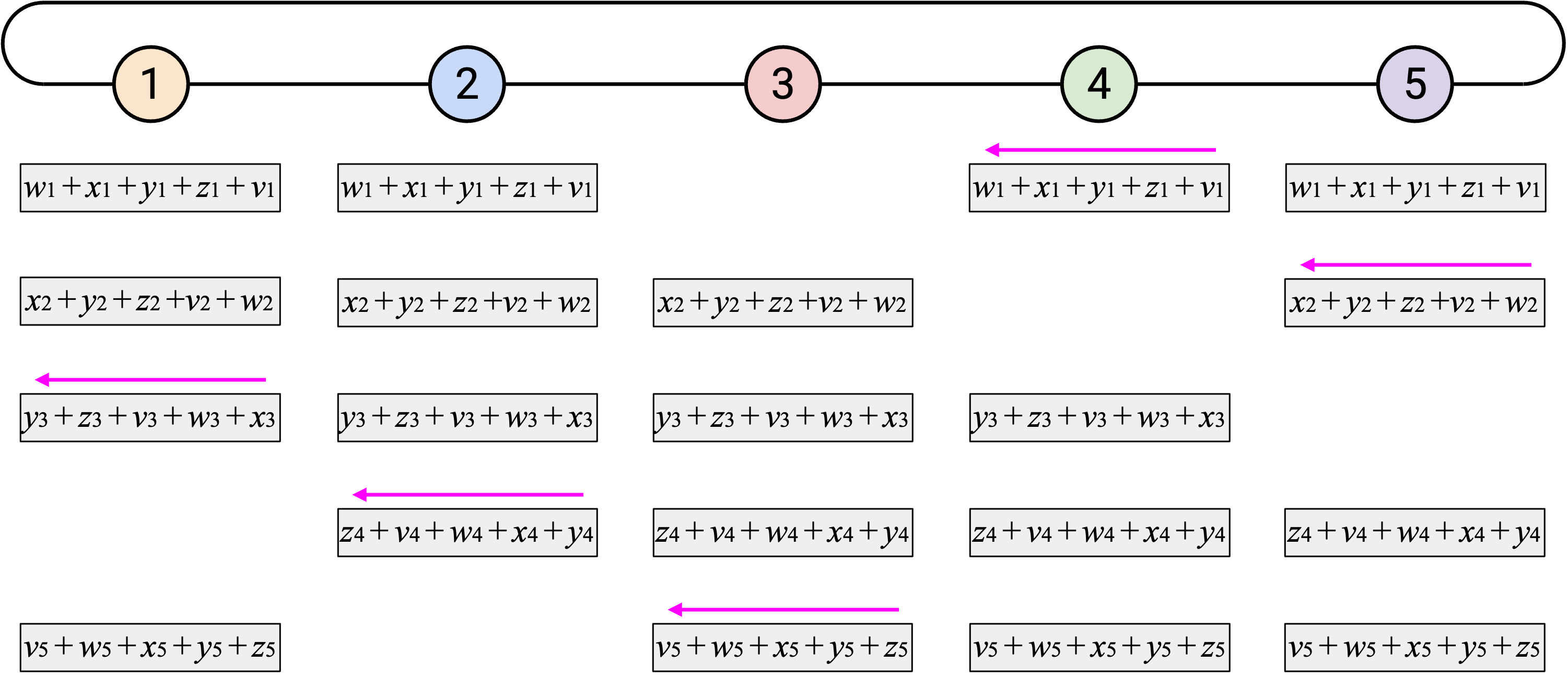
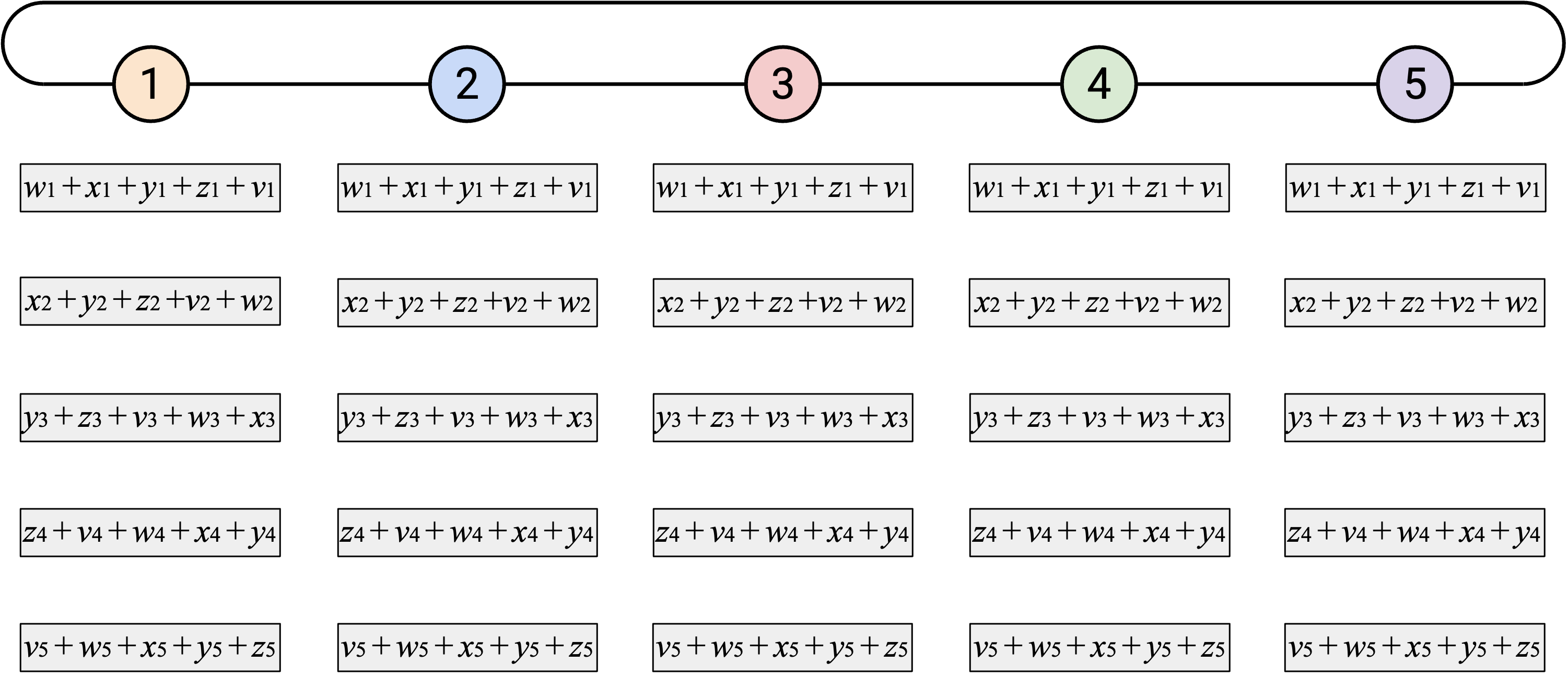
观看这个 animated demo 时,可以关注我们在哪两个维度上错开 operation。如果你关注单独一列,会看到我们一次发送一个 element,也一次接收一个 element。
另外,如果你关注单独一行,会看到每个 node 收到目前为止所有第 \(i\) 个 element 的 sum,加入自己的第 \(i\) 个 element,然后把新的 sum 向左发送。由于这个 operation 会经过所有 node,所以我们知道最终会把所有第 \(i\) 个 element 加在一起。
总结一下,optimized ring-based AllReduce 执行的 operation 与 naive ring-based AllReduce 完全相同。唯一的区别是,我们错开了 vector 的发送和接收,以降低每个 node 上 workload 的 burstiness。
optimized ring-based AllReduce 的 bandwidth 和 time analysis 与 naive ring-based AllReduce 相同。每个 node 在第一步接收/发送 \(2D\) bytes,在第二步再接收/发送 \(2D\) bytes,总共是 \(4 \cdot D \cdot p = O(D \cdot p)\) bytes。我们仍然需要 \(O(p)\) 个 time step 来绕 ring 两圈。
不过,optimized 方法改善了每个 time step 的 bandwidth。在 naive 方法中,每个 node 必须在一个 time step 中接收并发送整个 vector,总共在单个 time step 传输 \(2D\) bytes。在 optimized 方法中,每个 node 在每个 time step 只需要接收并发送一个 single element,总共在单个 time step 传输 \(2D/p\) bytes。
Overlay and Underlay Topologies¶
回忆一下,这些 collective operation 的定义允许 user(也就是 AI training program)选择任意一组 \(p\) 个 host,并要求它们运行 AllReduce operation。当 user 选择 \(p\) 个 host 时,它们不太可能已经漂亮地连接成 ring topology。如果 host 本身没有物理连接成 ring topology,我们如何实现 ring-based AllReduce?
答案是使用 overlay。我们可以画出 virtual link,把 host 连接成 ring topology:
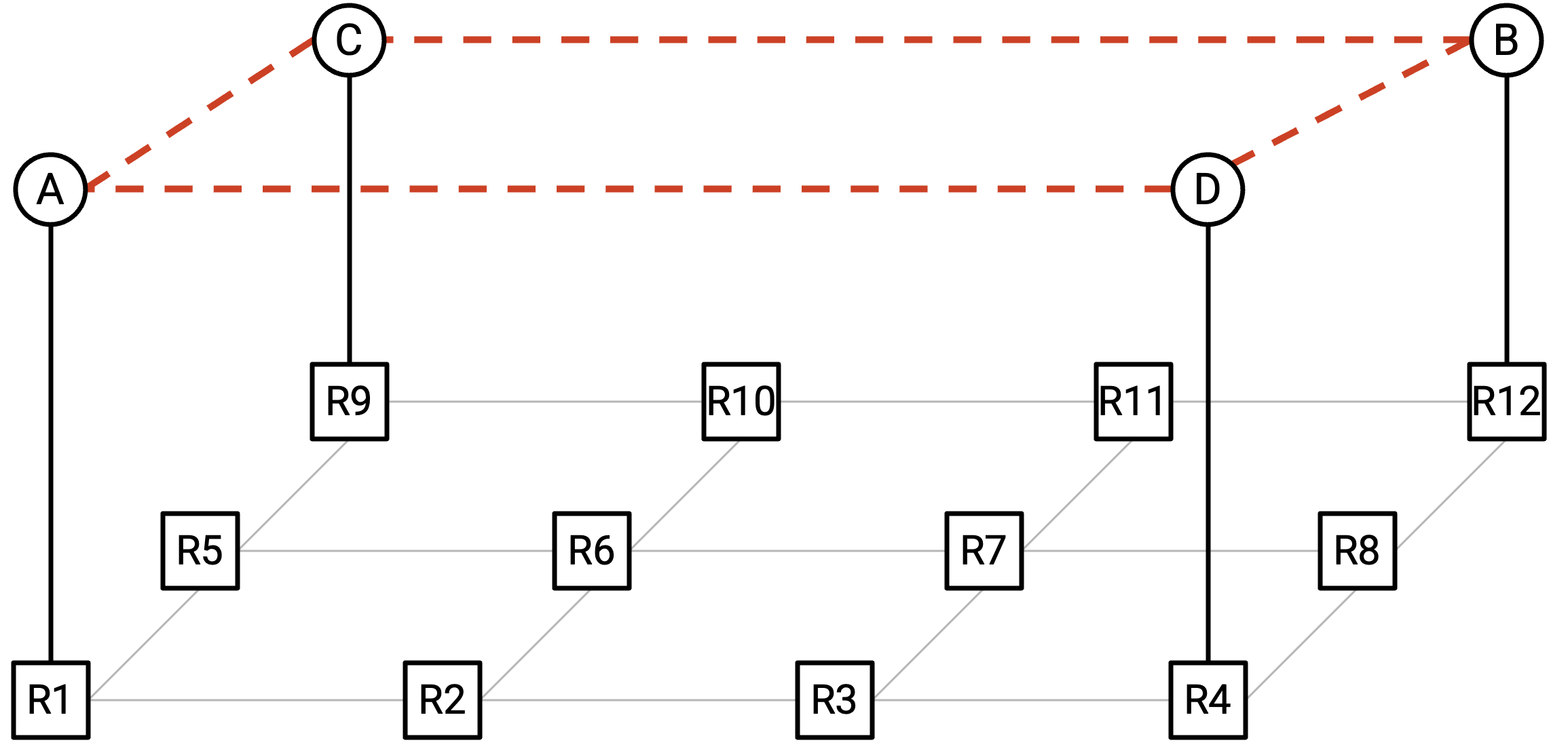
当 Node D 把自己的 vector 发送给 Node B 时,从 overlay 视角看,Node D 是沿着一条 single(virtual)link 把 vector 发送给自己的 direct neighbor。从 underlay 视角看,这个 vector 实际上必须经过 several hops 才能到达目的地 Node B。
正如讨论 overlay-based multicast 时看到的,overlay performance 取决于 overlay topology 与 underlay network 的匹配程度。在 AI training 的背景下,performance 尤其重要,因为我们正在传输海量 data。
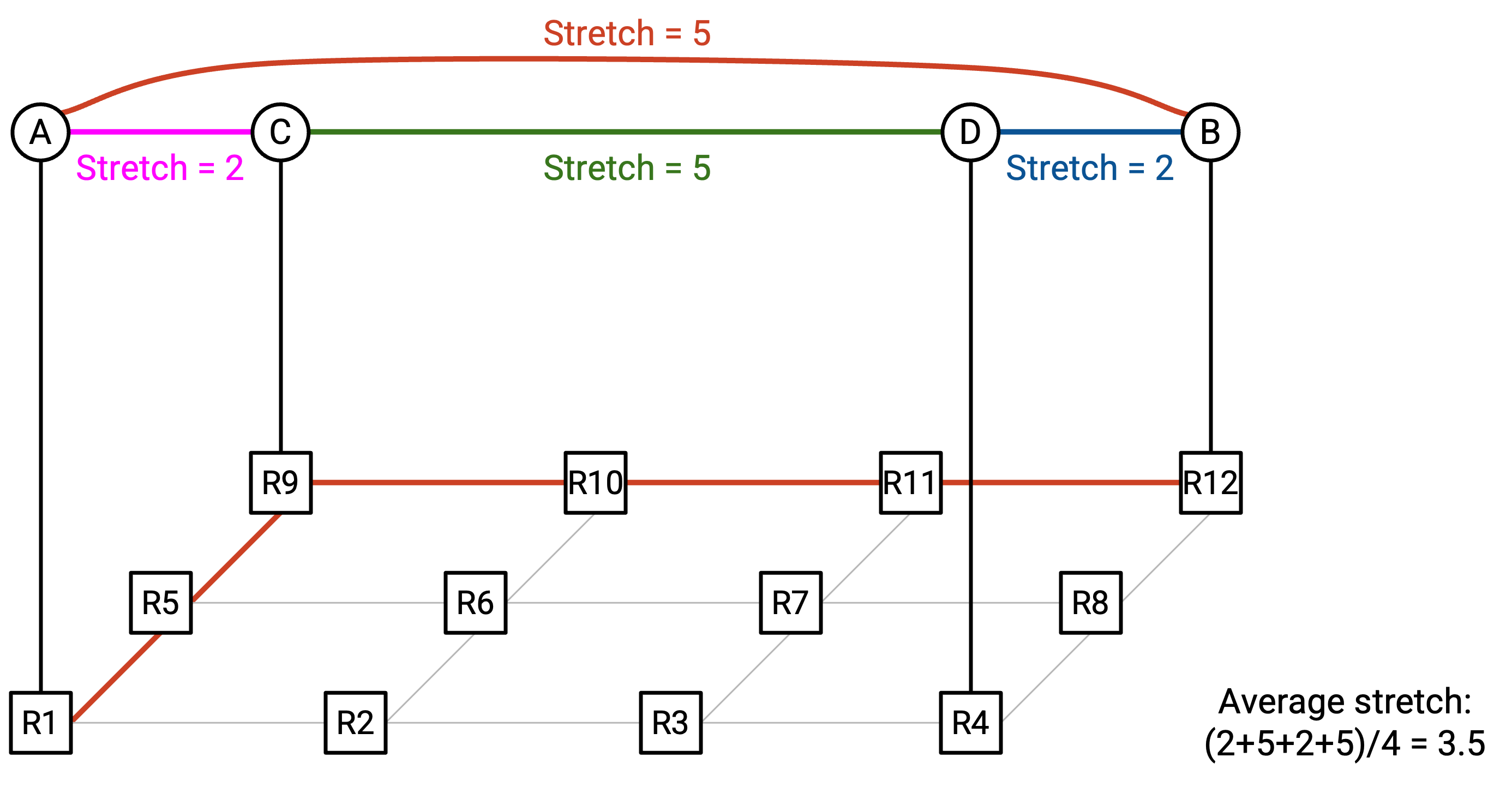
为了展示 overlay topology 为什么重要,假设 4 个 node 想运行 AllReduce operation。我们应该如何给 node 编号,才能实现最佳性能?
首先,注意任意 node 编号方式都会产生正确的 AllReduce 结果。换句话说,任意 node 都可以是 Node 1,任意 node 都可以是 Node 2,依此类推。(这并不对所有 collective operation 都成立,但对 AllReduce 成立。)
下面是两种可能的 node 编号方式:
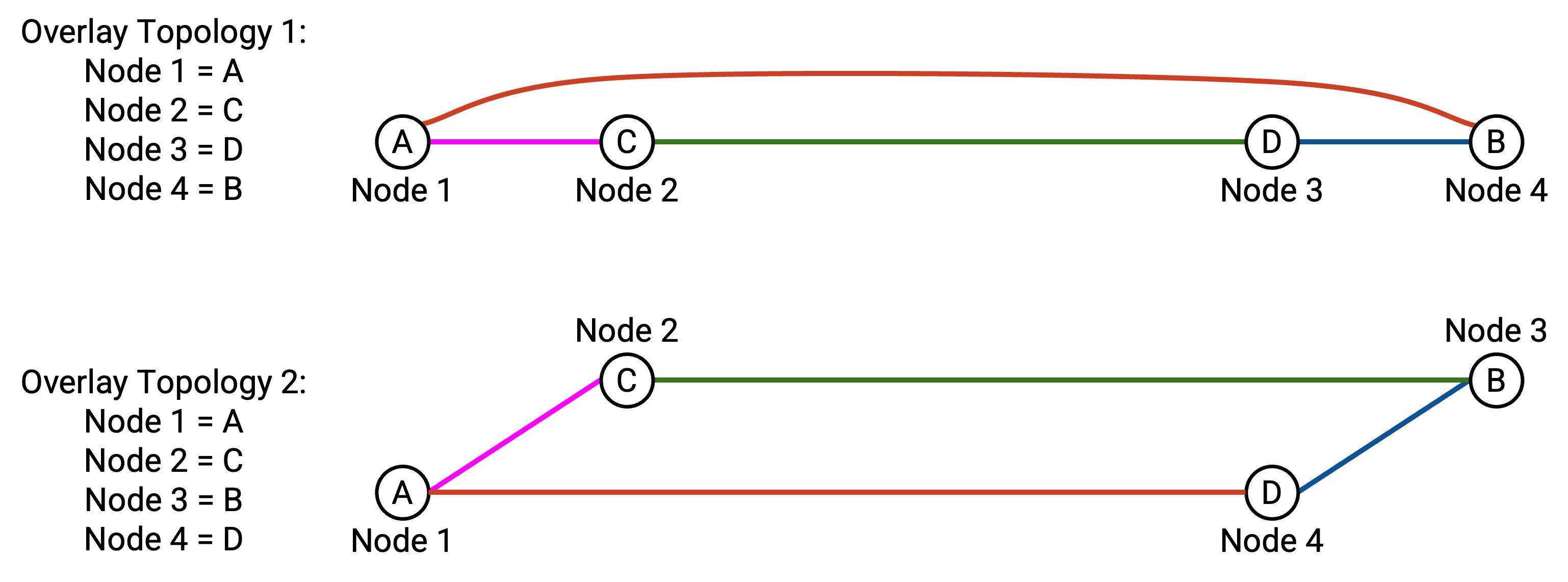
第一种方法的 average stretch 是 3.5。特别要注意,C-to-D 和 B-to-A 这两条 virtual link 需要穿过 underlay network 中许多 link。
相比之下,第二种方法的 average stretch 是 2.5。这组 virtual link 让 ring 中相邻 link 在 network 中更接近。
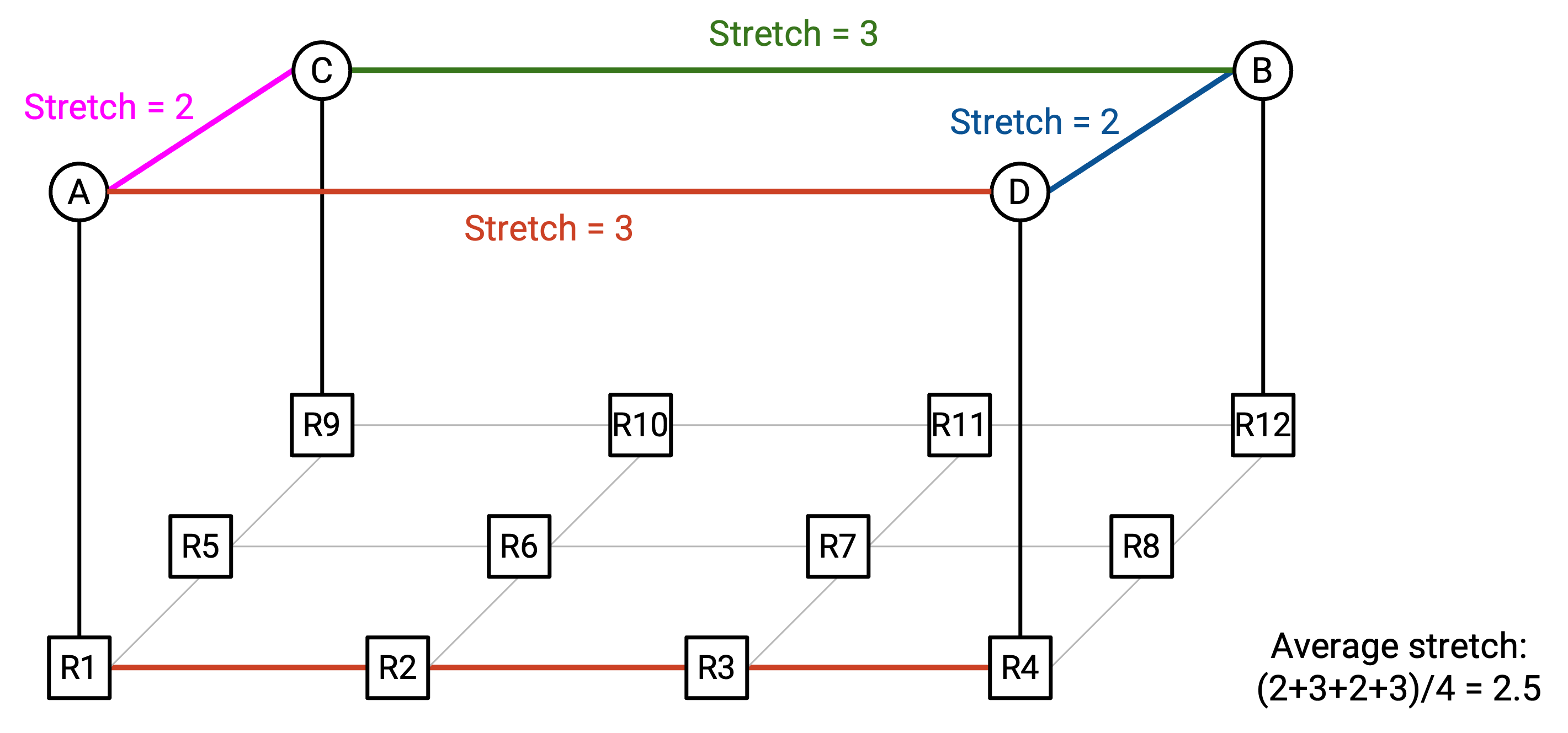
更一般地说,为了优化 ring-based AllReduce 的性能,我们希望相邻 node(例如 Node \(i\) 和 Node \(i+1\))在 network 中彼此接近。
这张图展示的是任意 underlay network topology,但同样的思想也适用于我们用于 AI training 的高度结构化、类似 datacenter 的 topology。回忆一下,在这些类似 datacenter 的 topology 中,有些 node 拥有非常高性能的 connection(例如同一台 machine 上的两个 GPU),而另一些 node 的 connection 性能较差(例如不同 rack 上的两个 GPU)。
AI training job 是可预测的,底层 topology 是固定且规则的。这意味着我们有许多机会优化 training job 的性能。例如,我们可以把特定 job 分配给特定 node,让 collective operation 在彼此接近的 node 上执行(例如所有 node 都在同一 rack 中)。寻找优化 AI training job 的方法仍然是一个活跃研究领域。
抽象层次¶
总结一下,可以从 collective operation 的三个抽象层次来思考:
-
Definition。在最高抽象层,我们通过指定 input 和 expected output 来定义 operation。user 只需要理解这些 definition 就能使用 collective。user 不需要知道 operation 是如何实现的。
-
Overlay。向下一个抽象层,我们可以思考在 overlay topology 中交换哪些 data。在这个层次,你可以假设 node 被组织成一种有用的 topology(例如 tree 或 ring),并且可以沿着这个 topology 中的 virtual link 发送 data。
-
Underlay。在最低抽象层,我们思考 virtual link(overlay)如何对应 underlay 中真实的 physical link。当 Node 5 向 Node 4 发送 vector 时,这个 vector 实际上必须穿过多个 physical router 和 link 被转发。